
文章目录[隐藏]
了解InfluxDB
1.1 InfluxDB 的使用场景
InfluxDB 是一种时序数据库,时序数据库通常被用在监控场景,比如运维和 IOT(物联网)领域。这类数据库旨在存储时序数据并实时处理它们。
比如。我们可以写一个程序将服务器上 CPU 的使用情况每隔 10 秒钟向 InfluxDB 中写入一条数据。接着,我们写一个查询语句,查询过去 30 秒 CPU 的平均使用情况,然后让这个查询语句也每隔 10 秒钟执行一次。最终,我们配置一条报警规则,如果查询语句的执行结果>xxx,就立刻触发报警。
上述就是一个指标监控的场景,在 IOT 领域中,也有大量的指标需要我们监控。比如,机械设备的轴承震动频率,农田的湿度温度等等。
1.2 为什么不用关系型数据库
1.2.1 写入性能
关系型数据库也是支持时间戳的,也能够基于时间戳进行查询。但是,从我们的使用场景出发,需要注意数据库的写入性能。通常,关系型数据库会采用 B+树数据结构,在数据写入时,有可能会触发叶裂变,从而产生了对磁盘的随机读写,降低写入速度。
当前市面上的时序数据库通常都是采用 LSM Tree 的变种,顺序写磁盘来增强数据的写入能力。网上有不少关于性能测试的文章,同学们可以自己去参考学习,通常时序数据库都会保证在单点每秒数十万的写入能力。
1.2.2 数据价值
我们之前说,时序数据库一般用于指标监控场景。这个场景的数据有一个非常明显的特点就是冷热差别明显。通常,指标监控只会使用近期一段时间的数据,比如我只查询某个设备最近 10 分钟的记录,10 分钟前的数据我就不再用了。那么这 10 分钟前的数据,对我们来说就是冷数据,应该被压缩放到磁盘里去来节省空间。而热数据因为经常要用,数据库就应该让它留在内存里,等待查询。而市面上的时序数据库大都有类似的设计。
1.2.3 时间不可倒流,数据只写不改
时序数据是描述一个实体在不同时间所处的不同状态。

就像是我们打开任务管理器,查看 CPU 的使用情况。我发现 CPU 占用率太高了,于是杀死了一个进程,但 10 秒前的数据不会因为我关闭进程再发生改变了。
这是时序数据的一大特点。与之相应,时序数据库基本上是插入操作较多,而且还没有什么更新需求。
1.3 InfluxDB生态简介
根据上文的介绍,我们首先可以知道时序数据一般用在监控场景。大体上,数据的应用可以分为 4 步走。
(1)数据采集
(2)存储
(3)查询(包括聚合操作)
(4)报警
这样一看,只给一个数据库其实只能完成数据的存储和查询功能,上游的采集和下游的报警都需要自己来实现。因此 InfluxData 在 InfluxDB1.X 的时候推出了 TICK 生态来推出 start 全套的解决方案。
TICK4 个字母分别对应 4 个组件。
T : Telegraf - 数据采集组件,收集&发送数据到 InfluxDB。
I : InfluxDB - 存储数据&发送数据到 Chronograf。
C : Chronograf - 总的用户界面,起到总的管理功能。
K: Kapacitor - 后台处理报警信息
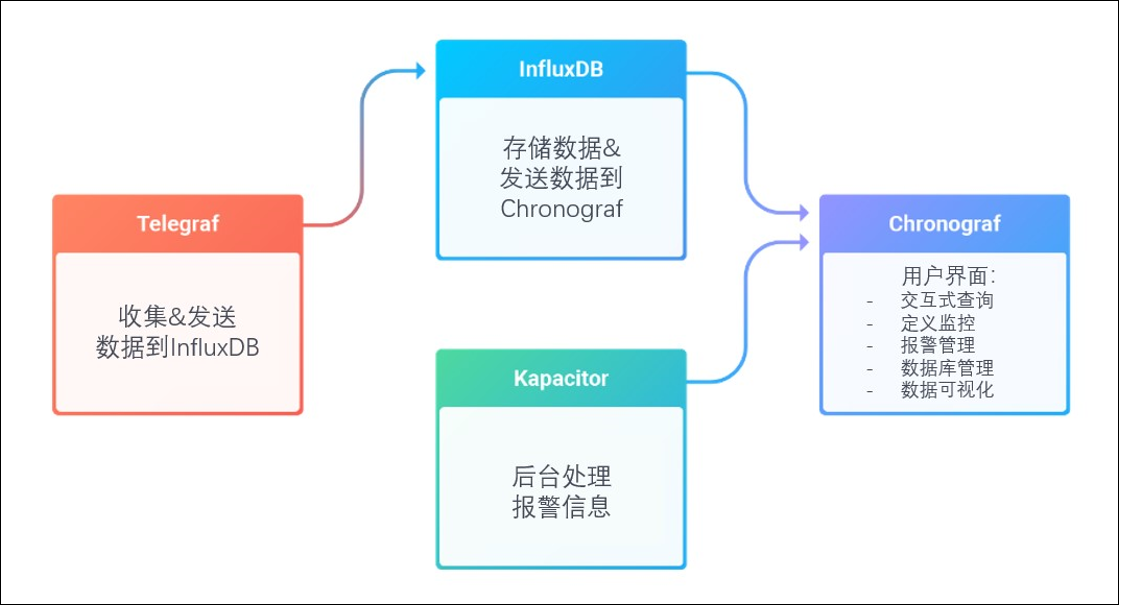
到了 2.x,TICK 进一步融合,ICK 的功能全部融入了 InfluxDB,仅需安装 InfluxDB 就能得到一个管理页面,而且附带了定时任务和报警功能。
1.4 influxDB 版本比较与选型
1.4.1 版本特性比较
2020 年 InfluxDB 推出了 2.0 的正式版。2.x 同 1.x 相比,底层引擎原理相差不大,但会涉及一些概念的转变(例如 db/rp 换成了 org/bucket)。另外,对于 TICK 生态来说,1.x 需要自己配置各个组件。2.x 则是更加方便集成,有很棒的管理页面。
另外,在查询语言方面,1.x 是使用 InfluxQL 进行查询,它的风格近似 SQL。2.x 推出了 FLUX 查询语言,可以使用函数与管道符,是一种更符合时序数据特性的更具表现力的查询语言。
1.4.2 选型,本文档使用 InfluxDB 2.4
- 市场现状:目前企业里面用 InfluxDB 1.X 和 InfluxDB 2.X 都有人在用,数量上InfluxDB1.X 占多一些。
- 易用性:在开发中,InfluxDB 1.X 集成生态会比较麻烦,InfluxDB 2.X 相对来说更加便利。
- 性能:InfluxDB 1.X 和 2.X 的内核原理基本一致,性能上差距不大。
- 集群:InfluxDB 从 0.11 版本开始,就闭源了集群功能的代码。也就是说,你只能免费试用 InfluxDB 的单节点版(开源),想要集群等功能就需要购买企业版。不过就
InfluxDB 1.8 来说,有开源项目根据 0.11 的代码思路提供了 InfluxDB 开源的集群方案。也有开源项目给 InfluxDB 2.3 增加了反向代理功能,让我们可以横向拓展 InfluxDB 的服务能力。项目参考地址:
InfluxDB Cluster对应 1.8.10:https://github.com/chengshiwen/influxdb-clusterInfluxDB Proxy 对应 1.2 - 1.8:https://github.com/chengshiwen/influx-proxy InfluxDB Proxy 对应 2.3:https://github.com/chengshiwen/influx-proxy/tree/influxdb-v2 FLUX 语言支持:自 InfluxDB 1.7 和 InfluxDB 2.0 以来,InfluxDB 推出了一门独立的新的查询语言 FLUX,而且作为一个独立的项目来运作。InfluxData 公司希望 FLUX 语言能够成为一个像 SQL 一样的通用标准,而不仅仅是查询 InfluxDB 的特定语言。而且不管是你是选择 InfluxDB 1.X 还是 2.X 最终都会接触到 FLUX。不过 2.X 对 FLUX 的支持性要更好一些。 InfluxDB 产品概况:
- InfluxDB 1.8 在小版本上还在更新,主要是修复一些 BUG,不再添加新特性
- InfluxDB 2.4 这是 InfluxDB 较新的版本,仍然在增加新的特性.
- InfluxDB 企业版 1.9 需要购买,相比开源版,它有集群功能。
- InfluxDB Cloud,免部署,跑在 InfluxData 公司的云服务器上,你可以使用客户端来操作。功能上对应开源版的 2.4
- 2.x 与 1.x 的主要区别:两个版本的内核原理基本一致,性能上的差别不大。差别主要是在,权限管理方式不同,2.x TICK 的集成性比 1.x 好,1.x 中的 database 到了 2.x 中变成了 bucket 等。
最终,本课程选择 Influx 2.4 来进行教学,学会使用 InfluxDB 2.4 后应当也能胜任InfluxDB 1.7 及以上版本的开发。授课过程遇到与 InfluxDB1.8 不同的地方,会做一些提醒。
2. 安装InfluxDB(2.7)
2.1 yum安装
在 linux 环境下有两种安装方式
通过包管理工具安装,比如 apt 和 yum
- 直接下载可执行二进制程序的压缩包本课程选用第二种方式,你可以使用下面的命令下载程序包。
# 首先查看linux内核版本
cat /proc/version
# Ubuntu/Debian AMD64
wget https://dl.influxdata.com/influxdb/releases/influxdb2-2.7.1-amd64.deb
sudo dpkg -i influxdb2-2.7.1-amd64.deb
# Ubuntu/Debian ARM64
wget https://dl.influxdata.com/influxdb/releases/influxdb2-2.7.1-arm64.deb
sudo dpkg -i influxdb2-2.7.1-arm64.deb
# Red Hat/CentOS/Fedora x86-64 (x64, AMD64)
wget https://dl.influxdata.com/influxdb/releases/influxdb2-2.7.1.x86_64.rpm
sudo yum localinstall influxdb2-2.7.1.x86_64.rpm
# Red Hat/CentOS/Fedora AArch64 (ARMv8-A)
wget https://dl.influxdata.com/influxdb/releases/influxdb2-2.7.1.aarch64.rpm
sudo yum localinstall influxdb2-2.7.1.aarch64.rpm
# 安装 InfluxDB 软件包会在 at 创建一个服务文件,以便在启动时将InfluxDB 作为后台服务启动。/lib/systemd/system/influxdb.service
# 启动InfluxDB服务进程
sudo service influxdb start
# 重新启动系统并验证服务是否正常运行
sudo service influxdb status
Go 语言开发的项目一般来说会只打包成单独的二进制可执行文件,也就是解压后目录下的 influxd 文件,这一文件中全是编译后的本地码,可以直接跑在操作系统上,不需要安装额外的运行环境或者依赖
2.2 docker安装
2.2.1 下载并运行
docker run --name influxdb -p 8086:8086 influxdb:2.7.1
2.2.2 使用 Docker 配置 InfluxDB
1. 数据持久化到容器外
- 创建一个新目录以将数据存储在其中并导航到该目录。
mkdir path/to/influxdb-docker-data-volume && cd $_
- 在新目录中,运行带有标志的 InfluxDB Docker 容器 将容器内部的数据保存到当前工作目录 主机文件系统。
--volume``/var/lib/influxdb2
docker run --name influxdb -p 8086:8086 --volume $PWD:/var/lib/influxdb2 influxdb:2.7.1
2. 以配置文件形式启动
- 使用以下命令在主机文件系统上生成默认配置文件:
docker run --rm influxdb:2.7.1 influx server-config > config.yml
- 修改默认配置,改配置现在将在当前目录下可用
- 根据配置文件配置启动容器
docker run -p 8086:8086 \
-v $PWD/config.yml:/etc/influxdb2/config.yml \
influxdb:2.7.1
2.3 数据库初始化
使用浏览器访问 http://127.0.0.1:8086 ,如果是安装后的首次使用,InfluxDB 会返回一个初始化的引导界面。按照给定步骤完成操作就好
2.1.1 创建用户和初始化存储桶
点击 GET STARTED 按钮,进入下一个步骤(添加用户)。如图所示,你需要填写、组织名称、用户名称、用户密码

