
《娜璋带你读论文》系列主要是督促自己阅读优秀论文及听取学术讲座,并分享给大家,希望您喜欢。由于作者的英文水平和学术能力不高,需要不断提升,所以还请大家批评指正,非常欢迎大家给我留言评论,学术路上期待与您前行,加油~
最近准备挤时间好好阅读论文并撰写相关论文,这篇博客是在B站学习“深度之眼”Pvop老师的分享,题目为《高手是怎样学习NLP》,这里非常推荐大家去原网站学习及购买课程,真的挺好的一个教程。秀璋也希望能与您一起在学术科研路上一起前行,博士路漫漫,加油~

前文赏析:
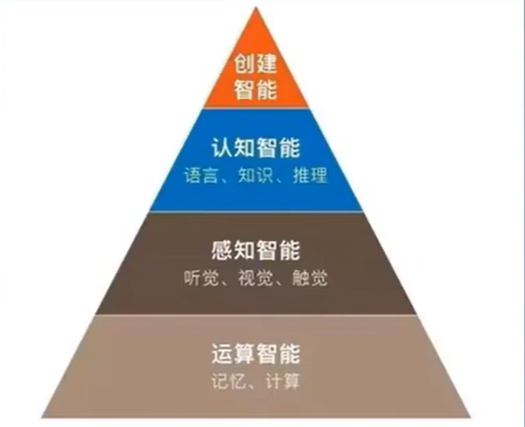
在讲为什么要学习自然语言处理之前(Why should we learn NLP),大家可能都会看到一句话“NLP是人工智能皇冠上的明珠”。下图将人工智能分成了四个层次,从下往上越来越复杂。自然语言处理能作为语言沟通,并且能从大规模文本数据中提取信息。
- 运算智能:计算机CPU/GPU运算速度,最基础底层
- 感知智能:主要包括听觉、视觉和触觉,涉及语音识别、图像识别、CV领域
- 认知智能:主要包括语言、知识和推理,自然语言是人类区别动物,语言体现了智能
- 创建智能:构建机器人拥有人类的情感,与人类沟通
1.作为语言沟通的目的
这个目的主要讲智能对话和机器翻译两个内容。
- 智能对话
智能客服、智能音箱 - 机器翻译
同声传译、文本翻译
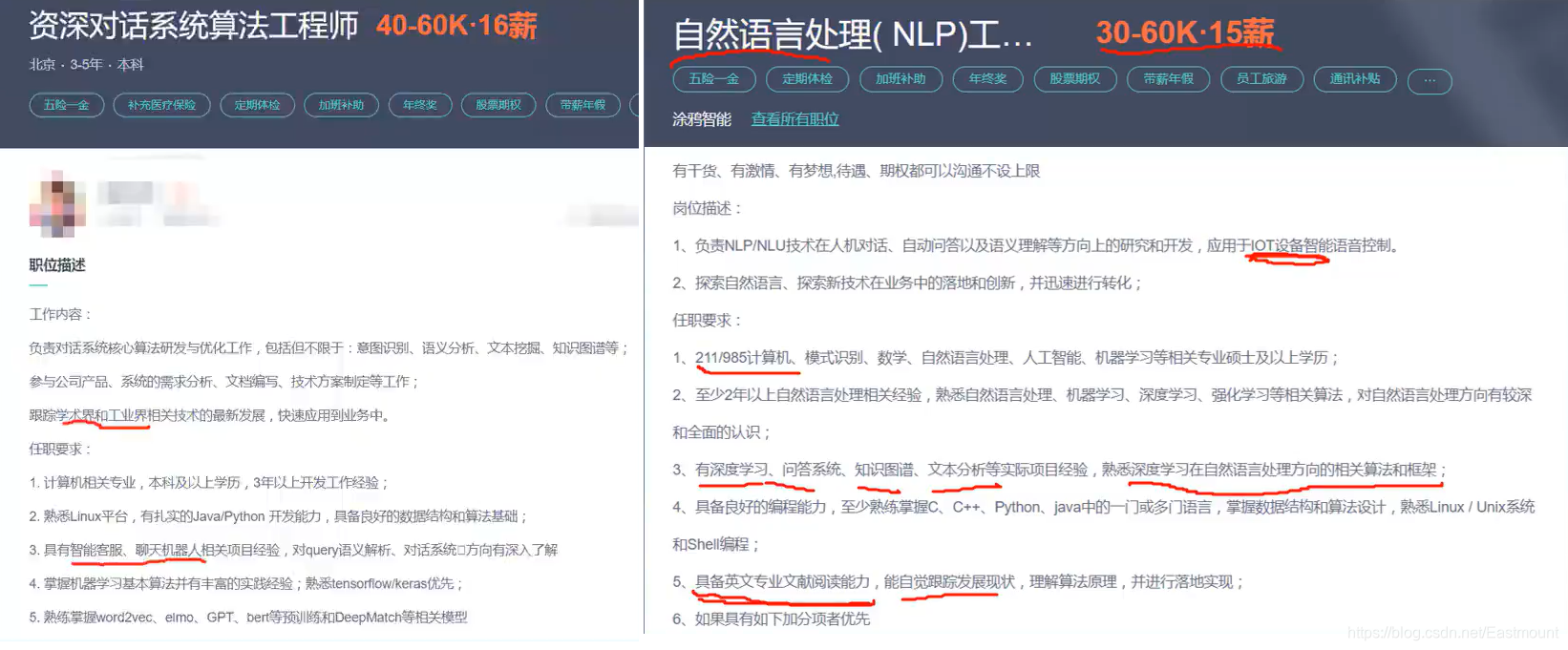
比如下图是一张招聘NLP算法工程师的信息,他需要具备跟踪学术界和工业界最新进展,因为新技术更新非常快,所以学术界论文是非常重要的。同时需要具有query语义解析、tensorflow/keras、word2vec、GPT、bert、DeepMatch等知识。如果你有CCF A会议(如ACL/AAAI)的论文,很多大厂都会招聘,月薪也非常高。
2.从大规模文本数据中提取信息
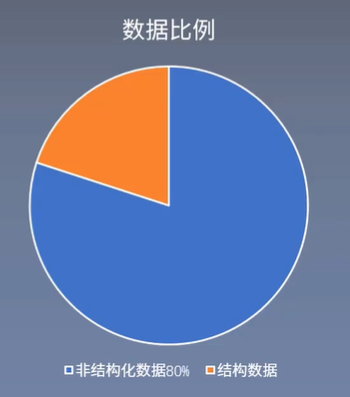
