
自动化运维时代,共有的困惑
活动常常爆满的背后,是大家对于自动化运维的共同需求,以及在推动IT运维自动化过程中有着相同的困惑,比如:
- 企业落地自动化之前是否一定要先实施标准化?
- 我们的CMDB配置数据不准确,如何实施自动化?
- 听说腾讯蓝鲸很强大,用蓝鲸和Ansible实现自动化到底有何区别?
- 我们也想用腾讯蓝鲸来落地自己公司的运维自动化,但是以往踩过太多坑了,会不会用了蓝鲸之后,又上了另外一条使用门槛高昂,难以下去的“贼船”?
如果你也有着相同的疑惑,同时没能够亲临现场,倾听嘉宾的讲解,也没关系,我们在这篇文章中一起来解答上述的困惑,并最终回到一个出发点:自动化运维时代,我们该如何做才好。
自动化运维完整视图
首先,我们需要回答一个问题:大家一直在提自动化运维,自动化运维到底包括哪些方面呢?
全球最具权威的IT研究与顾问咨询公司Gartner对此的定义如下:

自动化运维是通过工具或者平台,实现IT基础设施和应用的日常任务和运维流程自动化,从而提高效率,降低风险,促进组织业务能力提升。
主要包括:日常任务处理自动化、运维流程自动化、IT服务自动化、业务服务自动化以及整体运维运营能力升级等内容。
针对上述自动化运维的范畴,Gartner还定义了成熟度模型,如下图所示:

Gartner将企业实施自动化的成果分为起步、基本、标准、合理、动态等5个阶段,在每个阶段定义了企业应该达成怎样的目标,如上图所示。
无独有偶,在蓝鲸的落地实施过程中,针对企业的运维现状,由浅入深一般建议按照:基础架构自动化、应用自动化、IT服务自动化、业务运营自动化;事实上,这四个阶段基本对应着Gartner的“基本、标准、合理、动态”四个阶段;异曲同工,殊途同归。
基于上述对于自动化的理解,嘉维蓝鲸自动化运维解决方案提供了一套标准的,符合Gartner定义,并贴近国内IT现实的自动化运维全领域视图,如下所示:
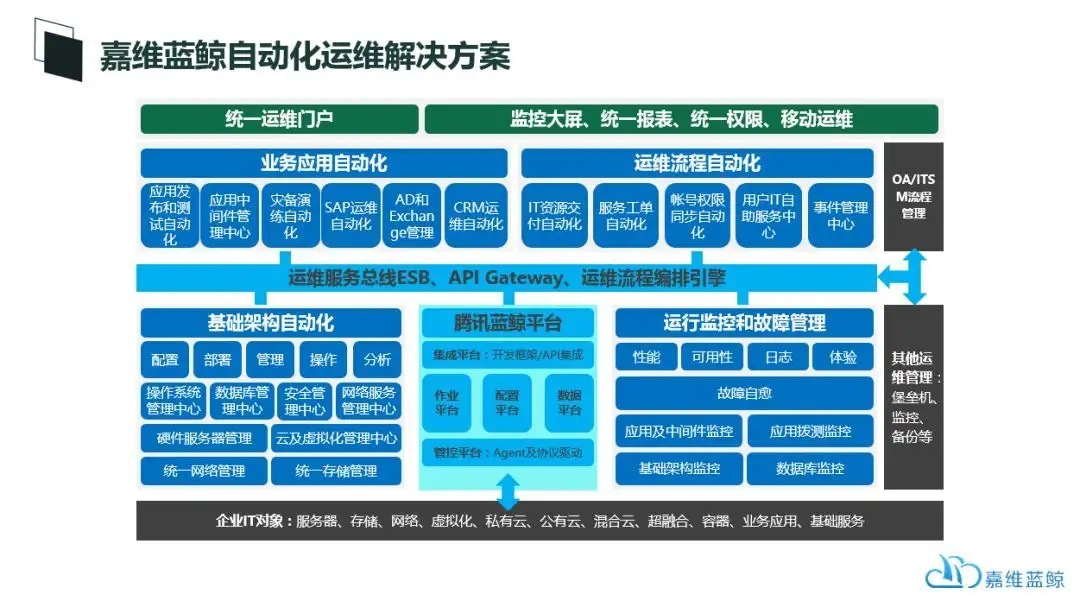
在上述视图中,如果说腾讯蓝鲸平台是自动化运维这棵大树的主树干,那么:基础架构自动化、运行监控和故障管理、业务应用自动化、运维流程自动化就是在数干上长出来的树枝;加上统一运维门户,他们一起构成整个自动化运维的大树。
自动化之前,一定要标准化吗?