2.2.2 配置完成
看到如图所示的页面,说明我们已经开始使用 tony 这一用户身份和 InfluxDB 交互了。
3.web页面功能分析
3.1 LoadData
**`InfluxDB` 是一个无模式的数据库,也就是除了在输入数据之前需要显示创建存储桶(数据库),你不需要手动创建 measurement 或者指定各个 field 都是什么类型,你甚至可以前后在同一个 measurement 下插入 filed 不同的数据。**
3.1.1 CSV导入数据
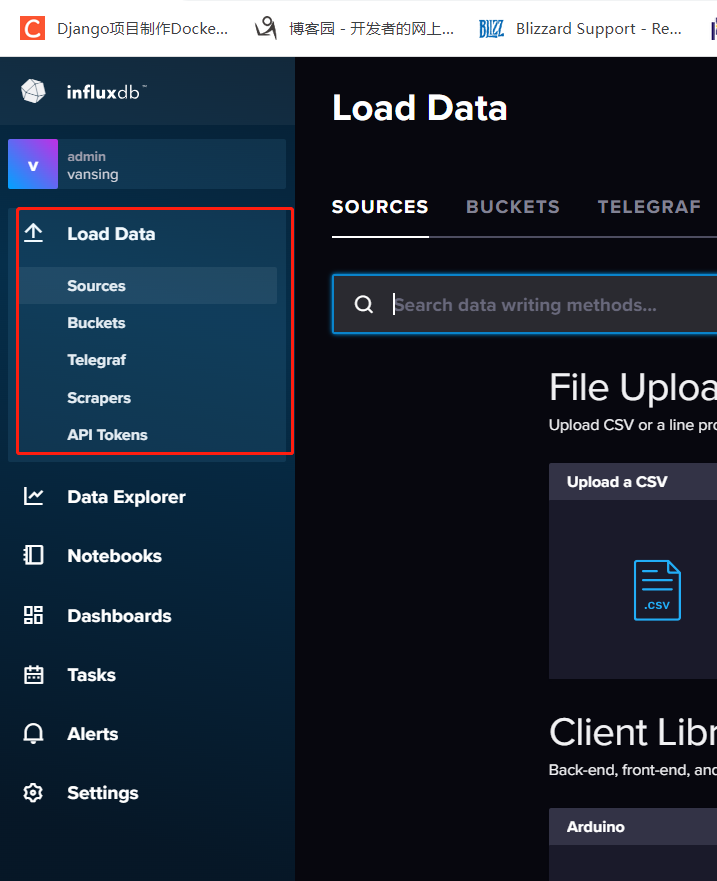
csv文件上传
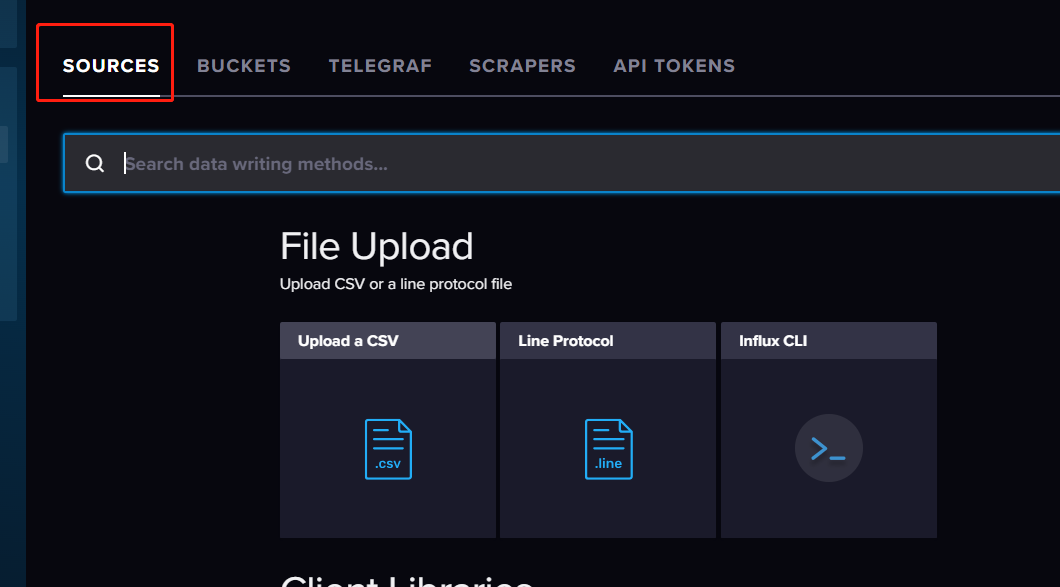
点击sources,来上传 scv 文件
3.1.2 行协议文件导入数据
基于遵循行协议的文件数据格式来导入数据到InfluxDB中,如下,行协议见:8.行协议数据格式
people,name=tony age=12
people,name=xiaohong age=13
people,name=xiaobai age=14
people,name=xiaohei age=15
people,name=xiaohua age=12

写入成功画面
3.1.3 客户端代码模版
第二部分就是各个语言的客户端代码模版

3.1.4 Telegraf 数据采集插件
**第三部分就是Telegraf的插件,Telegraf 是一个插件化的数据采集组件,在这里你可以找一下没有对应你的目标数据源的插件,点击它的 logo。可以看到这个插件配置的写法,但是关于这方面的内容,还是建议参考 Telegraf 的官方文档,那个更细更全一些 **

