
线性回归入门
数据生成
为了直观地看到算法的思路,我们先生成一些二维数据来直观展现
import numpy as np |
|
import matplotlib.pyplot as plt |
|
def true_fun(X): # 这是我们设定的真实函数,即ground truth的模型 |
|
return 1.5*X + 0.2 |
|
np.random.seed(0) # 设置随机种子 |
|
n_samples = 30 # 设置采样数据点的个数 |
|
'''生成随机数据作为训练集,并且加一些噪声''' |
|
X_train = np.sort(np.random.rand(n_samples)) |
|
y_train = (true_fun(X_train) + np.random.randn(n_samples) * 0.05).reshape(n_samples,1) |
|
# 训练数据是加上一定的随机噪声的 |
定义模型
我们可以直接点用sklearn中的LinearRegression即可:
from sklearn.linear_model import LinearRegression |
|
model = LinearRegression() # 这就是我们的模型 |
|
model.fit(X_train[:, np.newaxis], y_train) # 训练模型 |
|
print("输出参数w:",model.coef_) |
|
print("输出参数b:",model.intercept_) |
输出参数w: [[1.4474774]] |
|
输出参数b: [0.22557542] |
注意上面代码中的np.newaxis,因为X_train是一个一维的向量,那么其作用就是将X_train变成一个N*1的二维矩阵而已。其实写成X_train[:,None]是相同的效果。
至于为什么要这么做,你可以不这么做试一下,会报错为:
Reshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample. |
可以简单理解为这是sklearn的库对训练数据的要求,不能够是一个一维的向量。
模型测试与比较
可以看到我们输出为1.44和0.22,还是很接近真实答案的,那么我们选取一批测试集来看看精度:
X_test = np.linspace(0,1,100) # 0和1之间,产生100个等间距的 |
|
plt.plot(X_test, model.predict(X_test[:, np.newaxis]), label = "Model") # 将拟合出来的散点画出 |
|
plt.plot(X_test, true_fun(X_test), label = "True function") # 真实结果 |
|
plt.scatter(X_train, y_train) # 画出训练集的点 |
|
plt.legend(loc="best") # 将标签放在最合适的位置 |
|
plt.show() |
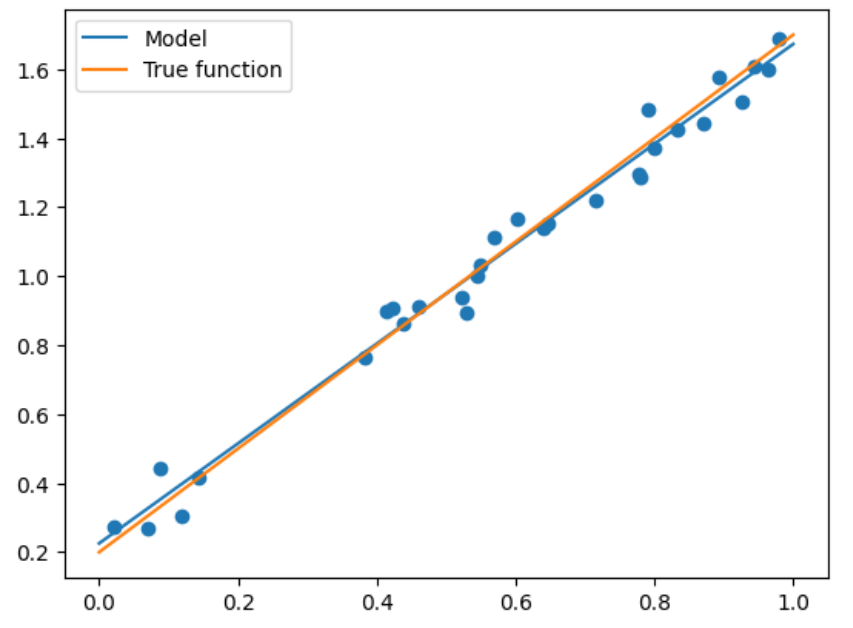
上述情况是最简单的,但当出现更高维度时,我们就需要进行多项式回归才能够满足需求了。
多项式回归
具体实现
对于多项式回归,一般是利用线性回归求解y=∑i=1mbi×xi,因此算法如下:
import numpy as np |
|
import matplotlib.pyplot as plt |
|
from sklearn.pipeline import Pipeline |
|
from sklearn.preprocessing import PolynomialFeatures # 导入能够计算多项式特征的类 |
|
from sklearn.linear_model import LinearRegression |
|
from sklearn.model_selection import cross_val_score # 交叉验证 |
|
def true_fun(X): # 真实函数 |
|
return np.cos(1.5 * np.pi * X) |
|
np.random.seed(0) |
|
n_samples = 30 |
|
X = np.sort(np.random.rand(n_samples)) # 随机采样后排序 |
|
y = true_fun(X) + np.random.randn(n_samples) * 0.1 |
|
degrees = [1, 4, 15] # 多项式最高次,我们分别用1次,4次和15次的多项式来尝试拟合 |
|
plt.figure(figsize=(14, 5)) |
|
for i in range(len(degrees)): |
|