先说我们的理解:标准化当然要做,但是没有工具支撑的标准化都是耍流氓;因此两者可以同步和谐进行,甚至可以先构建自动化平台或者工具,再在平台上将我们的标准化落地为具体的自动化流程或者功能。
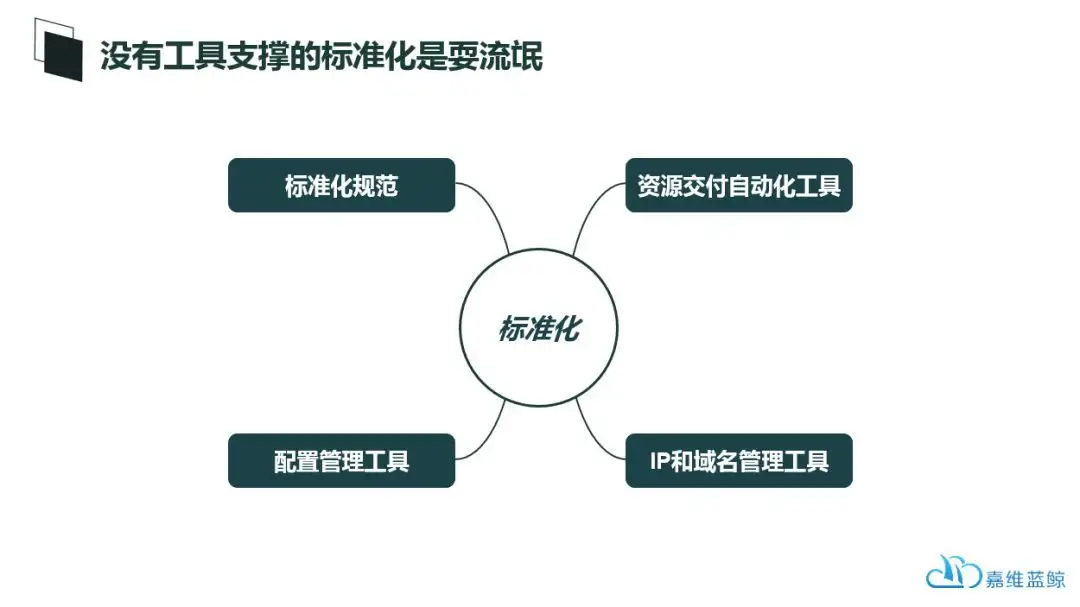
为什么这么说呢?
腾讯蓝鲸产品中心总监党受辉同学经常提到的一个观点:要实现一个目标,需要三个要素——理念先行、责任到人、工具支撑。
在实现IT运维标准化层面,也是相同的道理。
例如我们要落地IT基础架构日常运维的标准化,自然是先把口号喊出来,最好办公室里贴上一个“奋战100天,彻底实现基础架构标准化”红色横幅,对吧?
然后走的远一点的公司呢,可能会专门成立一个标准化小组,来贯彻执行标准化改造的工作,成果一般是交付一大堆关于机房机架管理规范、配置管理标准流程、Linux 生命周期管理规范、日常运维操作规范手册等的文档,然后就没有然后了。

你如果真诚的(哎,说你呢,把鼻子上的两根葱拔掉)、认真的回忆下自己公司过往的标准化项目经历,上述的场景是不是很熟悉呢?