3.1.3 Telegraf导入数据
点击 Load Data 页面的 TELEGRAF 选项卡,可以快速生成一些 Telegraf 配置文件。并向外暴露一个端口,允许 telegraf 远程使用 InfluxDB 中生成的配置
什么是Telegraf
Telegraf 是 InfluxDB 生态中的一个数据采集组件,现在,很多时序数据库都支持与 Telegraf进行协作,不少类似的时序数据收集组件选择在 Telegraf 的基础上二次开发。如:有很多的服务器,每个服务器上都有一个Telegraf服务采集服务器的各项数据,InfluxDB会对外暴露一个URL,各个Telegraf 就可以向这个URL 提交数据,直接写入InfluxDB中保存
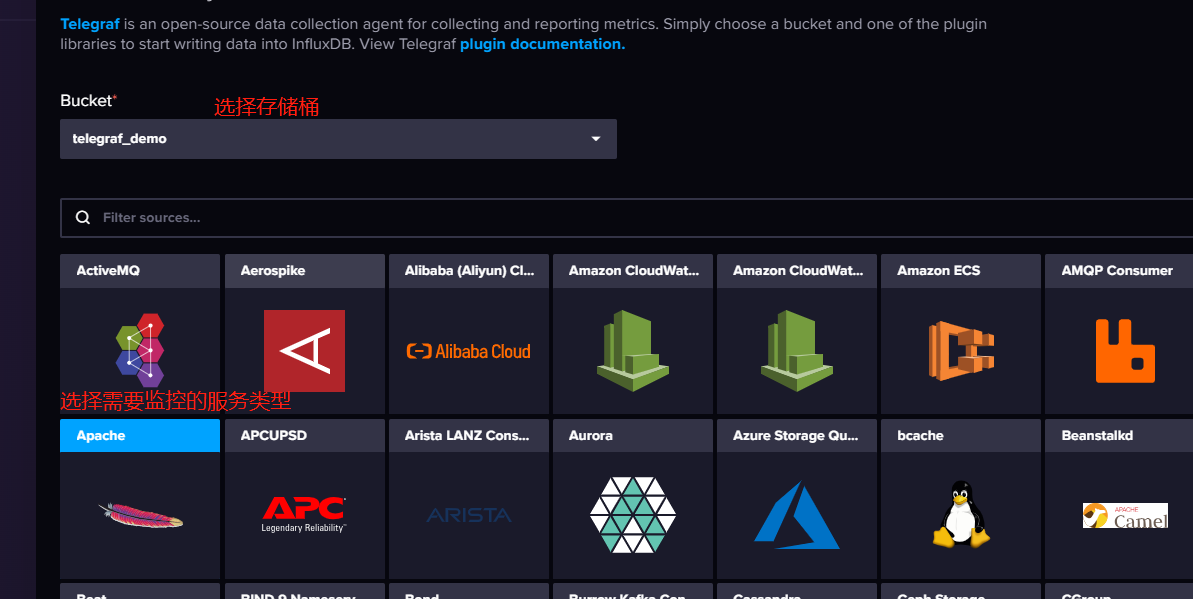
创建Telegraf配置文件
InfluxDB 的 Web UI为我们提供了几种最常用的telegraf 配置模板,包括监控主机指标、云原生容器状态指标,nginx 和 redis 等。点击 CREATE CONFIGURATION
填写配置文件名
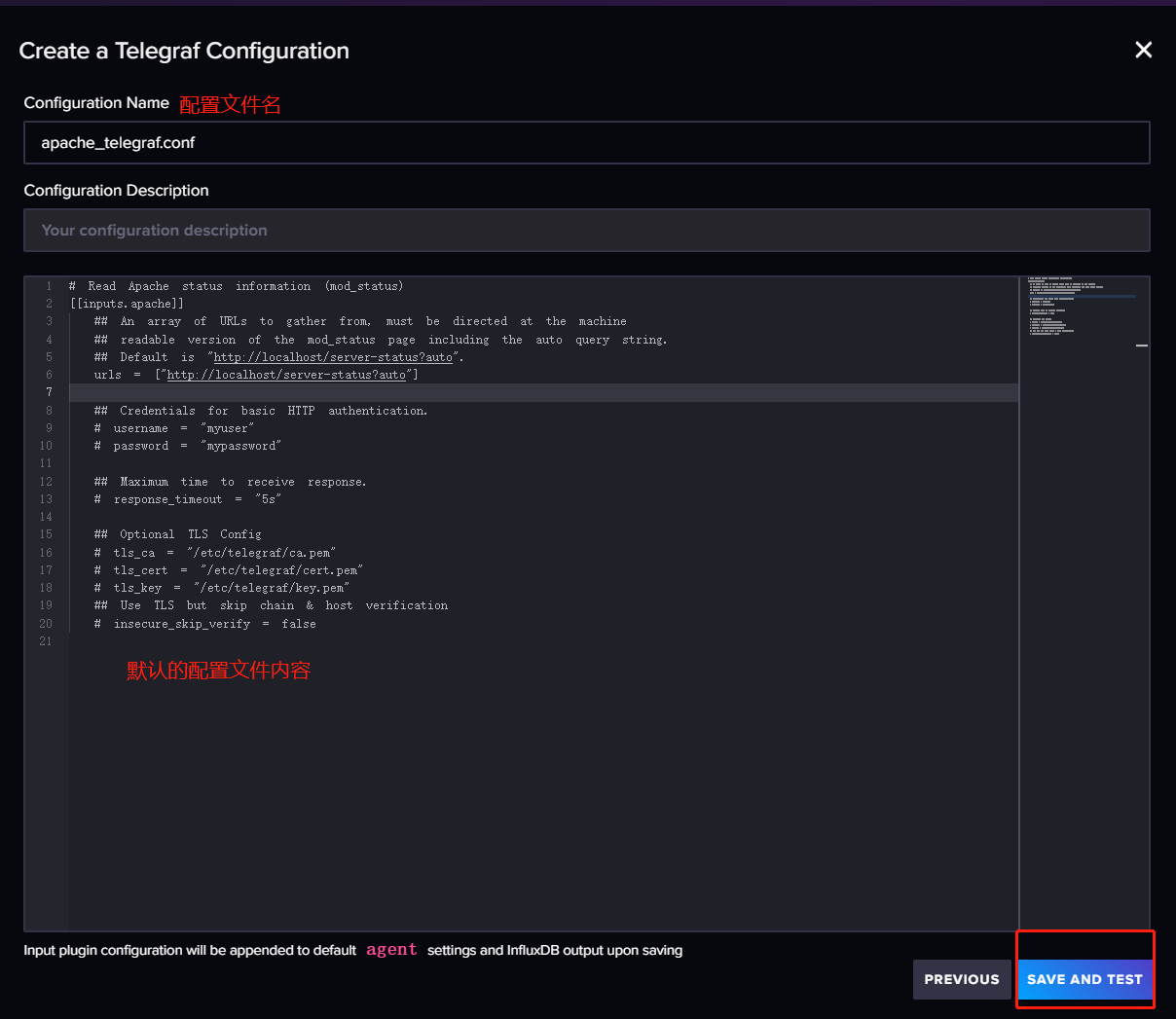
会出现步骤提示页,然后一步一步配置即可
管理 Telegraf 配置文件接口
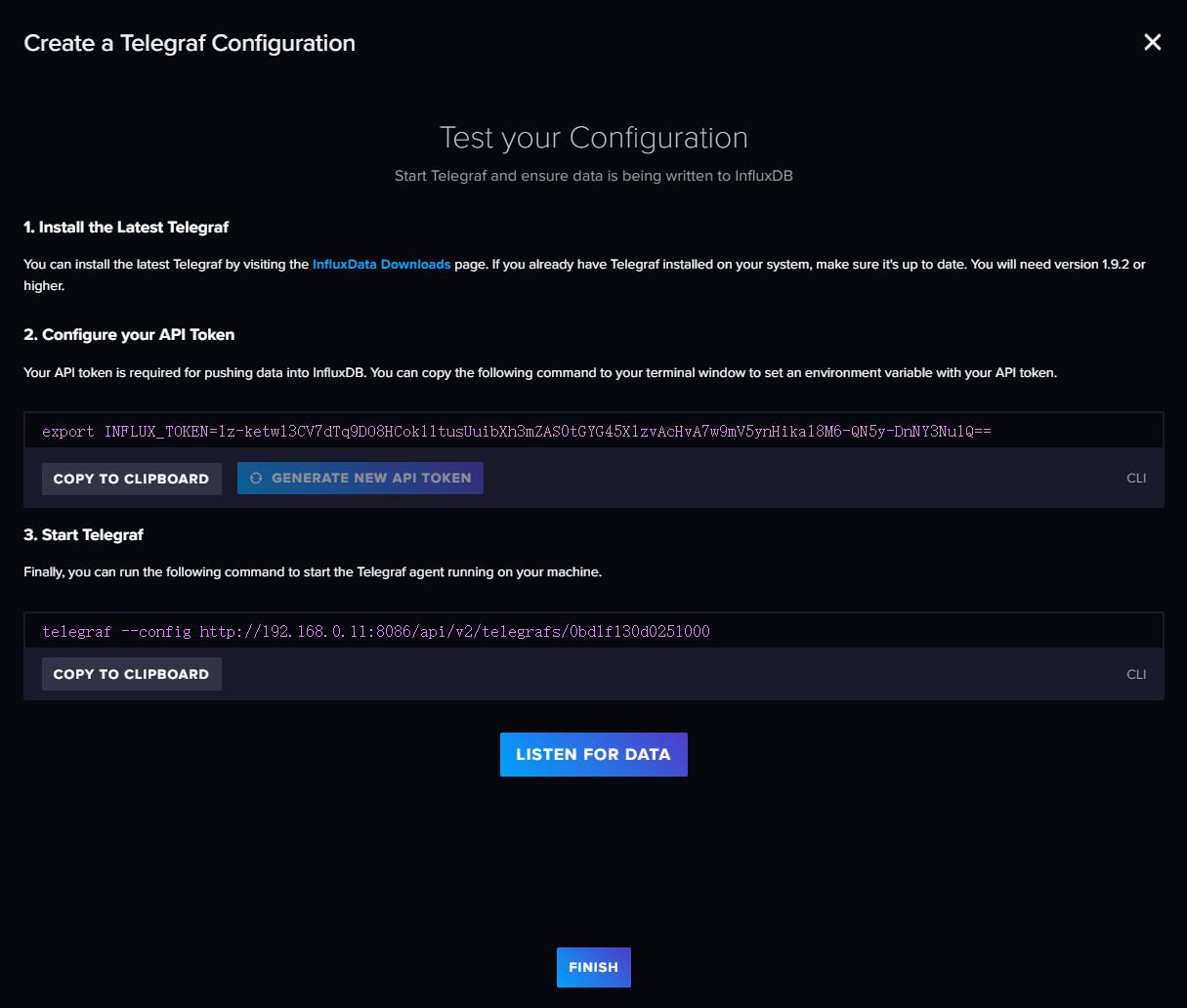
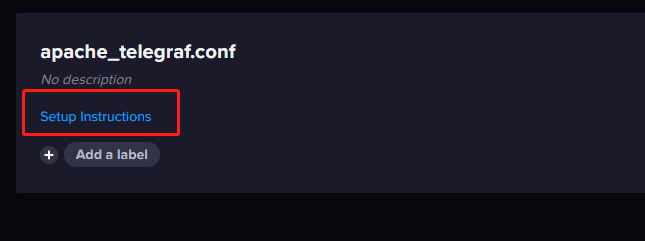
完成Telegraf 的配置后,页面上会多出一个关于 telegraf实例的信息卡。如图所示:

点击 Setup Instructions会弹出一个对话框,引导你完成 telegraf 的配置。可以看到第三步的命令。
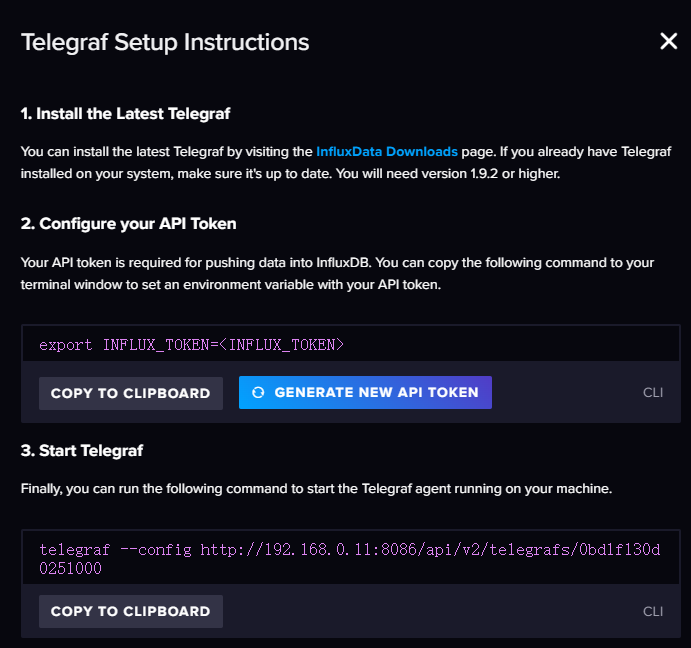
telegraf --config http://localhost:8086/api/v2/telegrafs/09dc7d49c444f000
这个命令中有一个 URL,其实意思也就是 InluxDB 向外提供了一个 API,通过这个API 你可以访问到刚才生成的配置文件
修改 Telegraf 配置
已经生成的配置文件如何去修改呢?你可以点击卡片的标题
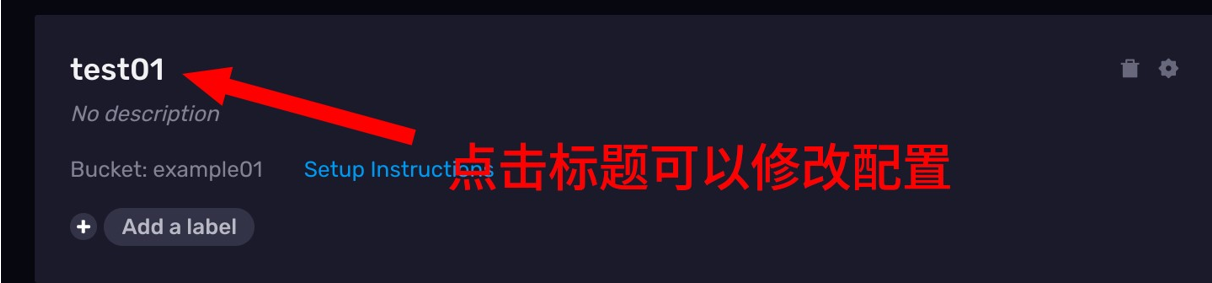
这个时候,会弹出一个配置文件的编辑页面,不过这个时候没有交互式的选项了,你需要自己直接面对配置文件

修改完配置文件后,记得点击右方的 SAVE CHANGES 保存修改
示例: 使用Telegraf采集服务器信息
使用 Telegraf 将数据收集到InfuluxDB
在本示例中,我们会使用 Telegraf 这个工具将一台机器上的 CPU 使用情况转变成时序数据,写到 InfluxDB 中
1. 下载Telegraf
可以使用下面的命令下载 telegraf
wget https://dl.influxdata.com/telegraf/releases/telegraf-1.23.4_linux_amd64.tar.gz
2. 解压压缩包
解压到目标路径
tar -zxvf telegraf-1.23.4_linux_amd64.tar.gz -C /opt/module/
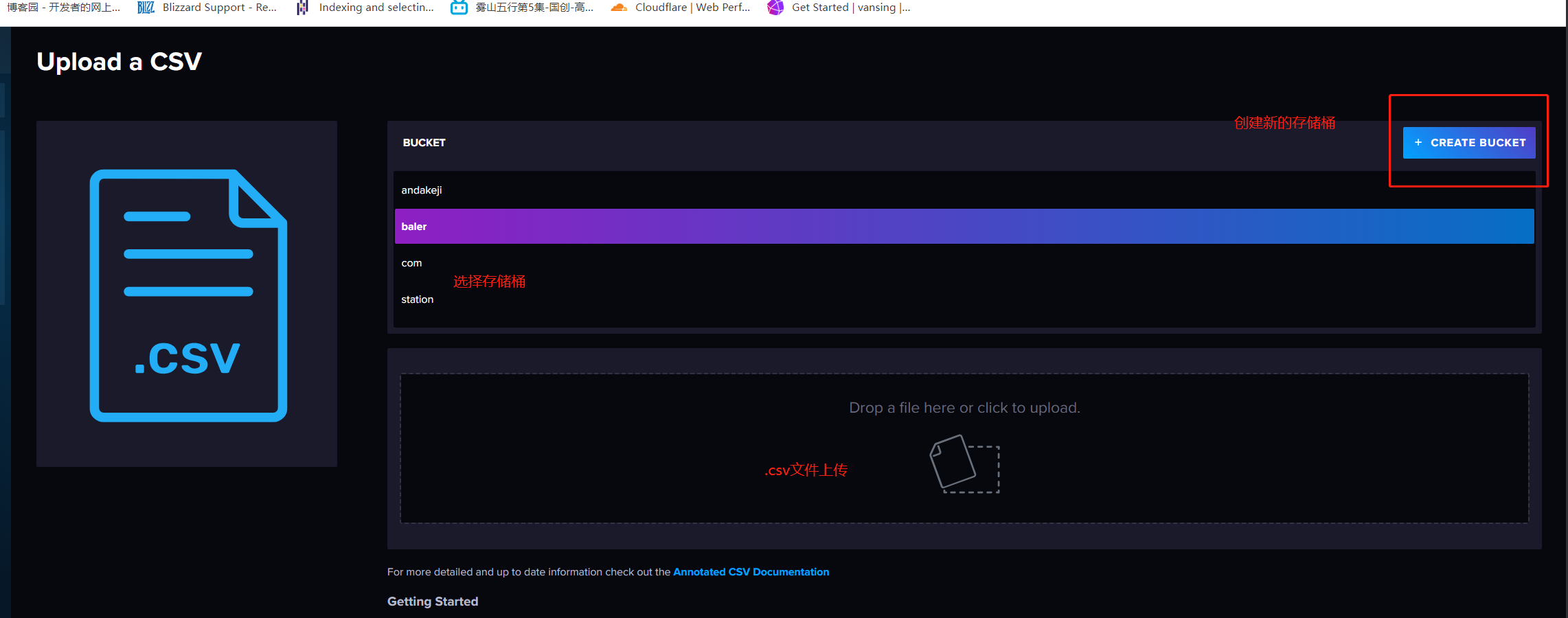
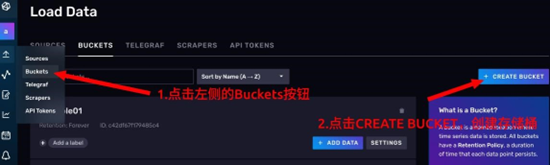
3. 创建一个新的 Bucket
- 点击左侧工具栏中的 Buckets 按钮
- 点击右侧蓝色的 CREATE BUCKET 按钮
- 创建一个名为
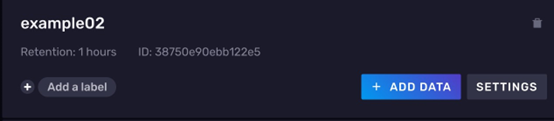
example02的buckets,因为是演示,所以这里将过期时间设为 1小时。设置好后点击CREATE

