
问题:
select item.itemnum,item.in1,item.in4,inventory.location from item,inventory
where item.itemnum=inventory.itemnum
and inventory.location='DYB'
and item.in1='D/MTD/MRM'
GROUP BY ITEM.ITEMNUM
提示错误是NOT A GROUP BY EXPRESSION
答案:
GROUP BY 是分组查询, 一般 GROUP BY 是和 聚合函数配合使用,你可以想想
你用了GROUP BY 按 ITEM.ITEMNUM 这个字段分组,那其他字段内容不同,变成一对多又改如何显示呢,比如下面所示
A B
1 abc
1 bcd
1 asdfg
select A,B from table group by A
你说这样查出来是什么结果,
A B
abc
1 bcd
asdfg
右边3条如何变成一条,所以需要用到聚合函数,比如
select A,count(B) 数量 from table group by A
这样的结果就是
A 数量
1 3
group by 有一个原则,就是 select 后面的所有列中,没有使用聚合函数的列,必须出现在 group by 后面
讨论:MySQL和Oracle对group by的解析是不一样的!
mysql:
SELECT s.SName, sc.COUNT(CID) c
FROM SC sc JOIN S s ON sc.SID = s. SID
GROUP BY s.SID
HAVING c = ( SELECT COUNT(*) FROM C )
oracle:
SELECT s.SID, s.SName, sc.COUNT(CID) c
FROM SC sc JOIN S s ON sc.SID = s.SID
GROUP BY s.SID, s.SName
HAVING c = ( SELECT COUNT(*) FROM C )
大家可以看到区别了,mysql对group by子句的限制有所放宽,除了集合函数之外的被查询字段也可以不参与分组。相反oracle则是严格要求,所以感觉mysql似乎更灵活一些。
再来点有深度的:
前面提到了聚合函数,其实作用于一组记录的,那么这一组记录可由什么产生呢?不可能
都是以整张表的形式吧。这就需要Group by子句来完成了。
Group by
Group by子句:
● Group by子句将一个表分成许多小组,并对每一个小组返回一个计算值。
● Group by expression:指按什么列进行分组
注意事项:
● 在select子句中,如果使用了分组函数,就不能对group by指定的列使用分组函数。
● 使用where子句可以预先排除某些记录
● 在Group by子句中必须有表中的列
● Group by子句不能使用别名
● 可以通过Order by子句改变它的排序情况
基本用法
对于其基本的用法直接以实例的形式来展示。
1、统计各个部门的员工的工资的总和
[sqselect deptno ,sum(sal) from emp group by deptno;
–升序排列
select deptno ,sum(sal) from emp group by deptno order by deptno asc; 、统计各个部门各个职业的员工的工资的总和
[sql]
select deptno,job,sum(sal) from emp
group by(deptno,job) order by deptno;
Tips:第二个实例其实就是多列分组,先对部门进行分组,之后对职位进行分组。

3、Having子句的使用
我们知道分组函数是不能加在WHERE子句中的,但是有时候我们需要对分组进行限定
只有符合某个要求的分组才会被选择出来,那么就可以通过having子句来进行。具体的用法
同样以一个实例说明。
在2的基础上添加一个条件:工资总和必须在10000以上
[sql]
select deptno ,sum(sal) from emp group by deptno
having sum(sal)>10000;
Tips:思考一下Having子句与where子句的区别
两者都是对数据进行筛选,不同的是where是对原数据进行筛选而having则是对汇总
后的结果进行一个筛选而已!
扩展用法
除了基本的用法外,group by还具有一些扩展的用法,不过大多数情况下基本的用法基本上
就可以满足我们的操作了。
1、使用rollup操作符
rollup,是group by子句的一种扩展,可以为每个分组返回小计记录以及对所有的分组返回
总计记录。下面看看其基本的用法吧。
⊙ 向rollup传递一列
[sql]
select deptno,sum(sal) from emp where DEPTNO>=20 group by rollup(deptno) ;
不过需要注意的是要对所有的记录进行一个总计的话,应该要一个聚合函数
不然根本没有实际的意义!
⊙ 向rollup传递多列
Tips:需要注意的是rollup作用于多列的时候,之对第一列起作用!
[sql]
select deptno,job,sum(sal) from emp group by rollup(deptno,job);
select deptno,job,sum(sal) from emp group by rollup(job,deptno);
``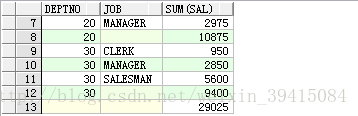
可以看出的是除了最后又一个总计外,每个deptno都有一个小计,至于两个
列交换的结果原理是一样的,这里就不在演示了。
2、使用cube操作符
cube也是Group by子句的一种扩展,返回每一个列组合的小计记录,同时在头部加上
总计记录。(Oracle 11g)貌似和以前不一样?
⊙ 向cube传递一列
[sql]
select deptno,sum(sal) from emp group by cube(deptno);
效果看起来和rollup没有什么两样嘛,只是总计的位置变了嘛,别慌看多列的情况!
⊙ 向cube传递多列
[sql]
select deptno,job,sum(sal) from emp group by cube(deptno,job);
“`
可以看出cube在每一个deptno都返回一个记录(部门的所有工资总数),并且就部门中的
每种工作的工资总数做了一个小计,而且就每种工作的工资做了一个小计(没有部门限制),而且
对所有的工资总数做了一个总计。
原创文章,作者:ItWorker,如若转载,请注明出处:https://blog.ytso.com/4446.html