2025
DeepSeek-V3.1-GGUF 1-bit~16-bit 对比和选择
核心定义与背景 DeepSeek-V3.1 基础模型 总参数…
核心定义与背景 DeepSeek-V3.1 基础模型 总参数…
1. 什么是模型量化 模型量化是将高精度的模型(通常为 32…
如何在银河麒麟使用DeepSeek? 最近国内AI大模型De…
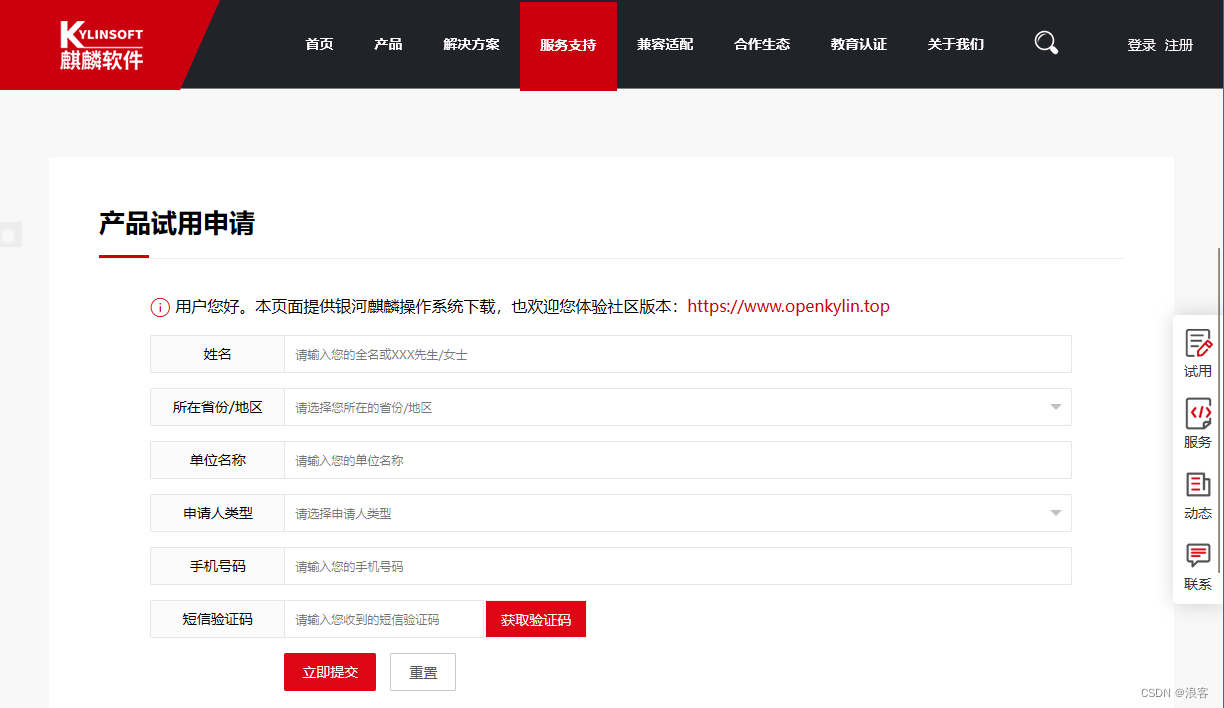
1、下载安装镜像 1.1 申请试用 银河麒麟官网提供免费试用…
国内访问 GitHub 有时会遇到速度慢或不稳定的情况,这时…
一、介绍 目前,开源大小模型较多,在实际应用过程中遇到调试和…

面向未来的数据分析建议 战略规划假设能够帮助您识别、理解和规…
10分钟速览superpower+gstack实践 R…
gstack 最佳实战:23 个 AI 技能,7 步工作流,…
安装包、工具与相关资源见文末 相关资源下载合集。 Claud…
AWS monitoring and integration…
1 SysML定义 背景: 一直以来,系统工程师在进行模型系…
零基础入门:图解 SysML v2 与 Visual Par…
欢迎来到 IBM Rational Rhapsody 的简单…
Rhapsody — MBSE 开发工具 Rhapsody是…
Some more of my notes from Tho…
LLMs generate code incredibly …
Every time I want to format a …