- 如果出现相应的
example02的卡片,说明存储桶已经创建成功。
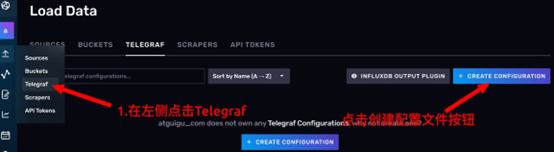
4. 创建 Telegraf 配置文件
- 在左侧的工具栏上点击
Telegraf按钮。 - 点击右侧蓝色的
CREATE CONFIGURATION创建telegraf配置文件
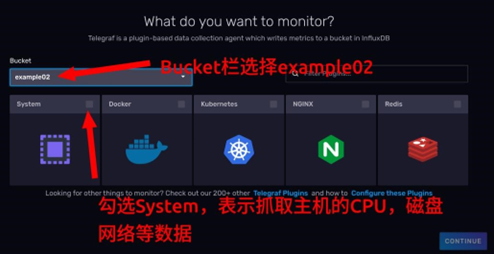
- 在
Bucket栏选择example02,表示让telegraf将抓取到的数据写到example02存储桶中,下面的选项卡勾选System。点击CONTINUE
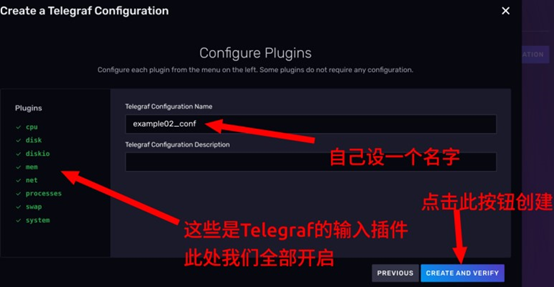
- 点击
CONTINUE按钮后,会进入一个配置插件的页面。你可以自己决定是否启用这些插件。这里需要给生成的Telegraf配置起一个名字,方便管理。
- 点击
CREATE AND VERIFY按钮,这个时候其实Telegraf的配置就已经创建好了,你会进入一个Telegraf的配置引导界面,如图所示:
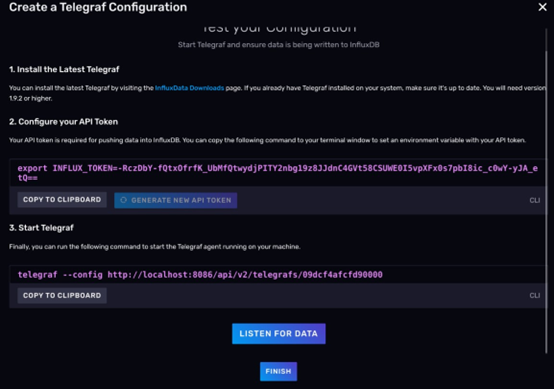
5. 声明Telegraf 环境变量
按照 Web UI上的建议,首先,你要在部署 Telegraf 的主机上声明一个环境变量叫 INFLUX_TOKEN,它是用来赋予 Telegraf 向 InfluxDB 写数据权限的。这里我们就不配环境变量了,请在单一的 shell 会话下完成后面的操作。所以到你下载好Telegraf的机器上,执行下面的命令。(注意!TOKEN是随机生成的,请按照自己的情况修改命令)
export INFLUX_TOKEN=v4TsUzZWtqgot18kt_adS1r-7PTsMIQkbnhEQ7oqLCP2TQ5Q-PcUP6RMyTHLy4IryP1_2rIamNarsNqDc_S_eA==
6. 启动Telegraf
首先 cd 到我们解压的 telegraf 目录。
cd /opt/module/telegraf-1.23.4
telegraf 的可执行文件在 telegraf的./usr/bin 目录下。
cd ./usr/bin
从 Web UI 中复制运行 telegraf 的命令,修改 host然后执行,当前示例的telegraf和InfluxDB 在同一台机器上,所以可以使用 localhost。最终命令如下
telegraf --config http://localhost:8086/api/v2/telegrafs/09dcf4afcfd90000telegraf
7. 运行效果如下图所示。
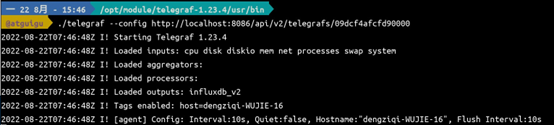
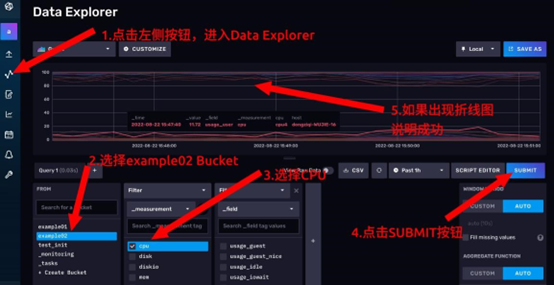
**8. 验证数据采集结果 **
- 点击左侧按钮进入 Data Explorer 页面。
- 在左下角第一个选项卡选择 example02,表示要从 example02 这个存储桶中查数据
- 点击好第一个选项卡后,会自动弹出第二个选项卡,勾选 cpu。
- 点击右上方的 SUBMIT 按钮。
- 如果出现折线图,说明我们成功地使用 Telegraf 把数据导进来了
9. 编写启停脚本
**编写一个 shell 脚本来管理 telegraf 任务。 **
- 首先 cd 到~/bin 路径下,如果~路径下没有 bin,就创建 bin 这个目录。通常,~/bin 是 PATH 环境变量包含的一个目录。
cd ~
mkdir bin
cd ~/bin
- 到~/bin 路径下创建一个文件 host_tel.sh
vim host_tel.sh
- 键入如下内容
#!/bin/bash
is_exist(){
pid=`ps -ef | grep telegraf | grep -v grep | awk '{print $2}'`
# 如果不存在返回1,存在返回0
if [ -z "${pid}" ]; then return 1 else return 0
fi
} stop(){ is_exist if [ $? -eq "0" ]; then kill ${pid} if [ $? -eq "0" ]; then echo "进程号:${pid},弄死你"
else
echo "进程号:${pid},没弄死" fi
else
echo "本来没有telegraf进程"
fi
} start(){ is_exist
if [ $? -eq "0" ]; then echo "跑着呢,pid 是${pid}" else
export INFLUX_TOKEN=v4TsUzZWtqgot18kt_adS1r-
7PTsMIQkbnhEQ7oqLCP2TQ5Q-PcUP6RMyTHLy4IryP1_2rIamNarsNqDc_S_eA== /opt/module/telegraf-1.23.4/usr/bin/telegraf --config http://localhost:8086/api/v2/telegrafs/09dcf4afcfd90000 fi
} status(){ is_exist
if [ $? -eq "0" ]; then echo "telegraf跑着呢" else
echo "telegraf没有跑"
fi
}
usage(){
echo "哦!请你start或stop或status" exit 1
} case "$1" in "start")
start ;;
"stop") stop ;;
"status") status
;;
*) usage ;;
esac 最后
- 最后给这个脚本加上一个执行权限,你可以执行下面的代码。
chmod 755 ./host_tel.sh
总结
InfluxDB只是帮你管理了一下Telegraf的配置文件。InfluxDB并不能管理Telegraf的启停和运行状态。如何运行Telegraf还是需要开发者手动或者编写脚本来维护的。- 通过配置
Telegraf,生成一个配置文件,存储在InfluxDB中,并将配置文件暴露一个URL给Telegraf来访问 - 可以通过
InfluxDB中来在线的修改配置文件的内容,但是想要生效,需要手动的重启Telegraf来重新读取配置文件的内容
3.1.4 Buckets管理存储桶
存储桶首页信息
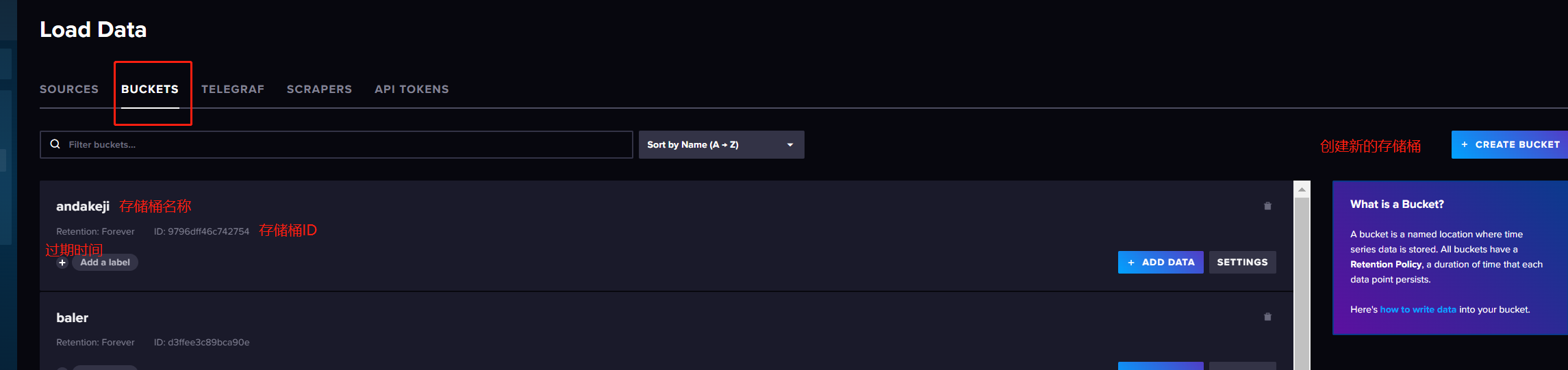
CREATE BUCKET 创建新的存储桶并配置过期时间,0s表示为永不过期
ADD DATA 添加数据到存储桶中
SETTINGS 修改存储桶的配置,如:名字是无法被修改的.过期时间
Add a label 给存储桶添加一个标签,一般不会这样做
3.1.5 Scrapers管理抓取任务
什么是抓取任务
抓取任务就是你给定一个 URL,InfluxDB 每隔一段时间去访问这个链接,把访问到的数据入库,在 InfluxDB 1.x 的时候,类似的任务只能由 Telegraf 来实现。在 InfluxDB 2.x 中,内置了抓取功能(但是定制性上不如 Telegraf,比如轮询间隔只能是 10 秒)

**另外,目标 URL 暴露出来的数据格式必须得是 `Prometheus` 数据格式。关于`Prometheus` 数据格式的详细介绍参考本文档的 9.`Prometheus` 数据格式**
InfuluxDB 自身暴露的监控接口
可以访问 http://localhost:8086/metrics 来查看 InfluxDB 暴露出来的性能数据。这里面有,InfluxDB 的 GC 情况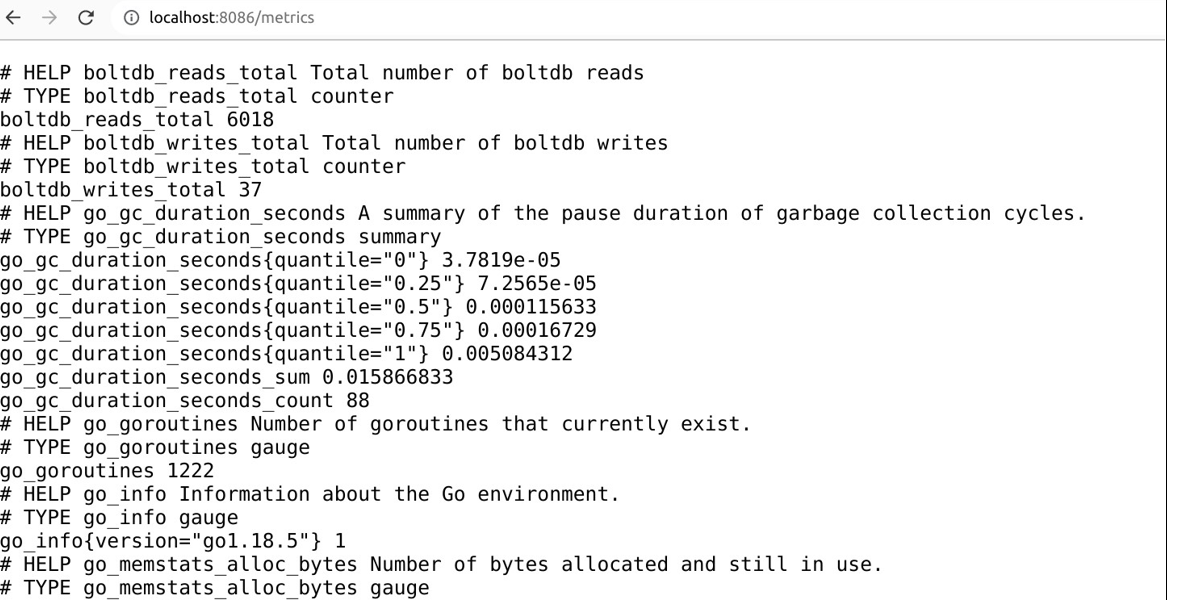
以及各个 API 的使用情况,如图所示,说的是各个 API 被谁请求过多少次。

示例1: node_exporter,监控主机性能数据
1.下载node_exporter
https://prometheus.io/download/#node_exporter
2.将文件拖进linux中,并解压文件
tar -zxvf node_exporter-1.6.1.linux-arm64.tar.gz
3.执行
cd node_exporter-1.6.1.linux-arm64/
./node_exporter
示例2: 让 InfluxDB 主动拉取自己的GC数据
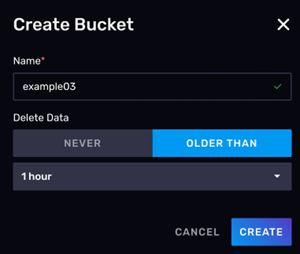
**创建新的存储桶 **
如图所示,我们创建了一个名为 example03 的存储桶。数据的过期时间设为 1 小时。
创建抓取任务
- 进入抓取任务的管理页面
- 点击
CREATE SCRAPER按钮,创建抓取任务
- 在对话框上,给抓取任务起一个名字,此处命名为
example03_scraper - 右方的下拉框上,选择我们刚才创建的存储桶,
example03。 - 最下方设置一下目标路径,最后点击
CREATE
- 如果页面上出现新的卡片,说明配置成功。接下来去看一下数据有没有进来

验证抓取结果
- 点击左侧的按钮,打开 Data Explorer
- 在左下角第一个卡片选择要从哪个存储桶抽取数据,本例对应的是 example03
- 第一个卡片选择好后,会自动弹出第二个卡片,你可以选择任意一个指标名称。
- 点击右侧的 SUBMIT 按钮,提交查询。
- 如果折线图成功加载,说明有数据了,抓取成功!