究其原因是:离开自动化的平台或者工具支撑,这种标准化不过是空中楼阁,落地成本巨大(你想象下,凡事都要按照标准流程手动执行,又没有自动化工具帮助你,你什么感受?肯定是原来怎么干,继续怎么干嘛);落不了地,也谈不上改进和调整标准化流程,最后自然是束之高阁,不了了之。
反过来讲,比如我们将企业内一个数据库VM交付的流程通过蓝鲸自动化运维平台,固化成一个流程,这个流程,运维人在自动化平台上可以一键交付;如果这个流程后续满足不了标准化的要求,我们只需要调整中间的流程节点即可(例如配置信息不满足标准化规范,可以调整配置生成的流程原子,使之符合规范),或者重新再造一个标准化流程,成本也非常低(因为蓝鲸支持组装式流程编排,并且构成流程的原子本身可以无限复用),通过这种方式确保标准化能够真正落地,并能持续改进,同时基于自动化平台,使得这种流程本身执行和改造的成本都是很低的。
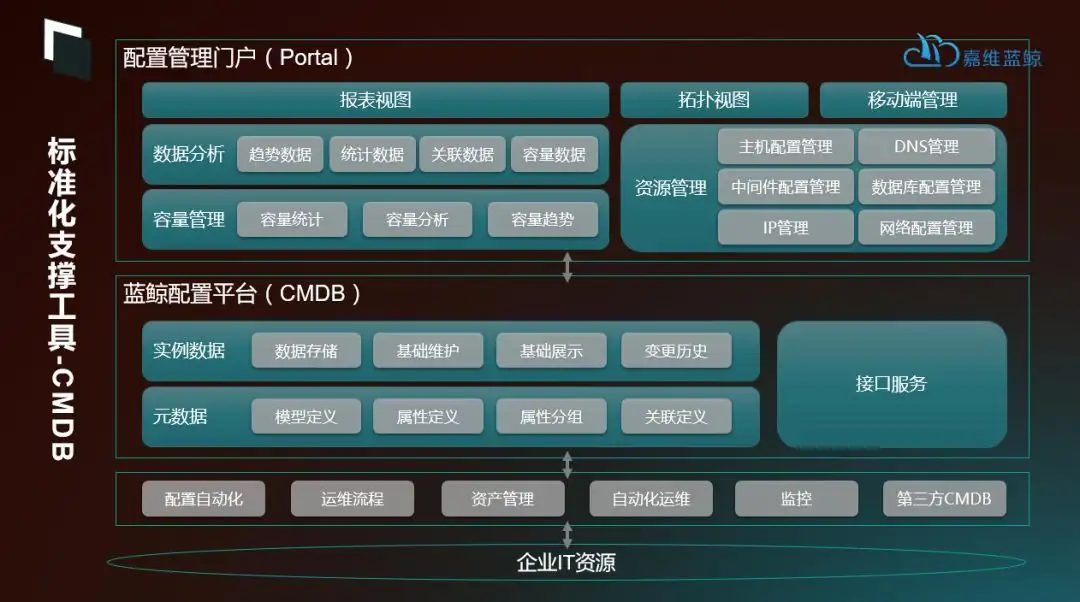
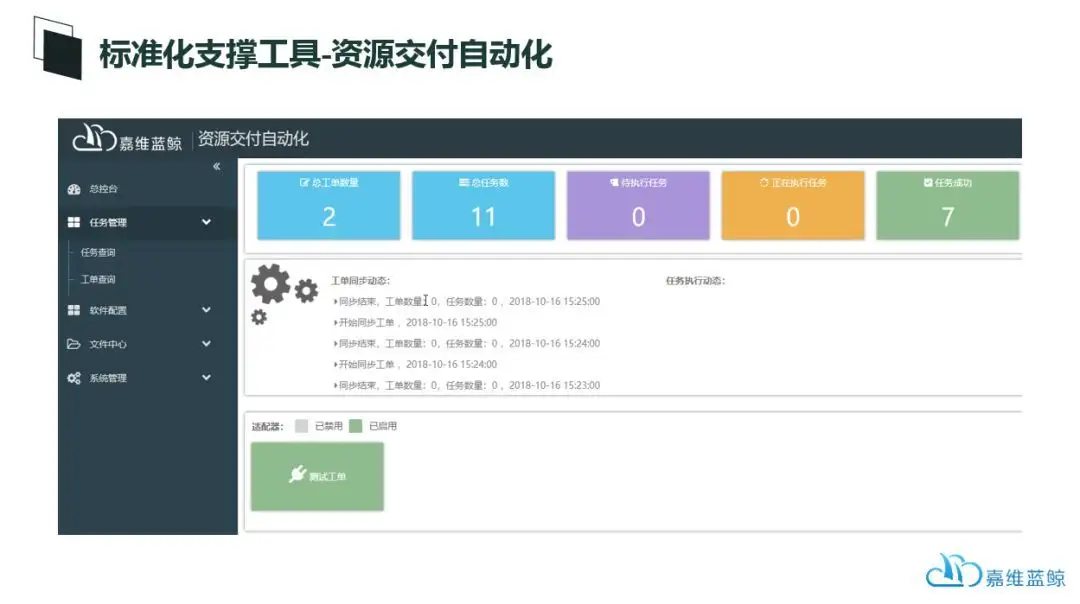
