
思路: 一定要记住典型的垃圾收集器,尤其cms和G1,它们的原理与区别,涉及的垃圾回收算法。
我的答案:
1)几种垃圾收集器:
-
Serial收集器: 单线程的收集器,收集垃圾时,必须stop the world,使用复制算法。
-
ParNew收集器: Serial收集器的多线程版本,也需要stop the world,复制算法。
-
Parallel Scavenge收集器: 新生代收集器,复制算法的收集器,并发的多线程收集器,目标是达到一个可控的吞吐量。如果虚拟机总共运行100分钟,其中垃圾花掉1分钟,吞吐量就是99%。
-
Serial Old收集器: 是Serial收集器的老年代版本,单线程收集器,使用标记整理算法。
-
Parallel Old收集器: 是Parallel Scavenge收集器的老年代版本,使用多线程,标记-整理算法。
-
CMS(Concurrent Mark Sweep) 收集器: 是一种以获得最短回收停顿时间为目标的收集器,标记清除算法,运作过程:初始标记,并发标记,重新标记,并发清除,收集结束会产生大量空间碎片。
- G1收集器: 标记整理算法实现,运作流程主要包括以下:初始标记,并发标记,最终标记,筛选标记。不会产生空间碎片,可以精确地控制停顿。
2)CMS收集器和G1收集器的区别:
-
CMS收集器是老年代的收集器,可以配合新生代的Serial和ParNew收集器一起使用;
-
G1收集器收集范围是老年代和新生代,不需要结合其他收集器使用;
-
CMS收集器以最小的停顿时间为目标的收集器;
-
G1收集器可预测垃圾回收的停顿时间
-
CMS收集器是使用“标记-清除”算法进行的垃圾回收,容易产生内存碎片
- G1收集器使用的是“标记-整理”算法,进行了空间整合,降低了内存空间碎片。
6.JVM内存模型的相关知识了解多少,比如重排序,内存屏障,happen-before,主内存,工作内存。
思路: 先画出Java内存模型图,结合例子volatile ,说明什么是重排序,内存屏障,最好能给面试官写以下demo说明。
我的答案:
1)Java内存模型图:

Java内存模型规定了所有的变量都存储在主内存中,每条线程还有自己的工作内存,线程的工作内存中保存了该线程中是用到的变量的主内存副本拷贝,线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存。不同的线程之间也无法直接访问对方工作内存中的变量,线程间变量的传递均需要自己的工作内存和主存之间进行数据同步进行。
2)指令重排序。
在这里,先看一段代码
public class PossibleReordering {
static int x = 0, y = 0;
static int a = 0, b = 0;
public static void main(String[] args) throws InterruptedException {
Thread one = new Thread(new Runnable() {
public void run() {
a = 1;
x = b;
}
});
Thread other = new Thread(new Runnable() {
public void run() {
b = 1;
y = a;
}
});
one.start();other.start();
one.join();other.join();
System.out.println(“(” + x + “,” + y + “)”);
}
运行结果可能为(1,0)、(0,1)或(1,1),也可能是(0,0)。因为,在实际运行时,代码指令可能并不是严格按照代码语句顺序执行的。大多数现代微处理器都会采用将指令乱序执行(out-of-order execution,简称OoOE或OOE)的方法,在条件允许的情况下,直接运行当前有能力立即执行的后续指令,避开获取下一条指令所需数据时造成的等待3。通过乱序执行的技术,处理器可以大大提高执行效率。而这就是指令重排。
3)内存屏障
内存屏障,也叫内存栅栏,是一种CPU指令,用于控制特定条件下的重排序和内存可见性问题。
-
LoadLoad屏障:对于这样的语句Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
-
StoreStore屏障:对于这样的语句Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
-
LoadStore屏障:对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
- StoreLoad屏障:对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。它的开销是四种屏障中最大的。 在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能。
4)happen-before原则
-
单线程happen-before原则:在同一个线程中,书写在前面的操作happen-before后面的操作。 锁的happen-before原则:同一个锁的unlock操作happen-before此锁的lock操作。
-
volatile的happen-before原则:对一个volatile变量的写操作happen-before对此变量的任意操作(当然也包括写操作了)。
-
happen-before的传递性原则:如果A操作 happen-before B操作,B操作happen-before C操作,那么A操作happen-before C操作。
-
线程启动的happen-before原则:同一个线程的start方法happen-before此线程的其它方法。
-
线程中断的happen-before原则 :对线程interrupt方法的调用happen-before被中断线程的检测到中断发送的代码。
-
线程终结的happen-before原则: 线程中的所有操作都happen-before线程的终止检测。
- 对象创建的happen-before原则: 一个对象的初始化完成先于他的finalize方法调用。
7.简单说说你了解的类加载器,可以打破双亲委派么,怎么打破。
思路: 先说明一下什么是类加载器,可以给面试官画个图,再说一下类加载器存在的意义,说一下双亲委派模型,最后阐述怎么打破双亲委派模型。
我的答案:
1) 什么是类加载器?