数据通常分为结构化数据和非结构化数据,如下:
- 结构化数据:数据库、日期、电话号码等
- 非结构化数据:文本、电子邮件、社交媒体等
非结构数据中包含海量的待挖掘信息,从大规模文本数据中提取信息衍生出以下任务:
- 机器阅读理解:给你一篇文章和一个问题,从文章中找答案,和英文阅读理解类似。比如从文章中搜索“姚明”的出生年月信息。
- 信息抽取:将新闻从非结构化数据转换为结构化数据,比如时间、地点、人物、事件等。
- 舆情分析:比如通过微博挖掘发现大众的舆论情感倾向,再如公关公司研究艺人的评价等。
- 文本分类:比如将新闻分为体育类别或时尚类别,垃圾邮件识别分类等。
- …
那么,为什么要通过读论文的方式学习自然语言处理呢?
- 技术发展日新月异,通过论文可以获得最前沿的技术。
- 论文可以获得一手的知识。
- 熟读唐诗三百首,不会作诗也会吟。
- 复现论文也可以提高编程能力,算法工程师包括理论水平和工程能力。编程能力够用就行,好的idea能复现及实现自己的想法。
- …
为什么要读基础论文(baseline paper)呢?
下面总结了自然语言基础,最基础的三个方向如下:
- 词向量
现在自然语言处理都是基于神经网络的,神经网络需要的输入是数,所以需要将词映射成数进行输入,这就是词向量的作用,而one-hot的维度太大较稀疏,并且词向量具有语义信息。 - 序列生成Seq2Seq
序列生成任务比如对话生成回复,智能音箱生成序列等,也叫Seq2Seq任务,能够生成一些漂亮的句子才认为你是智能,你一直做分类别人任务是统计的方法。 - 注意力机制
Attention是从很多信息中找到重要的信息。
同时文本分类和机器翻译是两个重要的任务,其中textcnn和chartextcnn论文是纯文本分类任务,fasttext是词向量相关的,HAN是attention相关的,SGM是序列生成做多标签文本分类。机器翻译主要介绍两个经典的模型,即Deep LSTM和Bahdanau NMT。