在蓝鲸平台上,为运维标准化的落地提供了包括PaaS层平台、SaaS层工具等各个层次的支撑,包括CMDB、资源交付自动化、IP地址管理等等。
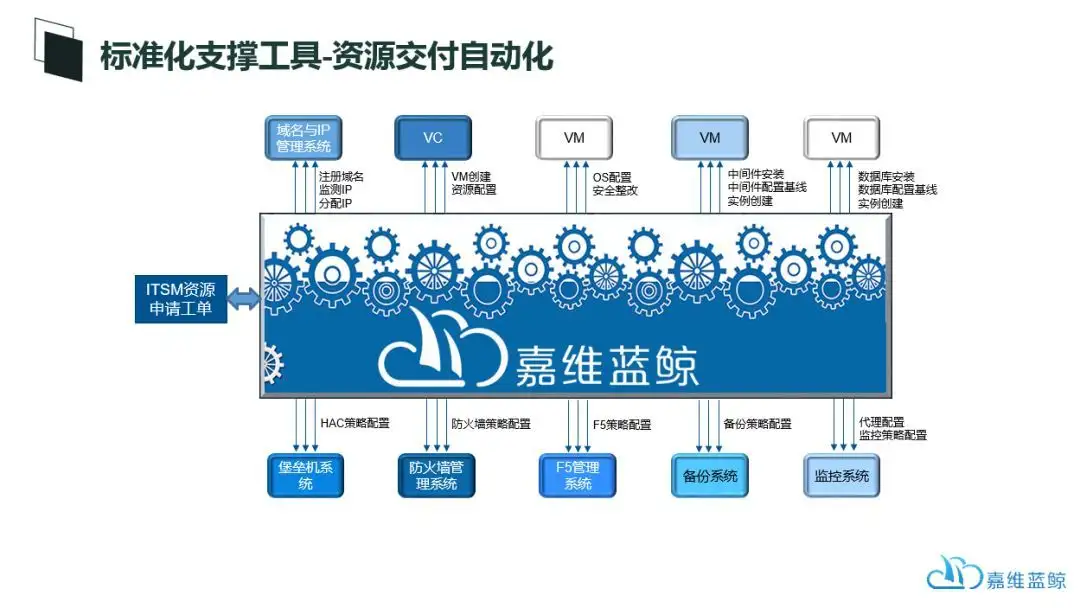
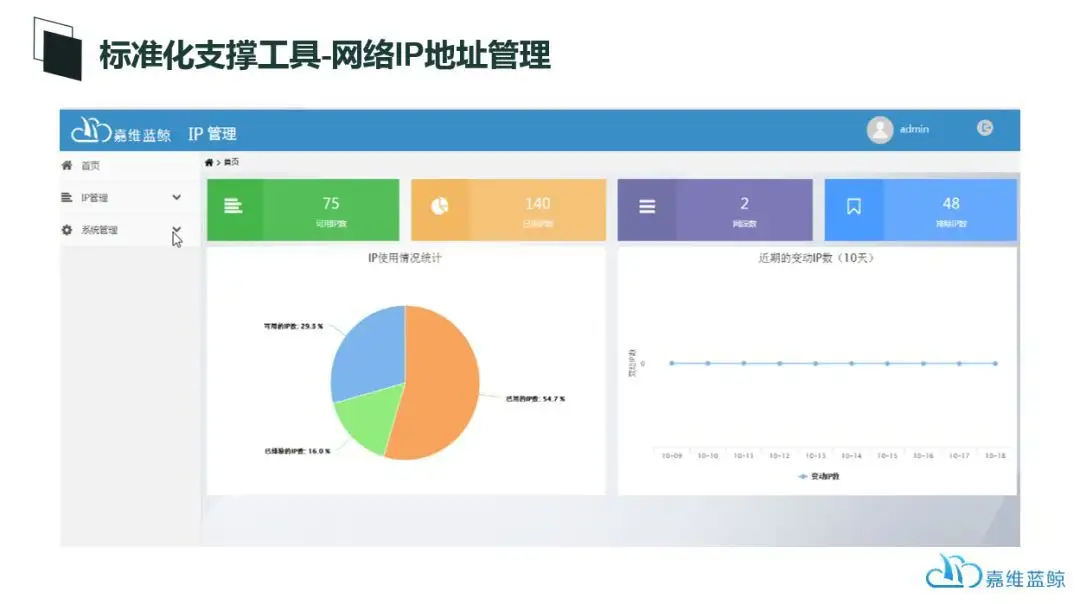
蓝鲸,轻松实现全方位的数据中心基础架构自动化
数据中心是企业的IT心脏,涵盖了从中间件、数据库、操作系统等软件到堡垒机、防火墙、路由交换、备份存储、服务器等硬件的基础架构。
回顾我们前面提到的Gartner的阶段划分,自动化运维基础层面的实现,就是实现基础架构资源运维管理的自动化。而蓝鲸完全具备这样的能力。
并且蓝鲸在实现基础架构自动化的过程中,有一套通用的方法论来支撑,就是OASR模型,四个字母分别代表的是:运维对象(Objects)、运维活动(Activities)、运维场景(Scenes)、运维角色(Roles)。几乎任何一个IT对象的运维管理场景都会涵盖上述四个方面,不同的运维管理操作的过程其实就是上述四个指标项重新组装的过程。