注意事项
InfluxDB的监控数据默认会被抓取到初始化的存储桶中 ,抓取任务管理面板上,我们发现自己还没创建什么东西呢,就有一个抓取任务
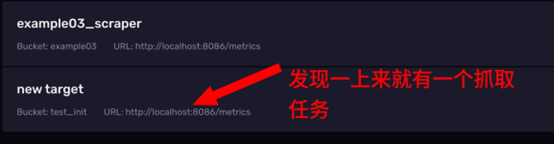
这个抓取任务是 InfluxDB 自动为我们创建的,它会把我们刚才访问/metrics 拿到的数据写到 test_init 这个存储桶中去,而 test_init 这个存储桶是我们首次登录的时候为了初始化而创建的。所以大家要知道 test_init 中的一些监控数据是怎么产生的
InfluxDB的抓取任务都是 10 秒一次,无法自定义设置 ,至少截至目前(2.4 版本),用户无法去自定义抓取间隔。InfluxDB会每隔 10 秒一次去抓取数据,这一点需要注意。
3.1.6 API Token管理 Token
注意!InfluxDB 的 Token 是可以进行更细的管理的,Web UI 上给的只是生成 Token 的模板,准备了用户的常用需求,但不代表它的全部功能。
点击左侧的 API Tokens 按钮,进入 API Token 的管理页面。
API Token是干什么用的
简单来说,`influxdb` 会向外暴露一套 `HTTP API`。我们后面要学的命令行工具什么的,其实都是封装的对 `influxdb` 的 `http `请求。所以,在 `InfluxDB` 中,对权限的管理主要就体现在` API` 的 `Tokens` 上。客户端会将 `toke`n 放到 `http `的请求头上,`influxdb` 服务端就根据客户端发来的请求头部的 token,来判断你能不能对某个存储桶读写,能不能删除存储桶,创建仪表盘等。
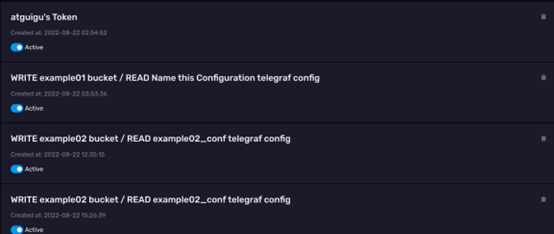
**查看 API Token **
截至目前,还没有自己手动创建过 `API Token`。但是可以看到页面上已经有一些`Token` 了,这些 `Token` 是由我们之前示例里面的操作自动生成的。
了解 tony's Token
现在,我们围绕着 `InfluxDB` 中已有的 `Token` 来学习相关的知识,我们的 `InfluxDB` 上现在只有初始化时创建的 tony 账户,在 `Token` 列表中,我们可以看到有一个名为 `tony's Token` 的 `token`。
修改token 的名称
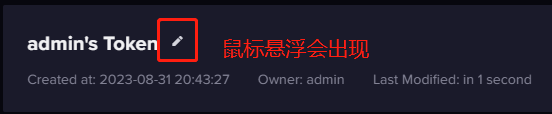
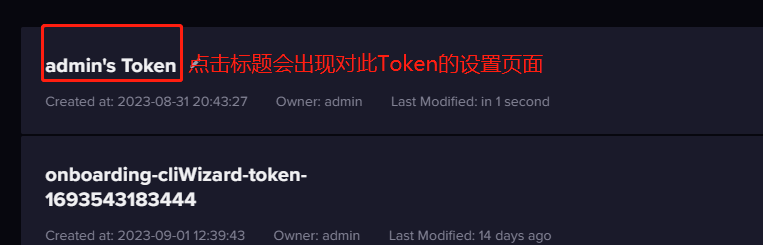
- 没有客户端会用 token 的名称来调用 token,所以修改 token 名称不会影响已经部署的应用。
InfluxDB从未要求 token 的名称必须全局唯一,所以名称重复也是可以的。
**token 可以临时关停、也可以删除 **
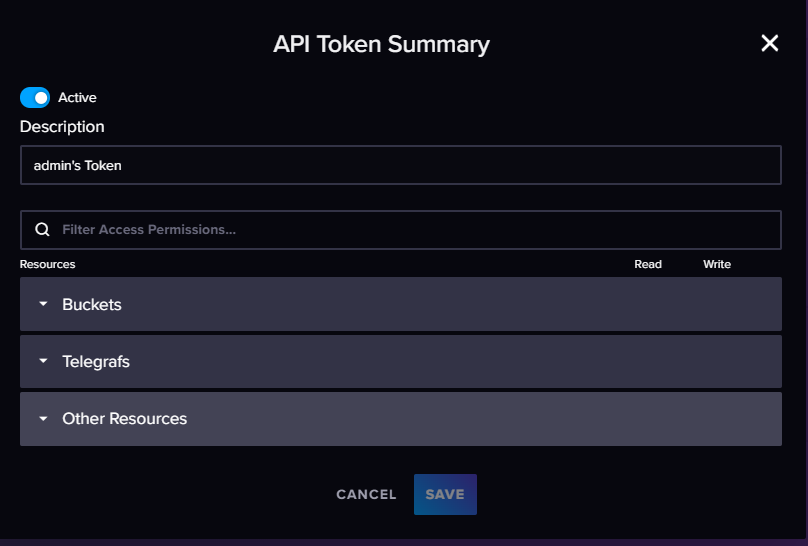
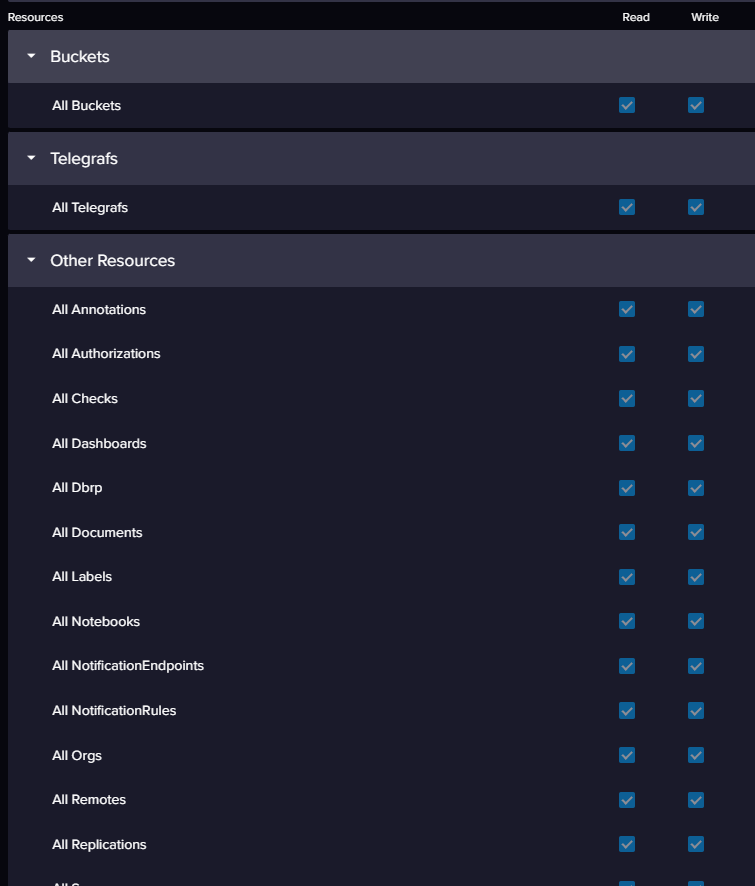
token 对buckets的权限
创建 API Token
页面的右方有一个GENERATE API TOKEN。点一下会出来一个下拉菜单,这其实是Web UI上的权限模板
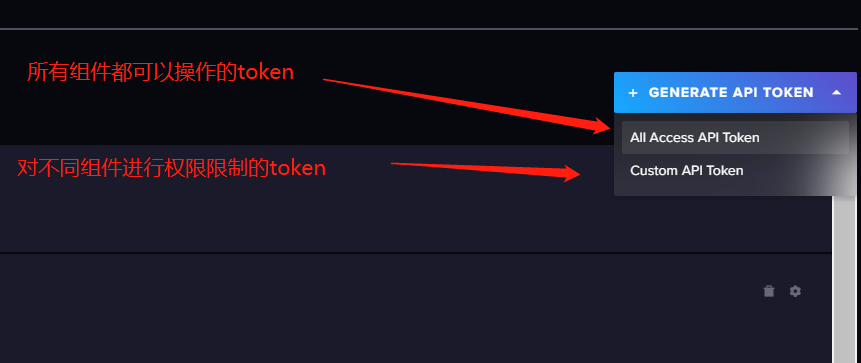
3.2 Data Explorer
可以将 Data Explorer 的界面简单分为两个区域,上半部分为数据预览区,下半部分为查询编辑区
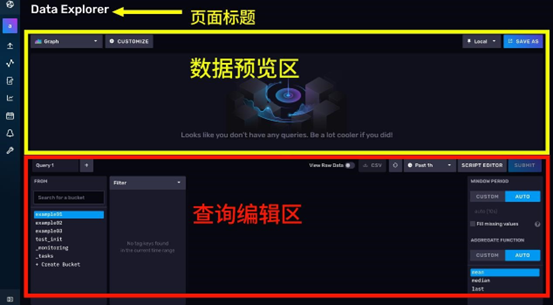
查询编辑区
查询编辑区为你提供了两种查询工具,一个是查询构造器,一个是 FLUX 脚本编辑器。
3.3.1.查询构造器
一进入 Data Explorer 页面,默认会打开查询构造器。使用查询构造器,你可以通过点按的方式完成查询。它背后的原理其实是根据你的设置,自动生成一条 FLUX 语句,提交给数据库完成查询
能够出现查询构造器这种东西,说明时序数据的查询之间遵循着某种规律。不同业务之间的查询步骤可能高度相似