这里的发展历程主要结合Baseline论文进行讲解的。
1.2003年NNLM神经网络语言模型提出
- 传统方法:通过统计n-grams来学习语言模型
- NNLM:通过深度学习的方式自动学习一个语言模型,并且和n-grams模型的效果相当,第一篇将词映射成向量的论文

2.2013年Word2Vec模型
之前的词向量学习速度太慢,训练时间太长,无法在大规模语料进行训练,所以效果较差。2013年Google提出Word2Vec模型,通过加快词向量的训练,实现在大规模语料上训练得到非常好的词向量,极大推动了自然语言处理的发展。Word2Vec在NLP领域的重要性类似于AlexNet在CV领域的重要性,真的很关键。
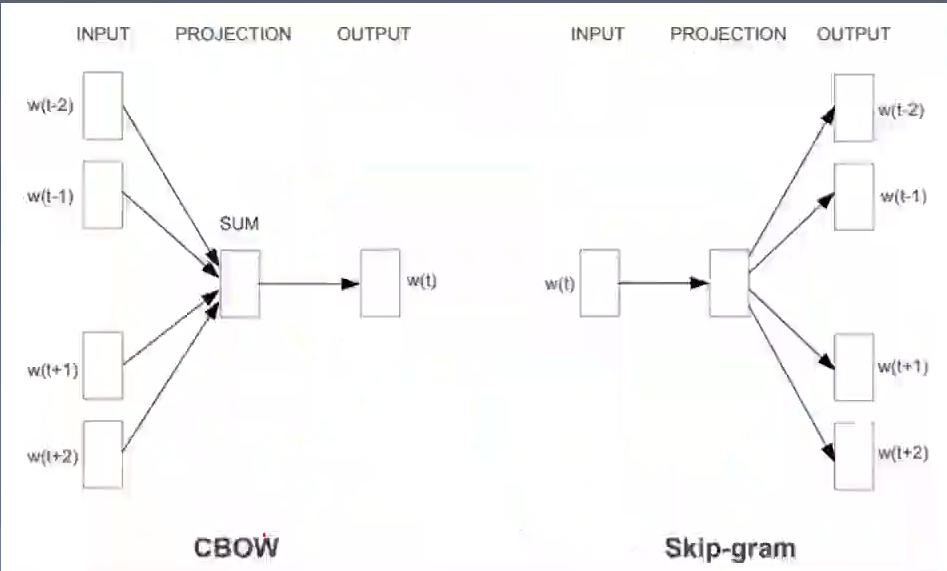
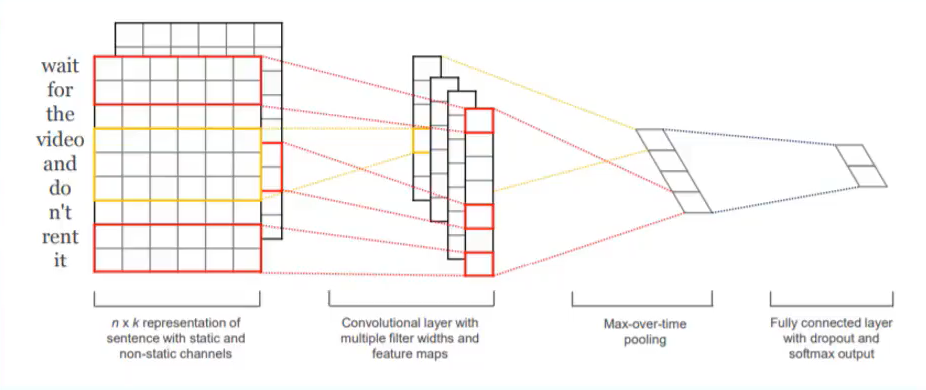
3.2014年TextCNN模型
之前文本分类模型较为复杂,效果一般。TextCNN模型非常简单,但效果非常好,包括卷积层、池化层和全连接层组成,卷积层 kernel_sizes=(2,3,4)。为什么效果好呢?因为它使用Word2Vec,通过使用预训练的词向量在简单的CNN模型上取得了非常好的效果。
Yoon Kim在论文(2014 EMNLP) Convolutional Neural Networks for Sentence Classification提出TextCNN。
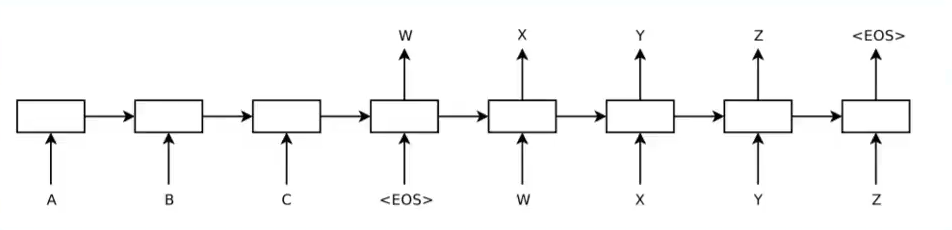
4.2014年Deep NMT模型
之前的统计机器翻译包含复杂的规则和统计方法,神经机器翻译通过神经网络自动训练神经机器翻译模型,包括四层SLTM。2016年,谷歌翻译正式使用神经机器翻译代替统计机器翻译,其负责人表示“这意味着用500行神经网络模型代码取代50万行基于短语的机器翻译代码”。