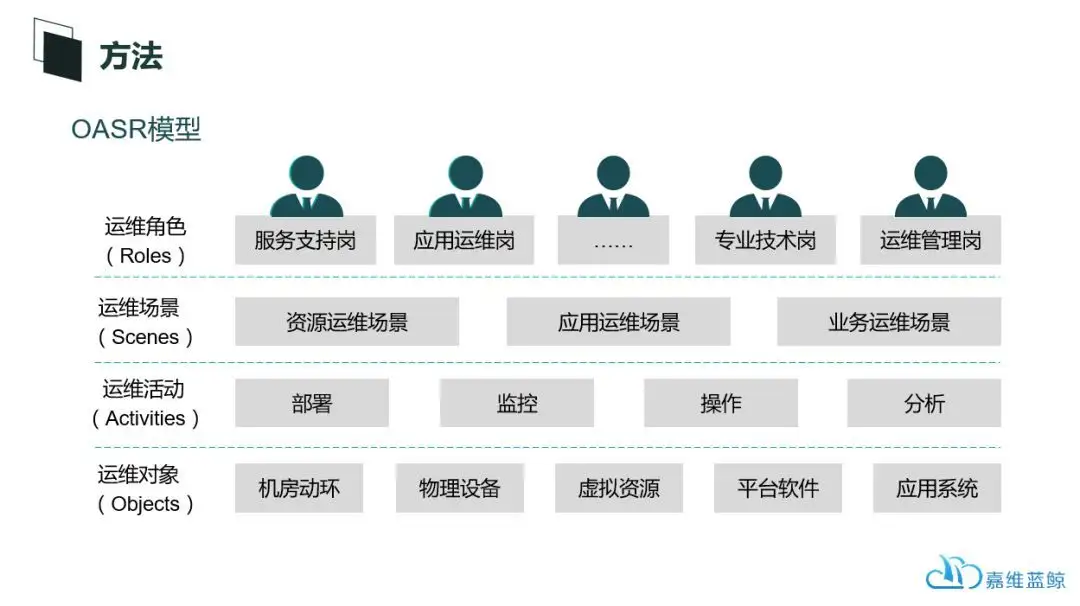
对于蓝鲸平台而言,通过蓝鲸管控平台提供的agent代理、API接口、远程脚本调用等方式,能够实现运维对象的统一接入、纳管以及脚本、文件、数据层面的驱动;
而蓝鲸的作业平台、标准运维、配置管理、容器平台、大数据平台等PaaS模块涵盖了几乎企业所有IT运维运营所需要的能力,并且能够实现模块能力的持续复用和自定义组装;
另外,蓝鲸的开发者中心所提供的敏捷APP开发功能,使得无论我们面对现在还是未来的各种运维运营场景,都可以通过自定义开发新的APP方式从容应对;
而针对运维人员和权限的管理,蓝鲸提供了统一的权限管理中心作为统一的控制中枢,同时能够对接AD、OpenLadp等目录管理,实现用户、角色、权限的统一认证和管理。
可以看到,基于OASR方法论构建的蓝鲸平台,在自动化运维基础架构层面,能力是非常强大的。

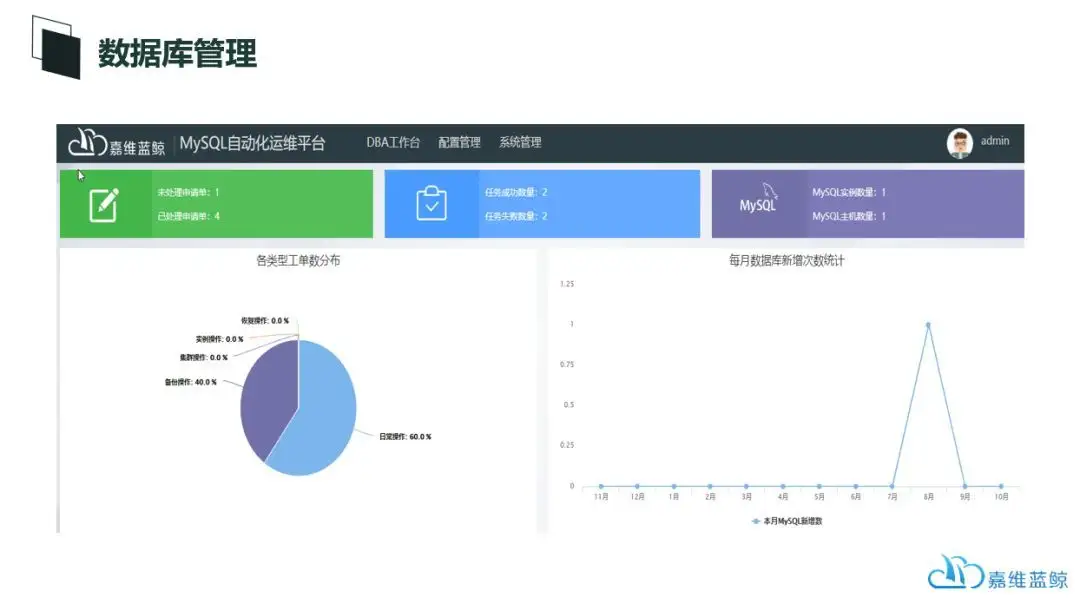
