
读前须知:
- 入门内容,但是你需要自己安装python, torch, jupyterlab, transformers 等… 网上教程有很多。
- 是的,可以本地部署,可以聊天,但是目前公开的模型(这篇将使用ChatYuan-large-v1)很小很蠢,但也值得试试。
开始之前:
– ChatGPT 作为一个LLM(大型语言模型)是如何“记忆”聊天内容以达到理解上下文的?
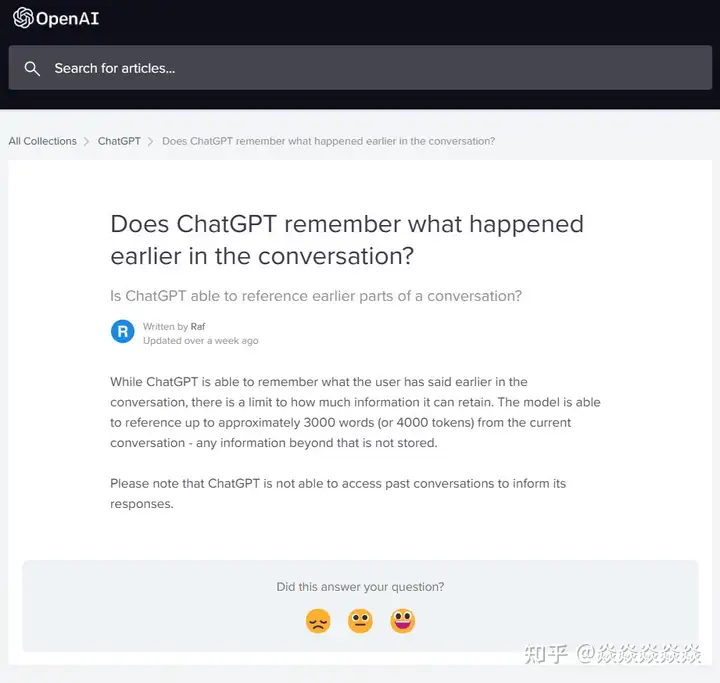
答案是,至少目前不行,约3000词(4000 tokens)限制的当前会话内容看起来是一股脑输入到模型中的。
– 超过3000词呢?
不明确,可能之前的内容会直接被忽略,也可能由模型自己概括。
准备工作:
我之前有尝试过一些LLM如Bloom,但它们训练的主要目的就是接龙,可以以对话形式(如“A:xxxxx. B:”)输入来要求模型接龙,然而模型本身并不知道什么时候停止,就会出现一些很尴尬的情况,如模型完成它应有的输出后又顺路完成了用户的输入,甚至干脆一口气生成几轮会话等。
加之一些模型对多语言环境并不友好,对中文支持能力很差,所以我们需要一个针对会话和中文内容调整训练过的模型。 正好最近发现 Hugging Face 上的 ClueAI/ChatYuan-large-v1 这个模型很有意思,所以决定试试看。
下载模型:
可以直接用模型下方提供的代码,这样子模型将会直接下载到你C盘用户\用户名\.cache(Windows 用户)文件夹下:
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("ClueAI/ChatYuan-large-v1")
model = T5ForConditionalGeneration.from_pretrained("ClueAI/ChatYuan-large-v1")也可以直接 git clone https://huggingface.co/ClueAI/ChatYuan-large-v1 到你的目录里, 然后加载:
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("./ChatYuan-large-v1")
model = T5ForConditionalGeneration.from_pretrained("./ChatYuan-large-v1")复制一些官方在模型下面提供的函数:
import torch
from transformers import AutoTokenizer
from IPython.display import clear_output
device = torch.device('cuda')
model.to(device)
def preprocess(text):
text = text.replace("\n", "\\n").replace("\t", "\\t")
return text
def postprocess(text):
return text.replace("\\n", "\n").replace("\\t", "\t")
def answer(text, sample=True, top_p=1, temperature=0.7):
'''sample:是否抽样。生成任务,可以设置为True;
top_p:0-1之间,生成的内容越多样'''
text = preprocess(text)
encoding = tokenizer(text=[text], truncation=True, padding=True, max_length=768, return_tensors="pt").to(device)
if not sample:
out = model.generate(**encoding, return_dict_in_generate=True, output_scores=False, max_new_tokens=512, num_beams=1, length_penalty=0.6)
else:
out = model.generate(**encoding, return_dict_in_generate=True, output_scores=False, max_new_tokens=512, do_sample=True, top_p=top_p, temperature=temperature, no_repeat_ngram_size=3)
out_text = tokenizer.batch_decode(out["sequences"], skip_special_tokens=True)
return postprocess(out_text[0])到这里已经可以使用 answer() 函数实现接龙功能了:



实现一个很简单的聊天功能:
def make_context(input_text, answer_text):
context = ''
for i, input_str in enumerate(input_text):
context += f"\n用户:{input_str}\n小元:{answer_text[i] if i < len(answer_text) else ''}"
return context
input_text = []
answer_text = []
while 1:
intext = input("用户:")
if intext.lower() == "ex": #退出
break
if intext.lower() == "re": #重开
input_text = []
answer_text = []
intext = input("用户:")
input_text.append(intext)
context = make_context(input_text,answer_text)
clear_output(wait=True)
print(context)
ans=answer(context)
answer_text.append(ans)
context = make_context(input_text,answer_text)
clear_output(wait=False)
print(context)效果:

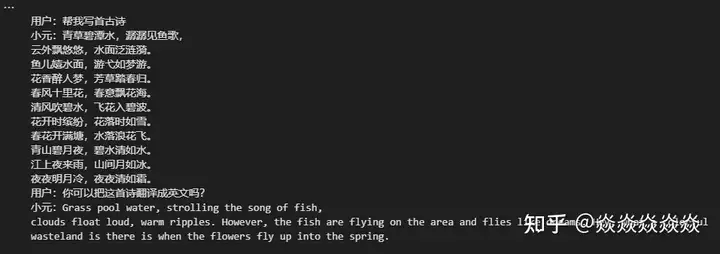

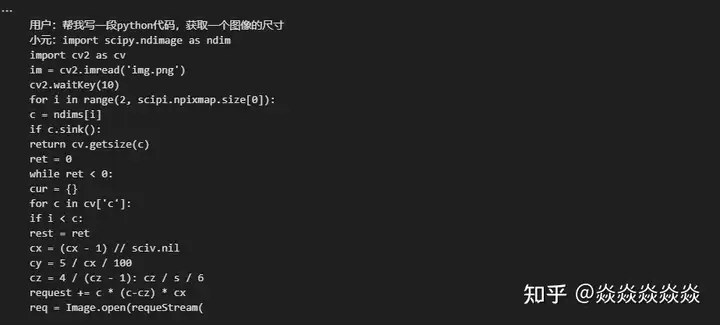


结论:
作为一个2.91GB的模型,对于它的任务而言它的尺寸实际上称不上Large,也不是很聪明的样子,处于一个基本不可用的状态。但是过程很有趣,本地部署起来很流畅,单次推理的时间也很短,可以回答一些很简单的问题,有一定的上下文理解能力,但极其有限。
不知道如果模型的体积增加一倍,再继续针对会话训练的话会是什么样子…
原创文章,作者:奋斗,如若转载,请注明出处:https://blog.ytso.com/297056.html