
与Oracle相比,PostgreSQL对collation的支持依赖于操作系统。
以下是基于Centos7.5的测试结果
$ env | grep LC $ env | grep LANG LANG=en_US.UTF-8
使用initdb初始化集群的时候,就会使用这些操作系统的配置。
postgres=# /l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+-------------+-------------+-----------------------
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
(4 rows)
postgres=#
在新建数据库的时候,可以指定数据库的默认的callation:
postgres=# create database abce with LC_COLLATE = "en_US.UTF-8"; CREATE DATABASE postgres=# create database abce2 with LC_COLLATE = "de_DE.UTF-8"; ERROR: new collation (de_DE.UTF-8) is incompatible with the collation of the template database (en_US.UTF-8) HINT: Use the same collation as in the template database, or use template0 as template. postgres=#
但是,指定的collation必须是与template库兼容的。或者,使用template0作为模板。
如果想看看操作系统支持哪些collations,可以执行:
$ localectl list-locales
也可以登录postgres后查看:
postgres=# select * from pg_collation ;
补充:POSTGRESQL 自定义排序规则
业务场景
平时我们会遇到某种业务,例如:超市里统计哪一种水果最好卖,并且优先按地区排序,以便下次进货可以多进些货。
这种业务就需要我们使用自定义排序规则(当然可以借助多字段多表实现类似需求,但这里将使用最简单的方法–无需多表和多字段,自定义排序规则即可实现)
创建表
id为数据唯一标识,area为区域,area_code为区域代码,code为水果代码,sale_num为销量,price价格
create table sale_fruit_count (
id INTEGER primary key,
name VARCHAR(50),
code VARCHAR(10),
area VARCHAR(50),
area_code VARCHAR(10),
sale_num INTEGER,
price INTEGER
)
表中插入数据

自定义排序规则
同时依据地区、销售数量排序(地区自定义排序规则)
海南>陕西>四川>云南>新疆 (ps:距离优先原则)
按排序规则查询
如果按照以往排序直接进行area_code排会发现跟我们预期效果不一样:
select * from sale_fruit_count order by area_code, sale_num desc
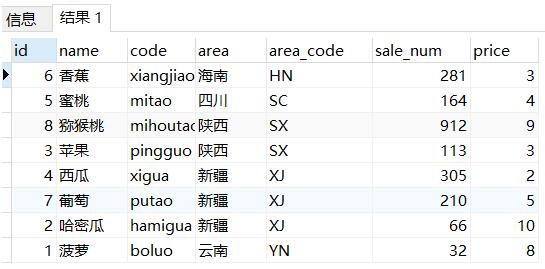
我们看到地域排序是按照字母编码排序的,因此需要改造排序规则:
select *
from sale_fruit_count
order by case area_code
when 'HN' then 1
when 'SX' then 2
when 'SC' then 3
when 'YN' then 4
when 'XJ' then 5
end asc
, sale_num desc
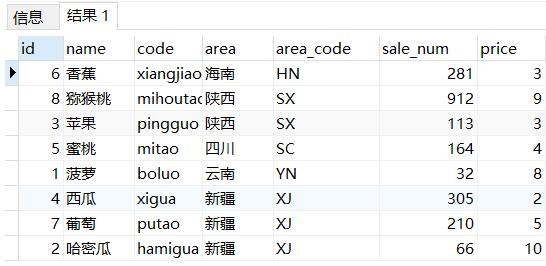
此时即实现了自定义排序。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持云图网。如有错误或未考虑完全的地方,望不吝赐教。
原创文章,作者:254126420,如若转载,请注明出处:https://blog.ytso.com/233012.html