蓝鲸,轻松实现跨系统、跨应用的、端到端编排操作
借助于蓝鲸强大的标准运维编排引擎,蓝鲸可以实现非常强大的跨越系统、应用、数据中心、工具平台的端到端的编排操作。
关于蓝鲸标准运维的能力,大家可以参见我们之前的文章《看蓝鲸标准运维如何编排一切》,里面对此有非常详细的讲解。
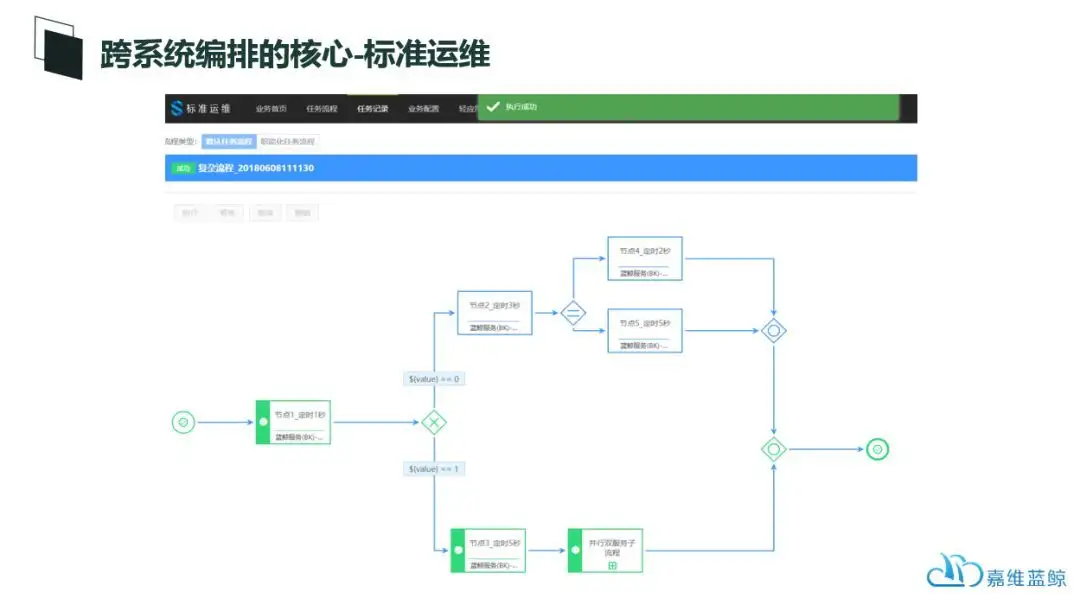
借助于标准运维:
- 我们首先考虑清楚需要实现哪些运维场景的运维流程自动化;
- 接下来就是进行运维流程的梳理和每个原子节点操作的定义;
- 然后需要考虑哪些人能够执行这个操作,进行权限的配置;
- 接下来便是每个原子操作的快速组装开发;
- 再将原子通过图形拖拽的方式组装成流程;
- 进行测试后,就可以发布为生产环境的流程,供运维人员使用。

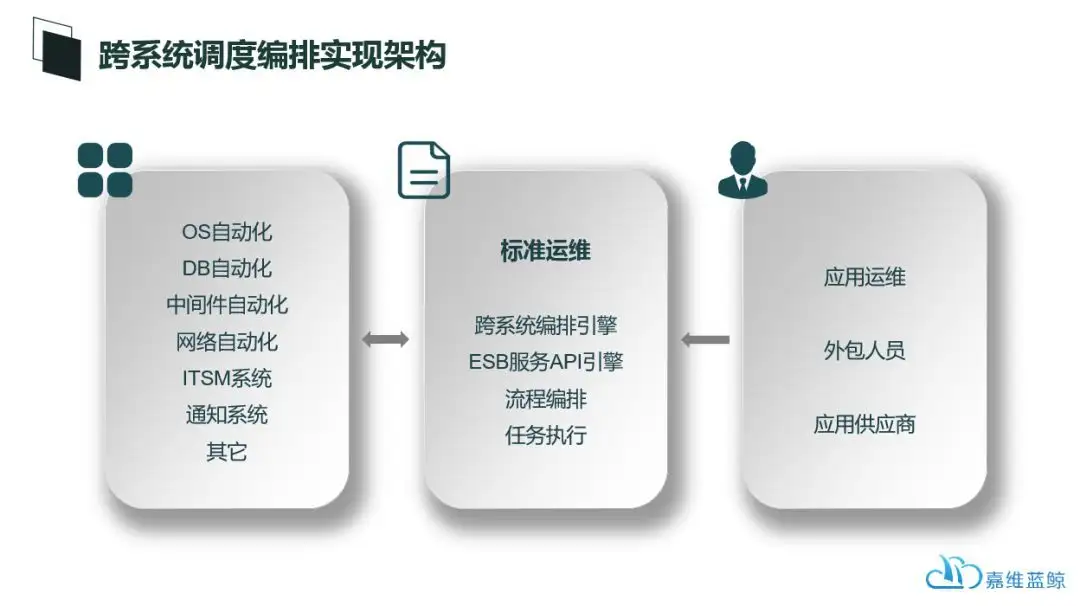
借助于标准运维,我们自定义各种各样的运维流程和操作场景,比如应用发布自动化、ITSM工单自动化、应用灾备演练自动化、AD与Exchange协同自动化等等。
