
HA(high availability)
HA 使用的是分布式日志管理方式
1. 问题
Namenode出现问题,整个集群将不能使用。
配置两个namenode:Active namenode,standby namenode
2. 实现方式
1. 两个namenode内存中存储的元数据同步,namenode启动时,会读镜像文件。
2. 编辑日志的安全
分布式的存储日志文件,存储于2n+1奇数个节点。(n个节点写入成功,日志写入成功。)
Zookeeper监控
监控两个namenode,一个namenode出现问题,实现故障转移。
Zookeeper对时间同步要求较高(ntp时间同步)
3. 客户端如何知道访问哪一个namenode
使用proxy代理
隔离机制
使用sshfence
两个namenode之间无密码登陆
安装配置
1. 基础环境配置| node1 | node2 | node3 | node1 | node2 |
|---|---|---|---|---|
| 192.168.103.26 | 192.168.103.27 | 192.168.103.28 | 192.168.103.29 | 192.168.103.30 |
| namenode | namenode | datanode | datanode | datanode |
| DFSZKFailoverController | DFSZKFailoverController | journalnode | journalnode | journalnode |
| QuorumPeerMain | QuorumPeerMain | QuorumPeerMain |
配置主机名与IP之间的映射
vim /etc/hosts
192.168.103.26 node1
192.168.103.27 node2
192.168.103.28 node3
192.168.103.29 node4
192.168.103.30 node5
配置各个节点之间的免密登陆
Node1
ssh-kengen –t rsa –P ‘’ 在~/.ssh/目录下生成id_rsa, id_rsa.put密钥
ssh-copy-id –I ~/.ssh/id._rsa.pub (node1,node2,node3,node4.node5)
Node2操作同node1
配置时间同步,node1作为ntp服务器
1. yum install ntp –y (所有节点)
2. node1
vim /etc/ntp.conf
server 210.72.145.44 # 中国国家受时中心
server 127.127.1.0 #为局域网用户提供服务
fudge 127.127.1.0 stratum 10
systemctl start ntpd
3.node2,node3,node4,node5
ntpdate node1
2. 安装hadoop
1. tar –zxvf jdk-8u171-linux-x64.tar.gz –C /
mv jdk1.8.0_171/ jdk
tar –zxvf hadoop-2.7.7.tar.gz –C /
mv hadoop-2.7.7/ Hadoop
tar –zxvf zookeeper-3.4.10.tar.gz –C /
mv zookeeper-3.4.10 zookeeper
3. vim /etc/profile
export JAVA_HOME=/jdk
export HADOOP_HOME=/Hadoop
export ZOOKEEPER_HOME=/zookeeper
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin
source /etc/profile
scp /etc/profile node2:/etc/
node3,node4,node5
scp –r /jdk node2:/etc
node3,node4,node5
4. 配置zookeeper
进入zookeeper目录,创建zkdata目录
创建myid文件,node3,node4,node5文件中的值为1,2,3
scp –r /zookeeper node2:/etc
node3,node4,node5
分别修改zookeeper节点的myid文件
5. 安装hadoop(重点!!!)
1. hadoop-env.sh
export JAVA_HOME = /jdk
2. core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node3:2181,node4:2181,node5:2181</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/tmp</value>
</property>
</configuration>
3. hdfs.site.xml
<configuration>
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>node1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>node2:8020</value>
</property>
<property>
<name>dfs.ha.namenode.http-address.ns1.nn1</name>
<value>node1:50070</value>
</property>
<property>
<name>dfs.ha.namenode.http-address.ns1.nn2</name>
<value>node2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node3:8485;node4:8485;node5:8485/ns1</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/journalnode</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
vim slaves
node3
node4
node5
4. 启动
node3,node4,node5
hadoop-daemon.sh start journalnode
zkServer.sh start
node1
hdfs namenode -format
scp –r /Hadoop/tmp node2:/Hadoop/
hdfs zkfc –formatZK
start-dfs.sh
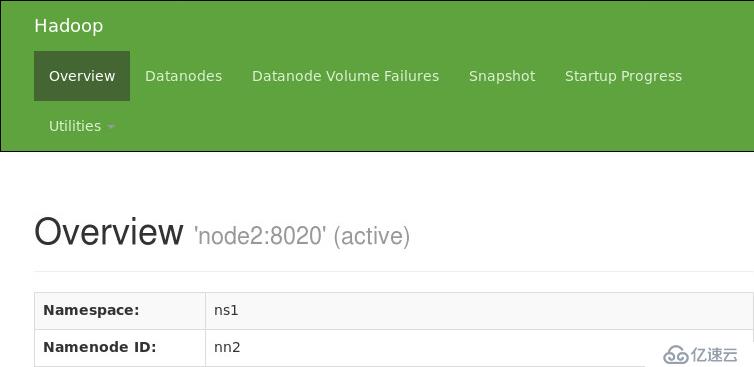
5. 验证HDFS HA
通过浏览器查看node1与node2 namenode状态
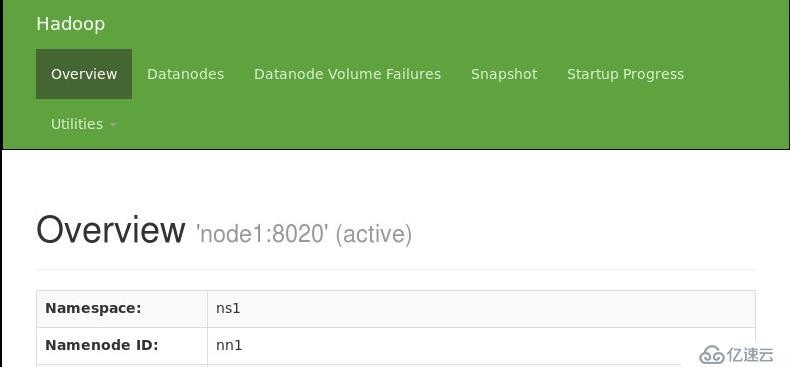
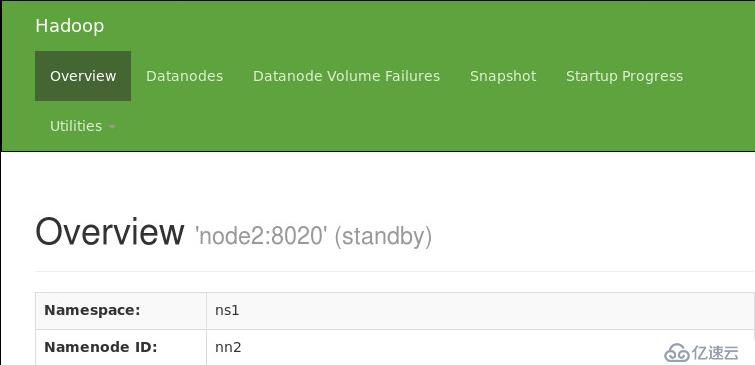
hadoop-daemon.sh stop namenode
原创文章,作者:ItWorker,如若转载,请注明出处:https://blog.ytso.com/196818.html