3.3.2 FLUX脚本编辑器
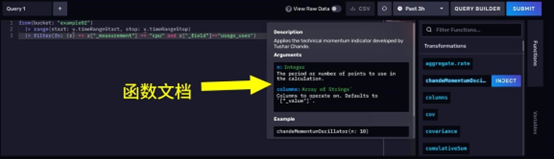
你可以手动将查询构造器切换为FLUX脚本编辑器。然后愉快地编写 FLUX 脚本,实现各种奇葩查询。编辑器十分友好,还带自动提示和函数文档
3.3.3 数据预览区
数据预览区可以将你的数据展示出来。下图是一个效果图
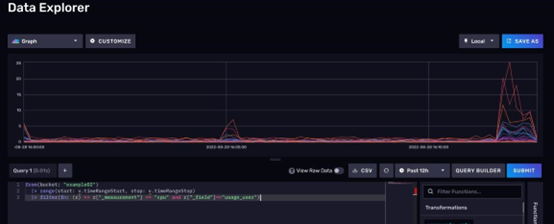
默认情况下,数据预览区会将你的数据展示为一个折线图。不过除此之外,你还可以让数据展示为散点图、饼图或者查看原始数据等等
3.3.4 其他功能
除了查询和展示数据的功能外,Data Explorer 还有一些拓展功能
- 将当前查询和可视化效果保存为仪表盘的一个单元
- 你可以将当前的查询逻辑和图形展示保存为某个仪表盘的一部分。这个功能需要在查询逻辑已经实现的前提下,点击右上角的 SAVE AS 触达。


- 创建定时任务
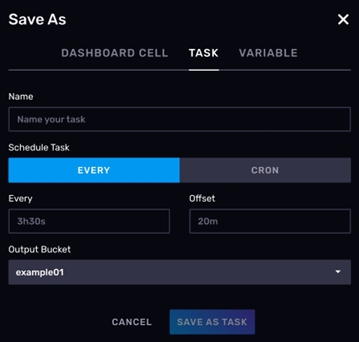
Data Explorer 中的查询逻辑可以保存为一个定时任务,也就是 TASK。这里提前说一下 InfluxDB 中的 TASK 是什么。TASK 其实是一个定时执行的 FLUX 语言写的脚本。因为 FLUX 是一个脚本语言,所以它其实有一定的 IO 能力。可以使用 http 与外面的系统进行通信,还可以将计算完的数据回写给 InfluxDB。所以通常 TASK 有两种使用场景。
- 数据检查与报警。对查询后的结果进行一下条件判断,如果不合规,就使用 http 向外通知报警。
- 聚合操作。在 InfluxDB 里开窗完成聚合计算,计算后的数据再写回到 InfluxDB,这样下游 BI(数据看板)可以直接去查询聚合后的数据了,而不是每次都把数据从 InfluxDB 里拉出来重新计算。这样可以减少 IO,不过会增加 InfluxDB 的压力。生产环境下需要根据实际情况进行取舍。
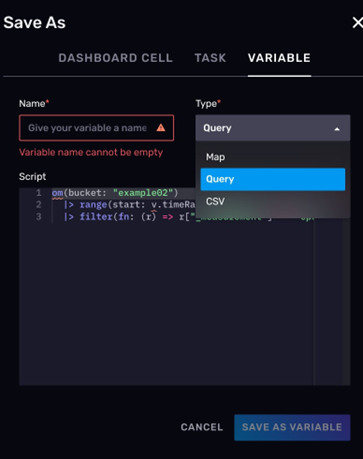
- 定义全局变量
在 DataExplorer 里,你可以声明一些全局变量。全局变量的类型可以是 Map(键值对)、CSV 和 FLUX 脚本。这样,将来你可以直接引用这些变量,比如你的数据里有地区编码。你就可以将编码到地区名称的映射保存为一个全局 Map,供以后每次查询时使用。
3.3.5 示例:在Data Explorer使用查询构造器进行查询和可视化
- 点击左侧的按钮,进入Data Explorer 页面
- 设置查询条件
我们现在要查询的是 test_init 存储桶下的 go_goroutines 测量,这个测量反应的是我们InfluxDB 进程中的 goroutines(轻量级线程)数量。
首先,在左下角的查询构造器的 FROM 选项卡,选择 test_init 存储桶
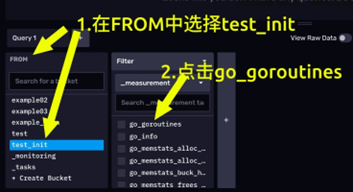
接着会弹出一个 Filter 选项卡,默认情况下这里是选择_measurement,此处 我们选择 go_goroutines。
- 注意查询时间范围
右上角有一个带时钟符号的下拉菜单,这个菜单可以帮你纵向选择要查询数据的时间范围,通常默认是 1h。如下图所示:
- 注意右侧的窗口聚合选项
在查询构造器的最右边,有一个开窗聚合选项卡。使用查询构造器进行查询,就必须使用开窗聚合。默认情况下,DataExplorer 会根据你设置的查询时间范围,自动调整窗口大小,此处查询范围 1h 对应窗口大小 10s。同时,聚合方式默认是平均值。
- 提交查询
点击右侧的 SUBMIT 按钮可以立刻提交查询。之后,数据展示区会出现相应的折线图。如下图所示:
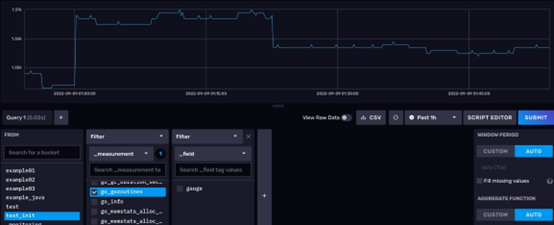
点击 View Raw Data,可以看到原始数据

- 查询原理
我们使用查询构造器进行查询,其实是 Web UI 根据我们指定的查询条件生成了一套
FLUX 查询脚本。点击 SCRIPT EDITOR 按钮,可以看到查询构造器生成的 FLUX 脚本
- 可视化原理
其实默认情况下的可视化,是依据返回数据中的_value 来展示的,但是有些时候,你想查询的数据可能字段名不会被判别为_value。它会安静地躺在原始数据中。

3.3 Notebooks
3.3.1 什么是Notebook
Notebook 是 InfluxDB2.x 推出的功能,交互上模仿了 Jupyter NoteBook。它可以用于开发、文档编写、运行代码和展示结果。
你可以将 InfluxDB 笔记本视为按照顺序处理数据的集合。每个步骤都由一个“单元格”表示。一个单元格可以执行查询、可视化、处理或将数据写入存储桶等操作。Notebook 可以帮你完成下述操作
- 执行 FLUX 代码、可视化数据和添加注释性的片段
- 创建报警或者计划任务
- 对数据进行降采样或者清洗
- 生成要和团队分享的 Runbooks
- 将数据回写到存储桶
Notebook 和 DataExplorer 相比,主要是交互风格上的不同。DataExplorer 倾向于一锤子买卖,而 Notebook 可以将数据展示拆分为一个又一个具体的步骤。另外,NoteBook 可以用来开发告警任务 DataExplorer 则不能
3.3.2 进入Notebook的导航页面
点击左侧的Notebooks按钮,即可进入 Notebook 的导航页面。
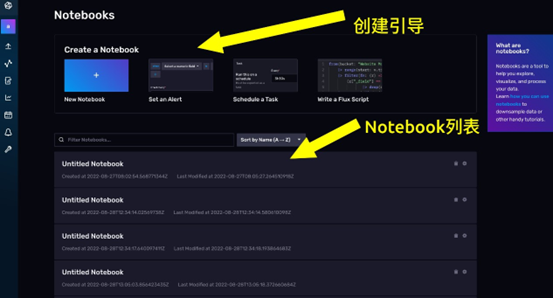
- 上面是创建引导,除了创建一个空白的 Notebook,InfluxDB 还为你提供了 3 个模板。分别是 Set an Alert(设置一个报警)、Schedule a Task (调度一个任务)、write a Flux Script(写一个 Flux 脚本)。
- 下面是 Notebook 列表,过去你创建过的 NoteBook 再这里都会展示出来。

卡片上还有这个 Notebook 对应的创建时间和修改时间。通过卡片你可以对一个Notebook 重命名,还可以将它复制和删除。
3.3.3. 创建一个空白的 notebook
想要继续后面的步骤,我们必须先创建一个 Notebook。如下图所示,在页面上方点击New Notebook 按钮即可
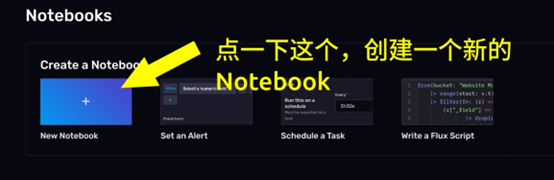
现在,你看到的就是 Notebook 的操作页面了。

3.3.4 NoteBook 工作流
目前看到的页面应当是如下图所示的样子:
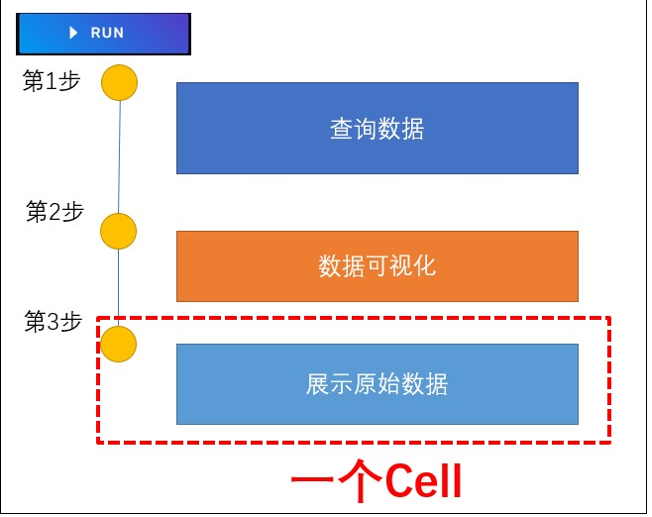
我们在页面中看到的一个又一个卡片,在 NoteBook 中叫做 Cell。一个 NoteBook 工作流就是多个 Cell 按照先后顺序组合起来的执行流程。这些 Cell 中间随时可以插入别的 Cell,而且 Cell 和 Cell 还可以调换顺序。
按照 Cell 功能,Cell 可以按照下面的方式分类。

