
插入排序是一种最容易理解的排序,我给搓麻将和打牌的大妈都能讲明白。因为,它和打牌一样,每当接到一张牌,我们都选择性的插入到手中已有序的牌中。
插入排序往往会和冒泡排序拿来相比之下,主要原因是,插入排序比冒泡排序更受欢迎!比如,我们把执行一个赋值语句的时间粗略地计为单位时间(unit_time),然后分别用冒泡排序和插入排序对同一个逆序度是 K 的数组进行排序。用冒泡排序,需要k次交换操作,每次需要3个赋值语句,所以交换操作总耗时就是 3*K 单位时间。而插入排序中数据移动操作只需要 K 个单位时间。这也是,很多底层系统宁愿选插入排序也不愿选冒泡排序的原因之一。虽然,冒泡排序不管怎么优化,元素交换的次数是一个固定值,就是原始数据的逆序度。插入排序是同样的,不管怎么优化,元素移动的次数也等于原始数据的逆序度。
插入排序是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常采用 in-place 排序,因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
将有n个元素的数组排序。 最佳情况就是,数组已经是正序排列了,在这种情况下,需要进行的比较操作是(n-1)次即可。 最坏情况就是,数组是反序排列,那么此时需要进行的比较共有n(n-1)/2次。 插入排序的赋值操作是比较操作的次数加上(n-1)次。
以数据结构为数组为例,插入排序的最坏时间复杂度 O(n^2)、最优时间复杂度 O(n)、平均时间复杂度 O(n^2)、最坏空间复杂度总共O(n) ,需要辅助空间 O(1)。
排序过程:
- 从第一个元素开始,该元素可以认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后向前扫描
- 如果该元素(已排序)大于新元素,将该元素移到下一位置
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插入到该位置后
- 重复步骤2~5
插入排序的 Java 案例代码如下所示:
public void insertionSort(int[] array) {
for (int i = 1; i < array.length; i++) {
int key = array[i];
int j = i - 1;
while (j >= 0 && array[j] > key) {