Ilya Sutskever(Google)在2014 NIPS年发表Sequence to Sequence Learning with Neural Networks。
5.2015年Attention模型
注意力机制是自然语言处理最核心的算法之一,它通过简单的机制能够自动从复杂的信息中选择关键的信息。因为自然语言处理具有海量词汇,而只有某些词汇非常重要,比如情感分类的sad、happy。

1.One-hot表示想分布式表示的发展
- Word2Vec
- Glove
One-hot表示主要采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位。你有多少个词就有多长,所以维度很大且稀疏。分布式表示维度较低,含有语义和语法信息,通过词向量能获取它们的相似度。
- [“中国”, “美国”, “日本”, “美国”] —> [[1,0,0], [0,1,0], [0,0,1], [0,1,0]]

2.机器学习方法往深度学习方法的发展
- TextCNN
- CharTextCNN
- NMT
之前都是基于统计的特征,如n-grams统计文章具有多少短语,每个短语出现多少次,再加上机器学习模型(SVM、LR)预测。深度学习方法是特征工程和模型集成于一体的。

3.大粒度向小粒度发展
- FastText
- CharTextCNN
- C2W
之前都是词级别模型,如Word2Vec、Glove、TextCNN,每个词映射成一个向量,有人就会想“为什么不每个字符映射成一个向量呢?”,或者将前缀、后缀(如pre)映射成向量,就发展了小粒度N-gram模型和字符级别模型。比如paper之前是一个向量,但papers后就不认识了,所以慢慢发展了小粒度模型。