类加载器 就是根据指定全限定名称将class文件加载到JVM内存,转为Class对象。
启动类加载器(Bootstrap ClassLoader):由C++语言实现(针对HotSpot),负责将存放在<JAVA_HOME>/lib目录或-Xbootclasspath参数指定的路径中的类库加载到内存中。
- 其他类加载器:由Java语言实现,继承自抽象类ClassLoader。如:
扩展类加载器(Extension ClassLoader):负责加载<JAVA_HOME>/lib/ext目录或java.ext.dirs系统变量指定的路径中的所有类库。
- 应用程序类加载器(Application ClassLoader)。负责加载用户类路径(classpath)上的指定类库,我们可以直接使用这个类加载器。一般情况,如果我们没有自定义类加载器默认就是用这个加载器。
2)双亲委派模型
双亲委派模型工作过程是:
如果一个类加载器收到类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器完成。每个类加载器都是如此,只有当父加载器在自己的搜索范围内找不到指定的类时(即ClassNotFoundException),子加载器才会尝试自己去加载。
双亲委派模型图:

3)为什么需要双亲委派模型?
在这里,先想一下,如果没有双亲委派,那么用户是不是可以自己定义一个java.lang.Object的同名类,java.lang.String的同名类,并把它放到ClassPath中,那么类之间的比较结果及类的唯一性将无法保证,因此,为什么需要双亲委派模型?防止内存中出现多份同样的字节码
4)怎么打破双亲委派模型?
打破双亲委派机制则不仅要继承ClassLoader类,还要重写loadClass和findClass方法。
8.说说你知道的几种主要的JVM参数
思路: 可以说一下堆栈配置相关的,垃圾收集器相关的,还有一下辅助信息相关的。
我的答案:
1)堆栈配置相关
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k
-XX:MaxPermSize=16m -XX:NewRatio=4 -XX:SurvivorRatio=4 -XX:MaxTenuringThreshold=0
-Xmx3550m: 最大堆大小为3550m。
-Xms3550m: 设置初始堆大小为3550m。
-Xmn2g: 设置年轻代大小为2g。
-Xss128k: 每个线程的堆栈大小为128k。