最为重要的是,在每个场景中固定下来的原子都可以在未来进行无限次复用;除此之外,由于蓝鲸的ESB能够对接企业内各种第三方系统,因为这种编排可以持续满足未来的运维场景需求。
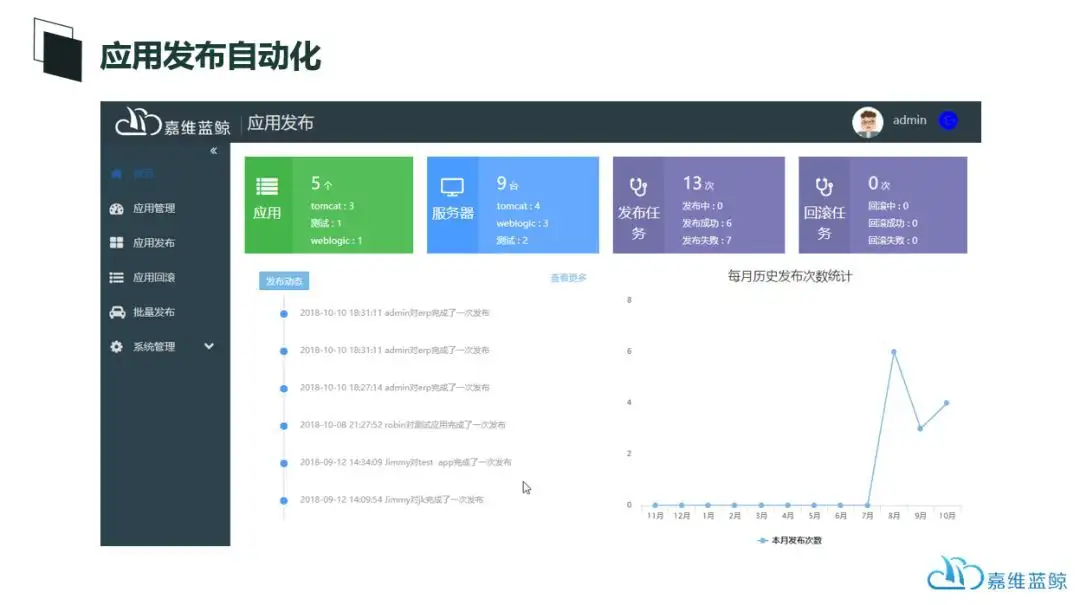

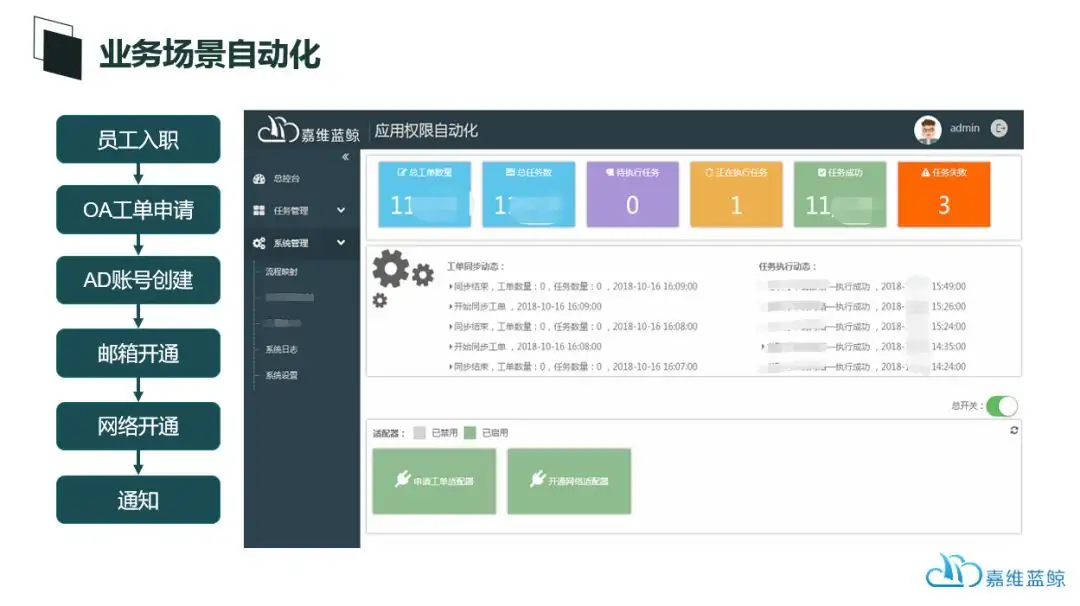
蓝鲸故障自愈及数据可视化
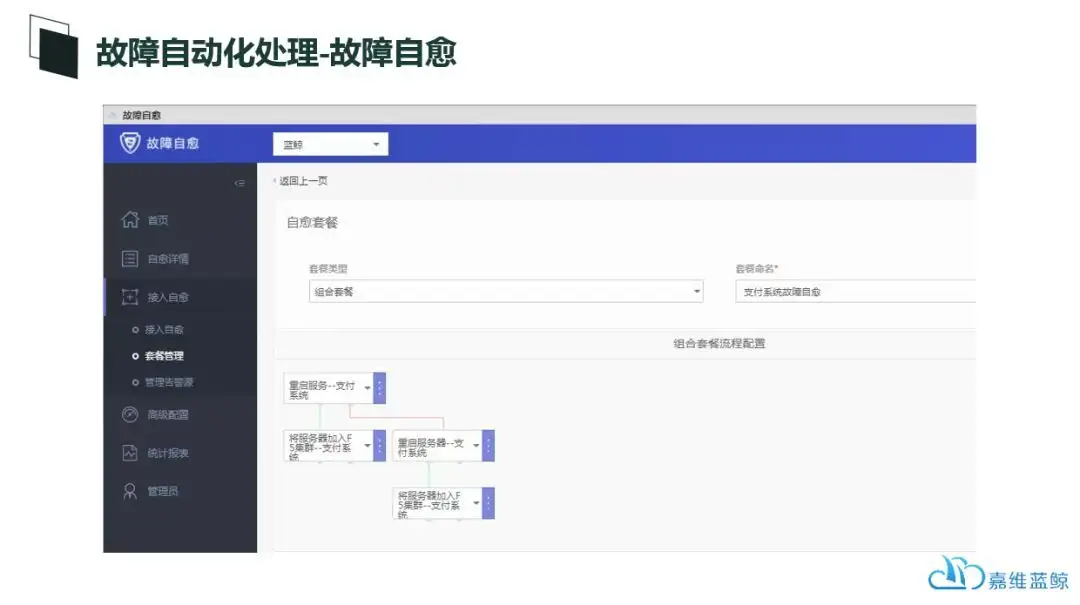
故障自愈可能是蓝鲸平台在业内首倡的理念,同时蓝鲸的故障自愈在腾讯内部的大规模环境中也是用的非常广泛的功能。
故障自愈的原理非常简单:
接入监控数据源 → 识别告警,匹配故障自愈策略 → 自动化执行告警 → 通知管理员。
但是,这里也需要一个前提条件,就是这种故障本身,在我们的环境中出现的原因是可以穷举的,并且我们有成熟的处理流程和规范,这样才能够制定出恰当的故障自愈策略。
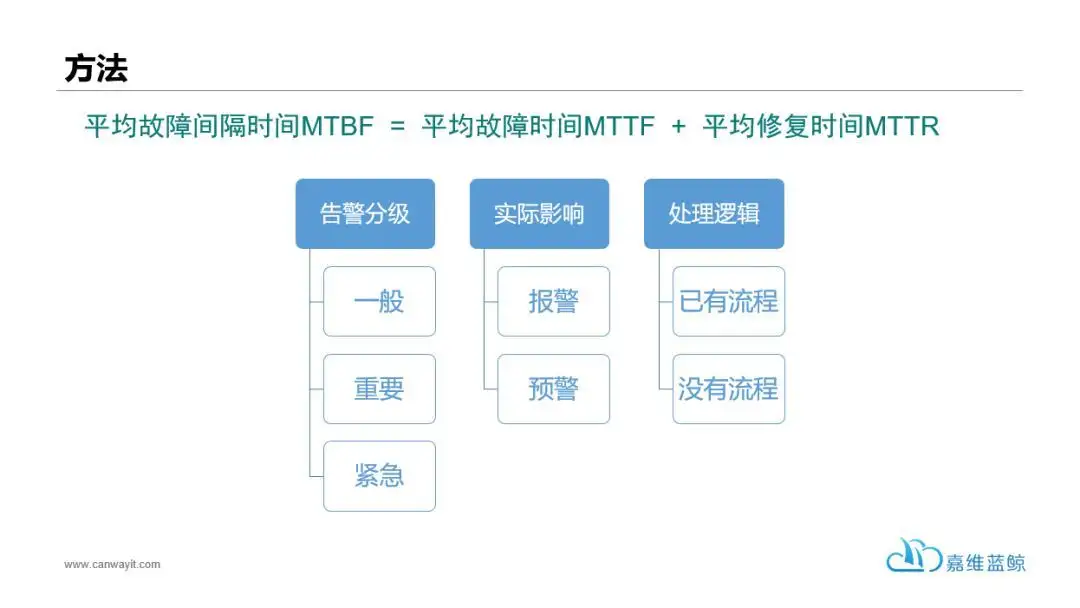
故障自愈的方法论如下,先需要对故障做分级以及处理逻辑的制定:
