
在我们的项目编码中,不可避免的会用到一些容器类,我们可以直接使用List、Map、Set、Array等类型。当然,为了体现业务层面的含义,我们也会根据实际需要自行封装一些专门的Bean类,并在其中封装集合数据来使用。
看下面的一个场景:
在一个企业级的研发项目事务管理系统里面,包含很多的项目,每个项目下面又包含很多的具体需求,而每个需求下面又会被拆分出若干的具体事项。
按照常规思路,我们会怎么去建模呢?为了简化描述,我们仅以项目--需求--任务这个维度来说明下。
首先肯定会去创建Project(项目)、Requirement(需求)、Task(任务)三个类,然后每个类中会包含一个子对象的集合。比如对于Project而言,会包含一个Requirement的集合:
@Data
public class Project {
private List<Requirement> requirements;
private int status;
private String projectName;
// ...
}
同样道理,我们定义Requirement的时候,也会包含一个Task的集合:
@Data
public class Requirement {
private List<Task> tasks;
private int status;
private String requirementName;
private Date createTime;
private Date closeTime;
// ...
}
上述的例子中,Project、Requirement便是两个典型的“容器”,容器中会存储着若干具体的元素对象。对容器而言,遍历容器内的元素是无法绕过的一个基本操作。
按照上面的容器对象定义实现,在业务逻辑代码中,需要获取某个Project中所有已关闭的需求事项列表,并按照创建时间降序排列,我们要如何做:先从容器中取出所有的需求集合,然后自行对此需求集合进行过滤、排序等操作。
public List<Requirement> getAllClosedRequirements(Project project) {
return project.getRequirements().stream()
.filter(requirement -> requirement.getStatus() == 1)
.sorted((o1, o2) -> (int) (o2.getCreateTime().getTime() - o1.getCreateTime().getTime()))
.collect(Collectors.toList());
}
或者,也可能会写成如下更为通俗的处理逻辑:
public List<Requirement> getAllClosedRequirements(Project project) {
List<Requirement> requirements = project.getRequirements();
List<Requirement> resultList = new ArrayList<>();
for (Requirement requirement : requirements) {
if (requirement.getStatus() == 1) {
resultList.add(requirement);
}
}
resultList.sort((o1, o2) -> (int) (o2.getCreateTime().getTime() - o1.getCreateTime().getTime()));
return resultList;
}
很司空见惯的逻辑,的确也没有什么问题。但是,其实我们仅仅只是需要遍历容器中所有的元素,然后找出符合需要的内容,而Project类通过getRequirements()方法将整个内部存储List对象给出来让调用方直接去操作,存在一定的弊端:
-
调用方通过
project.getRequirements()方法获取到项目下全部的需求列表的List存储对象,然后便可以对List中的元素进行任意的处理,比如新增元素、删除元素甚至是清空List,从可靠性角度而言,我们其实并不希望任何调用方都可以去随意操作所有内容,不确定性太大、难以维护。 -
某些允许调用方进行遍历并删除元素的场景,容器直接通过
project.getRequirements()给出具体的集合对象,然后任由调用方自行遍历并删除,一些调用方可能会处理的不够完善,容易踩坑,存在隐患。可以参见我之前一篇文档《JAVA中简单的for循环竟有这么多坑,你踩过吗》里的详细说明。
进一步思考下,其实我们只是想要遍历获取到容器中的元素,是否有更优雅的方式能够实现这一简单诉求,并且还能顺带解决上述这几个小遗憾呢?
带着疑问,我们一起来梳理下容器的演进历程,聊聊作为一个容器应该具备怎样的自我修养吧。

最直白的白盒容器
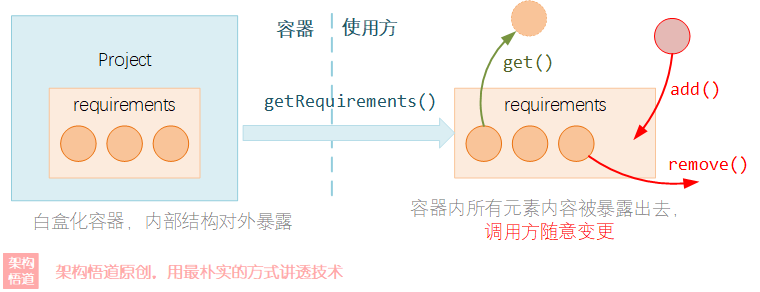
如上文中所提供的例子场景。示例中直接通过get方法将容器内管理的元素集合给暴露出去,任由调用方自行去处理使用。调用端需要知道这是一个元素集合是一个List类型还是一个Map类型,然后再根据不同类型,决定应该如何去遍历其中的元素,去对其中的元素进行操作。
白盒容器是一个典型的甩手掌柜式的容器,因为它要做的事情非常简单:给个get方法即可!任何调用方都可以直接获取到容器内部的真正元素存储集合,然后自行去对集合做各种操作,而容器则完全不管。
这样有一定的优势:
-
调用方限制较小,可以按照自己诉求随意发挥,实现自己各种诉求
-
容器实现简单,容器与业务解耦,就是个纯粹的容器,不夹杂任何的业务逻辑
但是呢,原本我们只是想遍历下容器中所有的元素内容,但是容器却直接将整个家底都交了出来。这就好比小王去小李家想看看小李家的猪里面有几只是母猪,而小李直接将猪圈丢给了小王,让小王自己进猪圈去数一样,这也太不把小王当外人了不是,谁知道小王进去是不是仅仅只是去数了下有几只母猪呢?
由此带来的弊端也就很明显了:
- 将容器内部的结构完全暴露给外部,业务逻辑中耦合了容器的具体实现细节,后面如果容器需要改造的时候,会导致业务调用逻辑必须跟着改动,影响较大,牵一发动全身。
举个简单的例子:
当前Project中采用List来存储项目下所有的需求数据,而所有的调用端都是按照List的格式来处理需求数据。如果现在需要将Project中改为使用Map来存储需求数据,则原先所有通过project.getRequirements()获取需求数据的地方,都需要配套修改。
- 对容器内数据的管控力太弱。容器将数据全盘给出,任由调用方随意的去添加、删除元素、甚至是清空元素集合,而容器却无法对其进行约束。
还是上面的例子:
业务调用方使用project.getRequirements()拿到List对象后,便可以对List进行add、remove、clear等各种操作。而很多时候,我们是需要保证对元素的内容的变更或者增减都在统一的地方去实行,这样可以保证数据的准确、也可以做一些统一处理,比如统一记录创建需求的日志之类的。而写操作入口变得不确定,使得整个数据的维护就存在很大的漏洞。
本站声明:
1. iCode9 技术分享网(下文简称本站)提供的所有内容,仅供技术学习、探讨和分享;
2. 关于本站的所有留言、评论、转载及引用,纯属内容发起人的个人观点,与本站观点和立场无关;
3. 关于本站的所有言论和文字,纯属内容发起人的个人观点,与本站观点和立场无关;
4. 本站文章均是网友提供,不完全保证技术分享内容的完整性、准确性、时效性、风险性和版权归属;如您发现该文章侵犯了您的权益,可联系我们第一时间进行删除;
5. 本站为非盈利性的个人网站,所有内容不会用来进行牟利,也不会利用任何形式的广告来间接获益,纯粹是为了广大技术爱好者提供技术内容和技术思想的分享性交流网站。
原创文章,作者:ItWorker,如若转载,请注明出处:https://blog.ytso.com/294443.html