4.简单任务向复杂任务的发展
- NMT
- SGM
复杂任务包括神经机器翻译、多类别文本分类、阅读理解、信息抽取等。

希望大家不要担心基础薄弱或转专业,希望大家扎实学习,从基础理论知识、编程实践(Python+Pytorch)、论文阅读,找idea进行提升。
- 基础知识学习
编程能力、深度学习、自然语言处理基础知识 - Baseline学习
词向量、文本分类、Seq2Seq、Attention - 进阶学习
信息抽取、预训练模型、图神经网络、知识图谱

那么,如何产出论文呢?
想要发CCF A就需要有好的idea,找idea就要大量阅读论文,通过看别人怎么做的以及不足点来发现问题(idea),然后再找解决方法以及调研,调研看看有没有人发过类似的论文。解决问题同样要继续阅读大量论文,反复循环补充新的idea,最后产出论文。
这里补充下Pvop老师的学习路径,真的挺佩服的,自己也需要努力学习,早日发表出自己的A类论文。
Pvop老师最早从文本分类论文开始阅读,发现Google翻译词性存在问题,就想是否能把词性和神经机器翻译结合(词性+NMT),相当于发现了第一个idea。然后就去看神经翻译的文章,发现有别人做过了,这就是论文撞车,然后继续阅读了大约10多篇文章,发现已经有很多人做并形成领域,就不继续做这个工作了。当时也尝试改进了别人的模型,其实idea还是可以的,但当时编程能力比较薄弱,TensorFlow代码提升不高,就没有成文。接着继续看机器翻译的文章,看到机器翻译中增加噪音判断翻译效果,他就想能不能在文本分类或命名实体识别中也增加噪音,就形成了自己的最终idea,最终投递到AAAI上。整个过程因为老师方向不一致,也是他自己去完成的。
自然语言处理三大会议,他们的论文都比较高,虽然有C类的。
- ACL(CCF-A)
- EMNLP(CCF-B)
- NAACL(CCF-C)

基础知识如下图所示:

下面给出了学习路径NLP Baseline论文,推荐大家好好学习下这些基础论文,该领域很多工作都是在他们的基础上进行改进的,它们就是NLP的基石。这里第一篇是介绍Word2Vec的,ICLR虽然不在CCF列表中,但它的影响力非常高,因为它2013年才举办,包括第八篇注意力机制也是该会议。