ax = plt.subplot(1, len(degrees), i+1) # 总共三个图,获取第i+1个图的图像柄 |
|
plt.setp(ax, xticks = (), yticks = ()) # 这是 设置ax图中的属性 |
|
polynomial_features = PolynomialFeatures(degree=degrees[i],include_bias=False) |
|
# 建立多项式回归的类,第一个参数就是多项式的最高次数,第二个是是否包含偏置 |
|
linear_regression = LinearRegression() # 线性回归 |
|
pipeline = Pipeline([("polynomial_features", polynomial_features), |
|
("linear_regression", linear_regression)]) # 使用pipline串联模型 |
|
pipeline.fit(X[:, np.newaxis], y) |
|
scores = cross_val_score(pipeline, X[:, np.newaxis], y, scoring="neg_mean_squared_error", cv=10) |
|
# 使用交叉验证,第一个参数为模型,第二个为输入,第三个为标签,第四个为误差计算方式,第五个为多少折 |
|
X_test = np.linspace(0, 1, 100) |
|
plt.plot(X_test, pipeline.predict(X_test[:, np.newaxis]), label="Model") |
|
plt.plot(X_test, true_fun(X_test), label="True function") |
|
plt.scatter(X, y, edgecolor='b', s=20, label="Samples") |
|
plt.xlabel("x") |
|
plt.ylabel("y") |
|
plt.xlim((0, 1)) |
|
plt.ylim((-2, 2)) |
|
plt.legend(loc="best") |
|
plt.title("Degree {}/nMSE = {:.2e}(+/- {:.2e})".format(degrees[i], -scores.mean(), scores.std())) |
|
plt.show() |
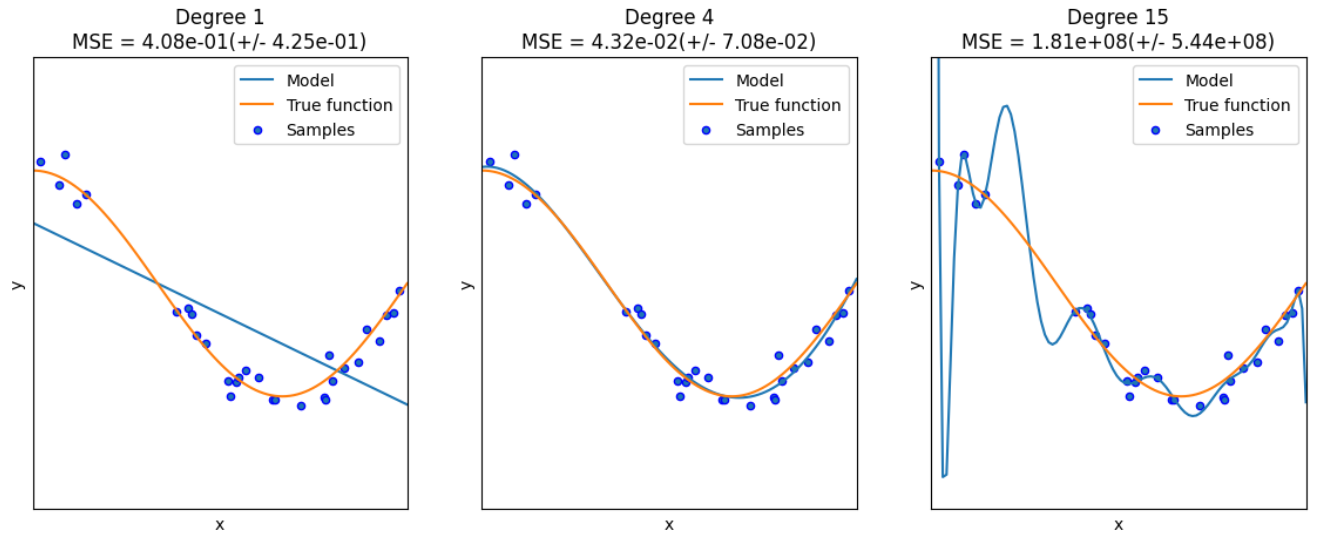
这里解释两个地方:
- PolynomialFeatures:这个类实际上是一个构造特征的类,因为我们原始的X是一个一维的向量,它多项式的次数为1,那我们希望构成一个多项式就需要拿X去计算X1,X2,…,Xm(这是一个变量的情况,如果是多个变量就会计算交叉乘),那么这个类就是实现这样的操作,构造成m个特征
- pipeline:这是方便我们的管道,它将各种模块加在一起让我们不用一步步去计算每一个模块,这里就是将PolynomialFeatures和线性回归模块加在一起,那我们将X传进去之后,就经过特征构造后就进行线性回归,因此拟合管道即可。
在其中我们还用到了交叉验证的思路,这部分很常见就不多做解释了。
LogisticRegression
算法思想简述
对于逻辑回归大部分是面对二分类问题,给定数据,X={x1,x2,…,},Y={y1,y2,…,}
考虑二分类任务,那么其假设函数就是:
hθ(x)=g(θTx)=g(wTx+b)=11+ewTx+b
来表示为类别1或者类别0的概率。
那么其损失函数一般是采用极大似然估计法来定义:
L(θ)=∏i=1p(yi=1∣xi)=hθ(x1)(1−hθ(x))…
这里假设y1=1,y2=0。那么就是该函数最大化,化简可得:
θ∗=argminθ(−L(θ))=argminθ−ln(L(θ))=∑i=1(−yiθTxi+ln(1+eθTxi))
再利用梯度下降即可。
本站声明:
1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享;
2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关;
3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关;
4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除;
5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。
原创文章,作者:ItWorker,如若转载,请注明出处:https://blog.ytso.com/293983.html