-XX:MaxPermSize: 设置持久代大小为16m
-XX:NewRatio=4: 设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代)。
-XX:SurvivorRatio=4: 设置年轻代中Eden区与Survivor区的大小比值。设置为4,则两个Survivor区与一个Eden区的比值为2:4,一个Survivor区占整个年轻代的1/6
-XX:MaxTenuringThreshold=0: 设置垃圾最大年龄。如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代。
2)垃圾收集器相关
-XX:+UseParallelGC
-XX:ParallelGCThreads=20
-XX:+UseConcMarkSweepGC
-XX:CMSFullGCsBeforeCompaction=5
-XX:+UseCMSCompactAtFullCollection:
-XX:+UseParallelGC: 选择垃圾收集器为并行收集器。
-XX:ParallelGCThreads=20: 配置并行收集器的线程数
-XX:+UseConcMarkSweepGC: 设置年老代为并发收集。
-XX:CMSFullGCsBeforeCompaction:由于并发收集器不对内存空间进行压缩、整理,所以运行一段时间以后会产生“碎片”,使得运行效率降低。此值设置运行多少次GC以后对内存空间进行压缩、整理。
-XX:+UseCMSCompactAtFullCollection: 打开对年老代的压缩。可能会影响性能,但是可以消除碎片
3)辅助信息相关
-XX:+PrintGC
-XX:+PrintGCDetails
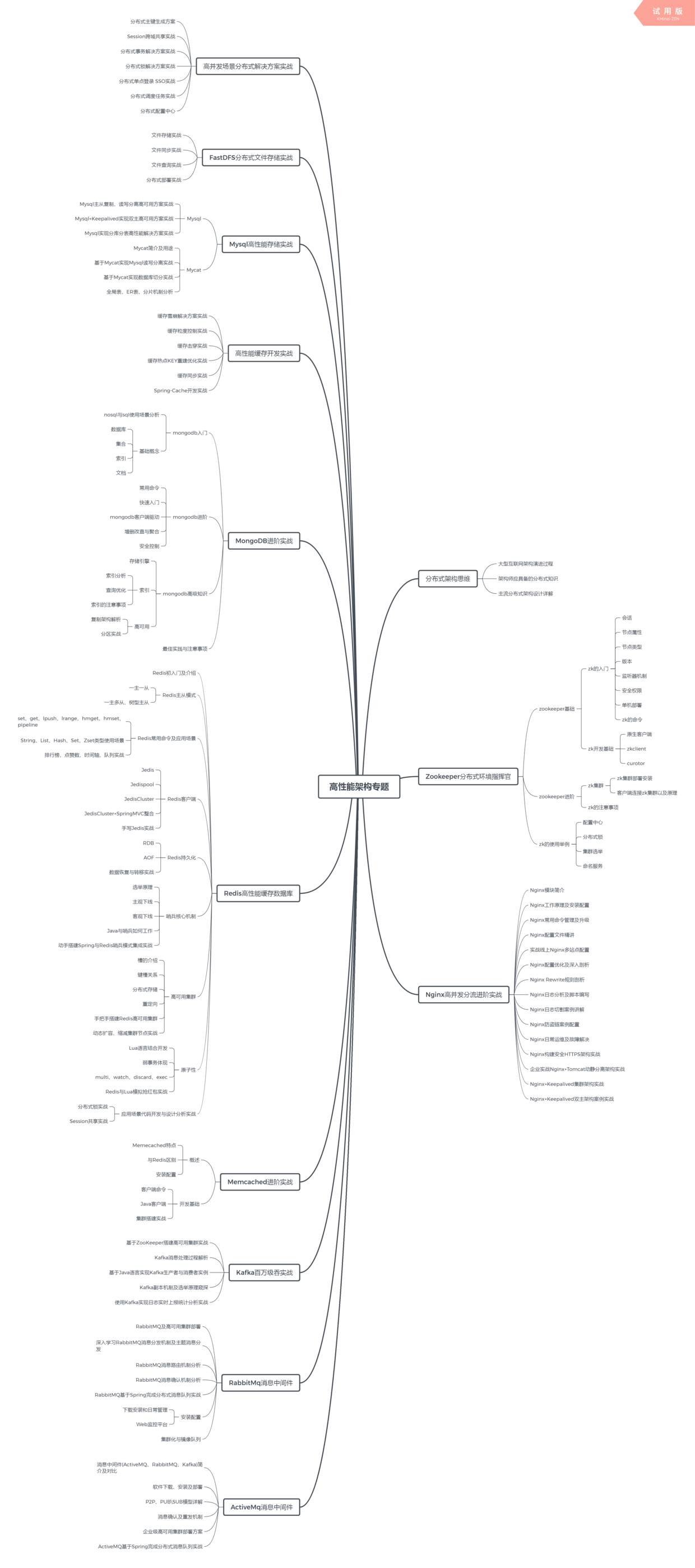
最近我根据上述的技术体系图搜集了几十套腾讯、头条、阿里、美团等公司21年的面试题,把技术点整理成了视频(实际上比预期多花了不少精力),包含知识脉络 + 诸多细节,由于篇幅有限,这里以图片的形式给大家展示一部分
**[CodeChina开源项目:【一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频】](https://ali1024.coding.net/public/P7/Java/git)**
原创文章,作者:ItWorker,如若转载,请注明出处:https://blog.ytso.com/164830.html