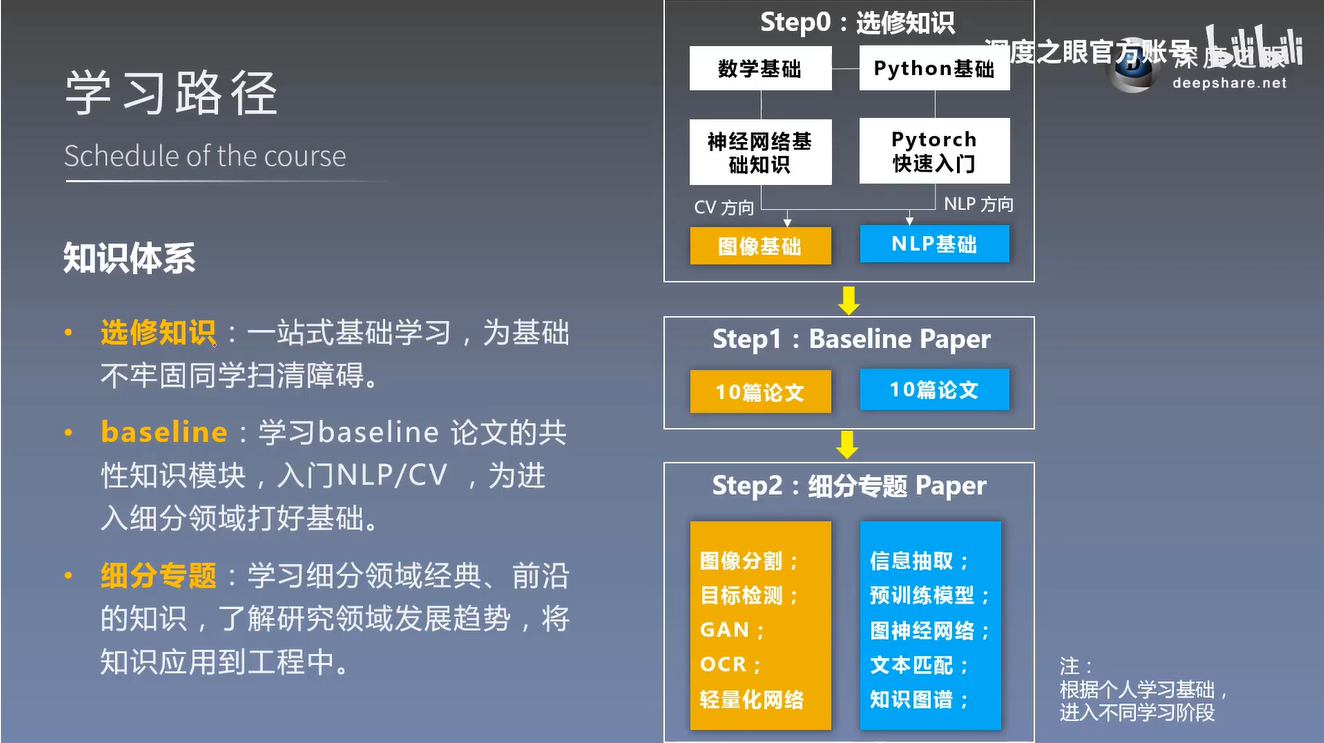
下面给出知识体系,也推荐大家去深度之眼学习他们的课程。
- 选修知识
一站式基础学习,为基础不牢固同学扫清障碍 - baseline
学习baseline论文的共性知识模块,入门NLP/CV,为进入细分领域打好基础 - 细分专题
学习细分领域经典、前沿的知识,了解研究领域发展趋势,将知识应用到工程中
他们的课程安排是一周一篇Paper学习,包括论文和代码复现,感觉挺好的。具体内容如下
- Word2Vec:词向量训练
- Glove:词向量训练
- C2W:词向量训练
- TextCNN:文本分类
- CharTextCNN:文本分类
- FastText:词向量+文本分类
- Deep NMT:Seq2Seq
- Bahdanau NMT:Seq2Seq
- Han Attention:注意力机制
- SGM:序列标注做文本分类

每篇论文的阅读方法如下图所示:
- 导读
储备知识、背景介绍(论文解决什么问题、为什么这么做及研究意义) - 精读
模型精讲、实验分析和讨论、论文总结(关键点、创新点、启发点) - 代码
数据集、基于Pytorch实现、训练和测试

学习收获总结如下:
- 学会理解NLP的关键技术,如词嵌入、预训练、文本分类、Seq2Seq、注意力机制等
- 学会NLP的很多编程知识,如分词、分句、word2id、attention写法等
- 学会如何看懂一篇论文,知道论文的一般结构,做到看论文不慌不忙、重点明确
- 学会论文的一般结构和写作方法,为自己写论文打下基础
- 具有一定独立学习NLP其他文字的能力


合抱之木,生于毫末;九层之台,起于垒土;千里之行,始于足下。
最后希望这篇文章对您有所帮助!

同时我也帮忙宣传下他们的公众号吧,再次感谢深度之眼Pvop老师,加油!

希望能与大家一起在华为云社区共同成长。原文地址:https://blog.csdn.net/Eastmount/article/details/108890639
(By:Eastmount 2021-09-25 晚上12点写于北京)
原创文章,作者:3628473679,如若转载,请注明出处:https://blog.ytso.com/212182.html