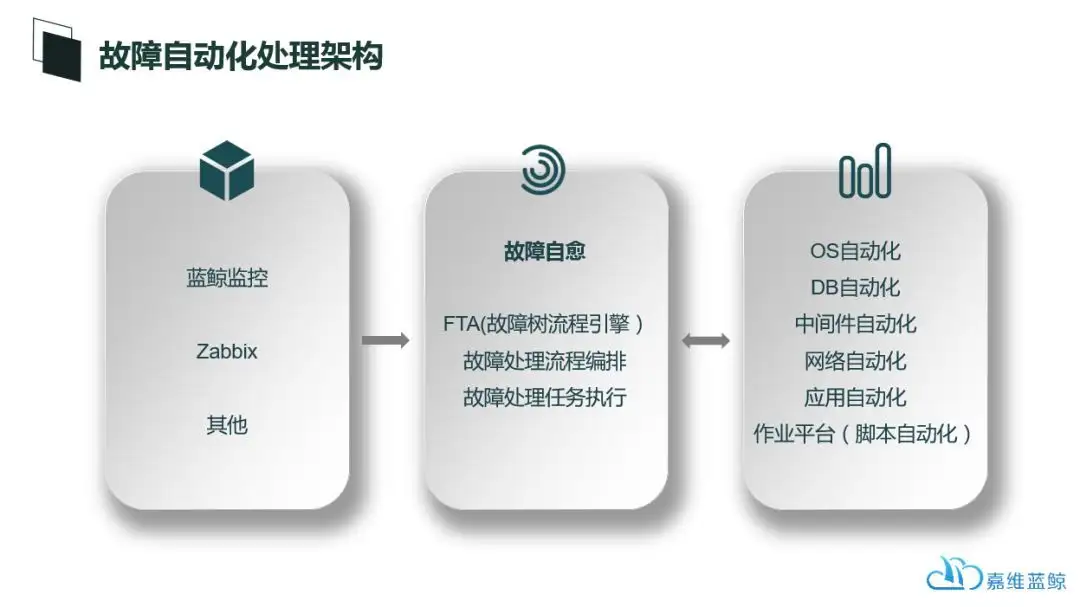
故障自愈的整体架构如下图所示,这里的监控告警源既可以是蓝鲸自身的蓝鲸监控,也可以来自其他监控系统,比如zabbix等;而自动化的故障自愈本身则需要依赖蓝鲸的自动化运维的能力去驱动、调度和实现:
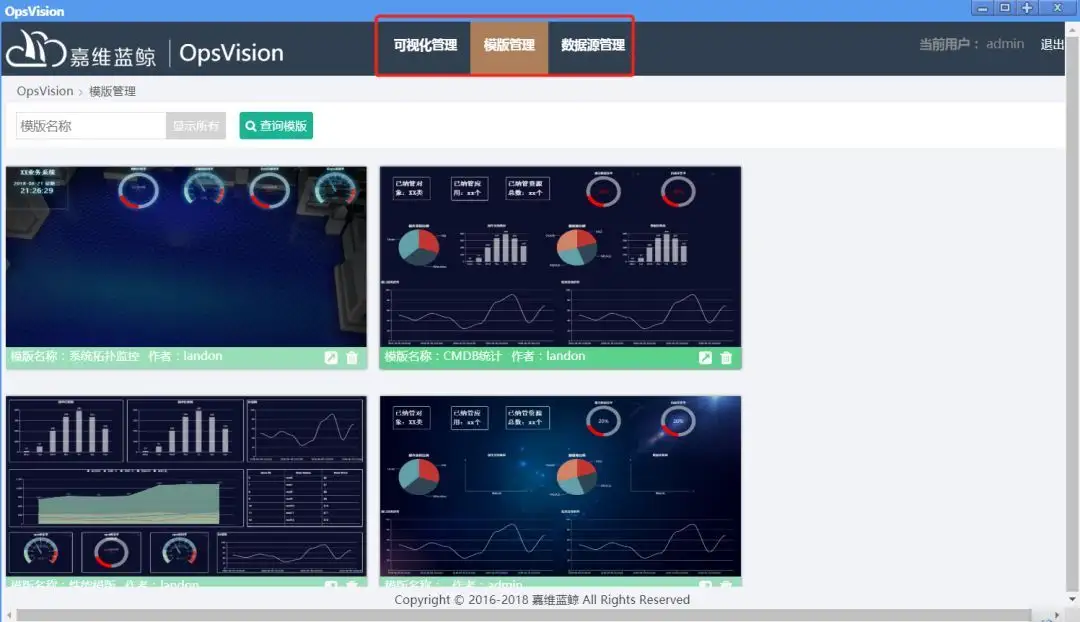
除了执行自动化运维操作之外,我们在日常的管理中,还需要对各种各样的数据进行汇总、分析、查询和展示,这种需求既可能来自IT运维人,也可以来自IT或者公司上层的领导,这个时候可以通过嘉维蓝鲸的数据可视化模块,实现非常灵活的数据接入、分析和展示功能。
IT运维自动化时代已经来临,对于企业而言,这是更迭自己IT运维管理模式与阶段的时代,对于运维人而言,也是可以大展拳脚的时代。
而蓝鲸能够在企业IT运维转型及运维人的转型上,助一臂之力。
原创文章,作者:奋斗,如若转载,请注明出处:https://blog.ytso.com/302947.html