array[j + 1] = array[j];
j--;
}
array[j + 1] = key;
}
}也或者类似下面的这种实现方式:
//将arr[i] 插入到arr[0]...arr[i - 1]中
public static void insertion_sort(int[] arr) {
for (int i = 1; i < arr.length; i++ ) {
int temp = arr[i];
int j = i - 1;
//如果将赋值放到下一行的for循环内, 会导致在第10行出现j未声明的错误
for (j >= 0 && arr[j] > temp; j-- ) {
arr[j + 1] = arr[j];
}
arr[j + 1] = temp;
}
}排序动态效果图如下所示:
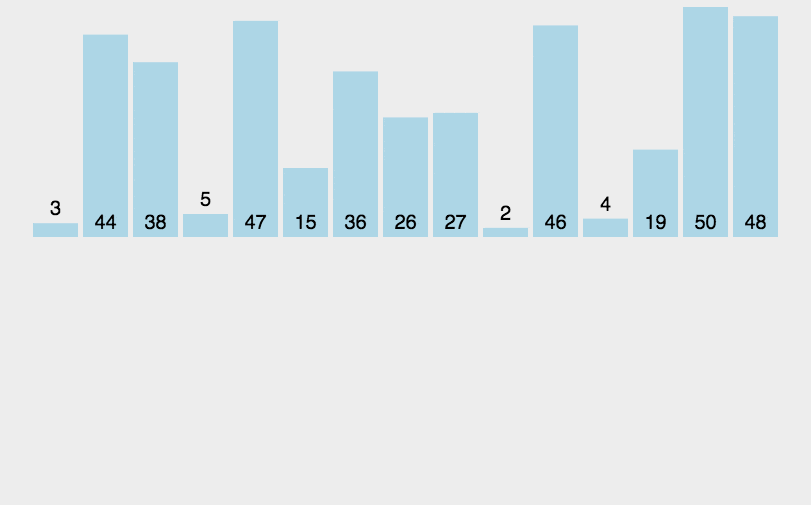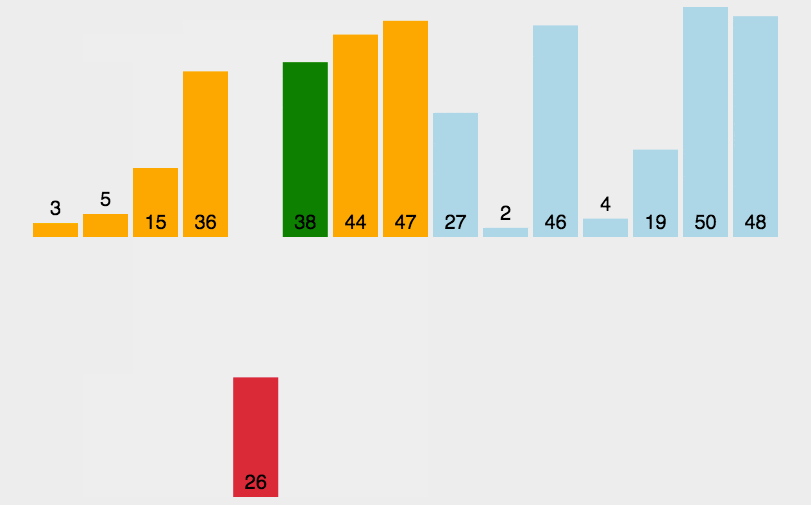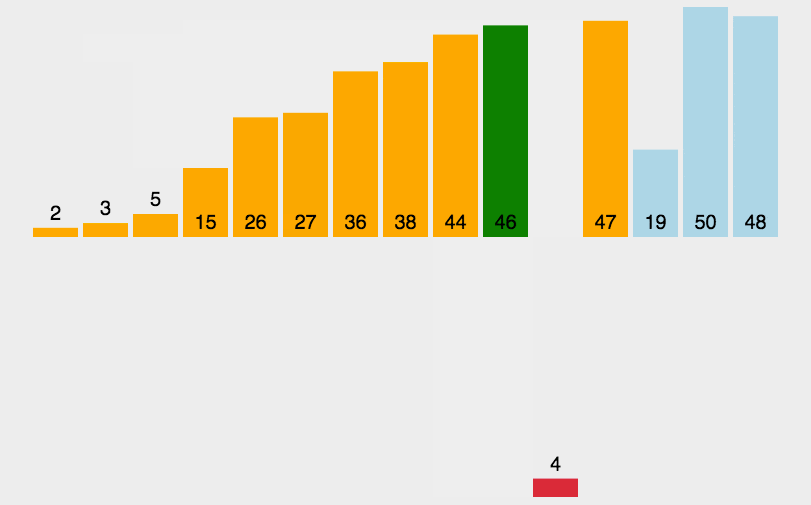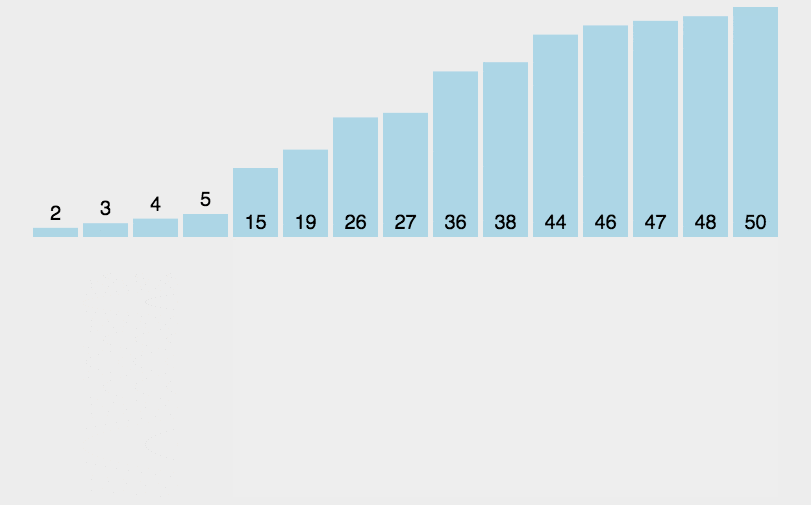
如果目标是把n个元素的序列升序排列,那么采用插入排序存在最好情况和最坏情况。最好情况就是,序列已经是升序排列了,在这种情况下,需要进行的比较操作需 n-1 次即可。最坏情况就是,序列是降序排列,那么此时需要进行的比较共有 n*(n-1)/2 次。插入排序的赋值操作是比较操作的次数减去 n-1 次,(因为 n-1 次循环中,每一次循环的比较都比赋值多一个,多在最后那一次比较并不带来赋值)。平均来说插入排序算法复杂度为 O(n^2)。因而,插入排序不适合对于数据量比较大的排序应用。但是,如果需要排序的数据量很小,例如,量级小于千;或者若已知输入元素大致上按照顺序排列,那么插入排序还是一个不错的选择。 插入排序在工业级库中也有着广泛的应用,在 STL 的 sort 算法和 stdlib 的 qsort 算法中,都将插入排序作为快速排序的补充,用于少量元素的排序(通常为8个或以下)。
插入排序还可以采用二分查找法来减少“比较操作”的数目,这样的算法可以认为是插入排序的一个变种,称为二分查找插入排序。
: » 排序算法之插入排序
原创文章,作者:jamestackk,如若转载,请注明出处:https://blog.ytso.com/252174.html