- 数据源相关的 Cell
- 查询构造器
- 直接编写 FLUX 脚本
- 可视化相关的 Cell
- 将数据展示为一个 Table
- 将数据展示为一张图
- 添加笔记。
- 行为 Cell
- 进行报警
- 定时任务设定
3.3.5 工作流范式
在 NoteBook 里编写工作流通常是有套路可循的
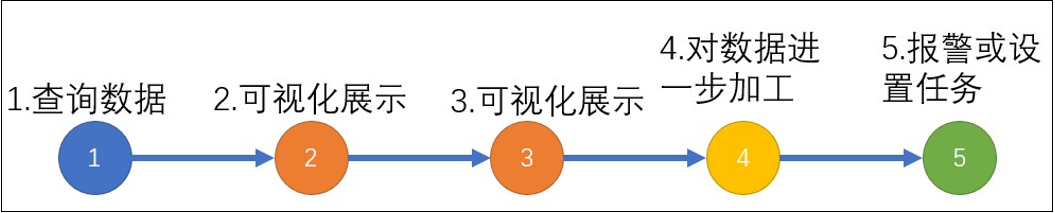
通常一个 notebook 工作流以查询数据开始,后面的 Cell 跟上把数据展示出来,当数据需要进一步修改的时候,可以再加一个 FLUX 脚本 cell,notebook 为我们留了一个接口,通过这种方式,后面的 Flux cell 可以将前面的数据作为数据源进行查询。
最终,notebook 工作流可以以任务设置或者报警操作作为整个工作流的终点,当然这不是强制要求
3.3.6 NoteBook 控件
在 notebook 上存在下述几种控件
- 时区转换
右上角有一个 Local 按钮,通过这个按钮,你可以选择将日期时间显示为系统所设时区还是 UTC 时间。

- 仅显示可视化
点击 Presentation 按钮,可以选择是否仅显示数据展示的 cell。如果开启这个选项,那么查询构造器和 FLUX 脚本的 Cell 就会被折叠。

- 删除按钮
点击确定后,可以删除整个 notebook。

- 复制按钮
右上角的复制按钮可以立刻为当前 NoteBook 创建一个副本。

- 运行按钮
RUN 按钮可以快速地执行 Notebook 中的查询操作并重新渲染其中的可视化 Cell。
示例 :使用 NoteBook 查询和可视化数据
1. 使用查询构造器记性查询
默认情况下,你创建的空白 NoteBook,自带 3 个 cell。
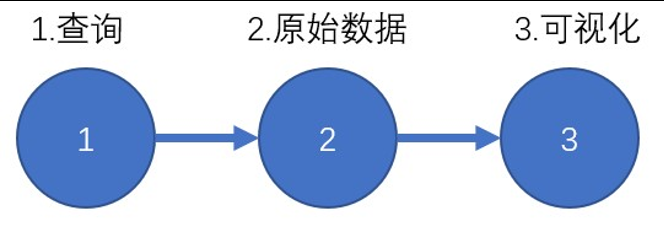
- 第一个 cell,默认是一个查询构造器,相对于 DataExplorer 来说,notebook 的查询构造器不同的地方在于它没有开窗聚合操作。此处,同样还是查询 test_init 中的 go_goroutines 测量。
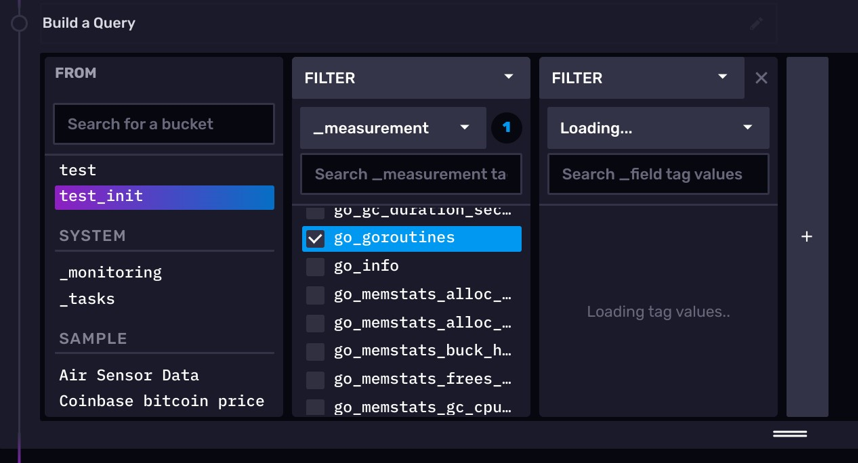
2. 提交查询
- 点击 RUN 按钮。

可以看到下面的原始数据和折线图都出现了

3. 添加说明 cell
notebook 允许用户在工作流中加入说明性的 cell。我们选择在最前面加一个说明性 cell。
首先,点击左侧的紫色+号。
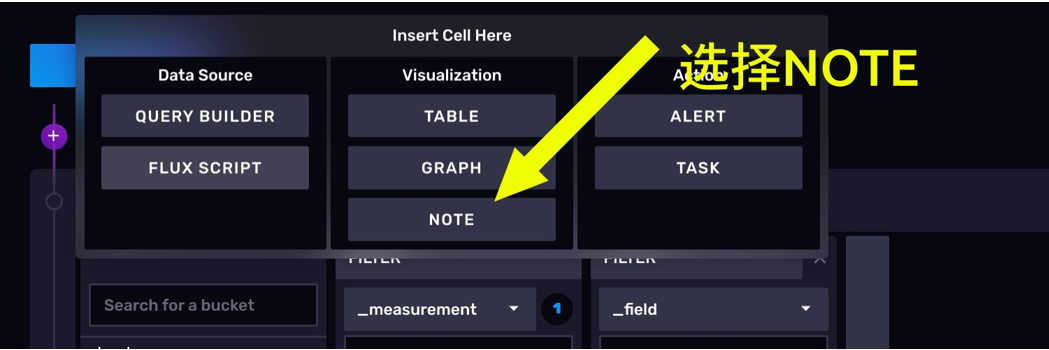
点击 NOTE 按钮。可以看到,我们已经创建了一个说明 cell。这里面还支持MarkDown 语法,

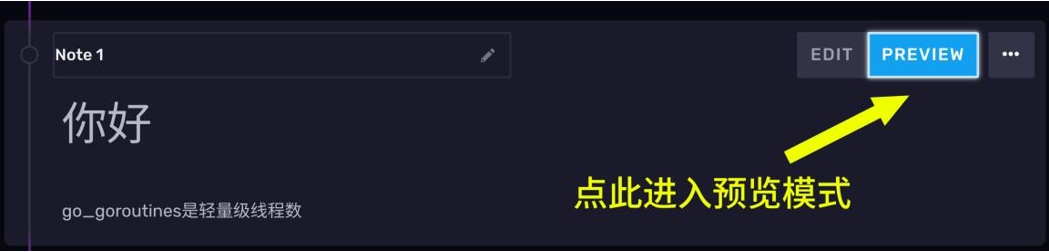
现在,我们随便写点东西

点击右上右上角的 PREVIEW 按钮,markdown 就会被渲染展示。
3.4 组织
3.4.1 组织管理
3.4.2 创建组织
创建新组织后,只能看到当前组织下的存储桶,telegraf脚本,仪表盘,tokens等,但是InfluxDB 刚开始初始化的用户是本服务的顶级权限,可以跨组织操作
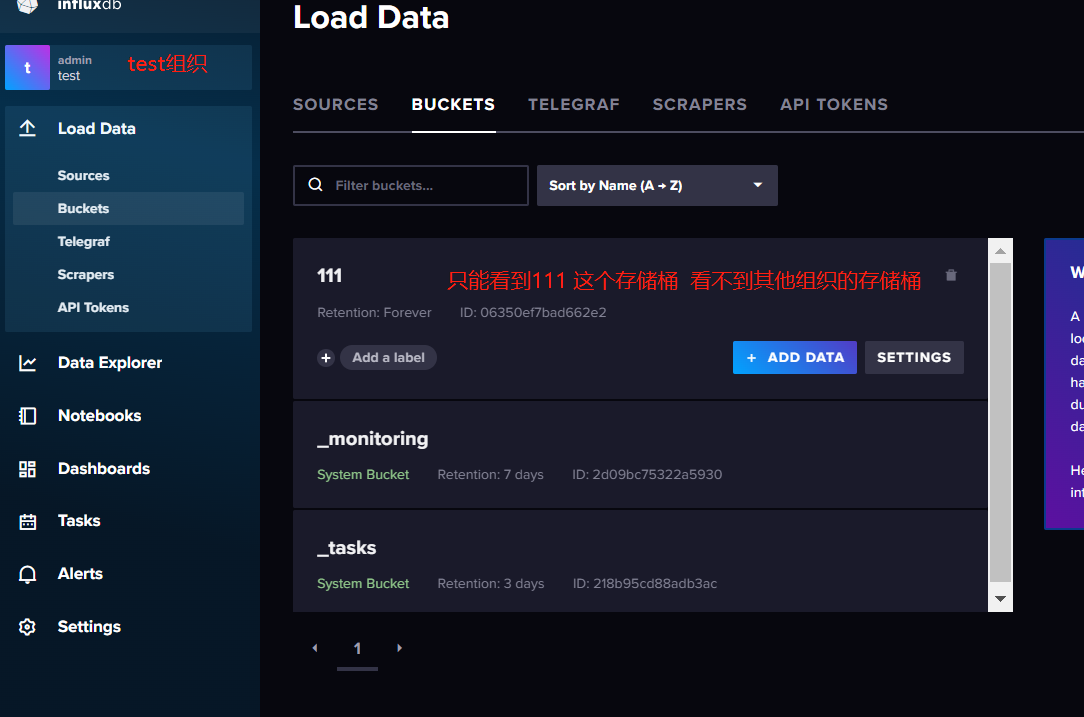
4.InfluxDB的数据存储
4.1 普通关系型数据库中的表
下面这张表示 SQL(关系型)数据库中一个简单的示例。表中有创建索引和未创建索引的列。
- park_id、planet、time 是创建了索引的列。
- _foodships 是未创建索引的列。
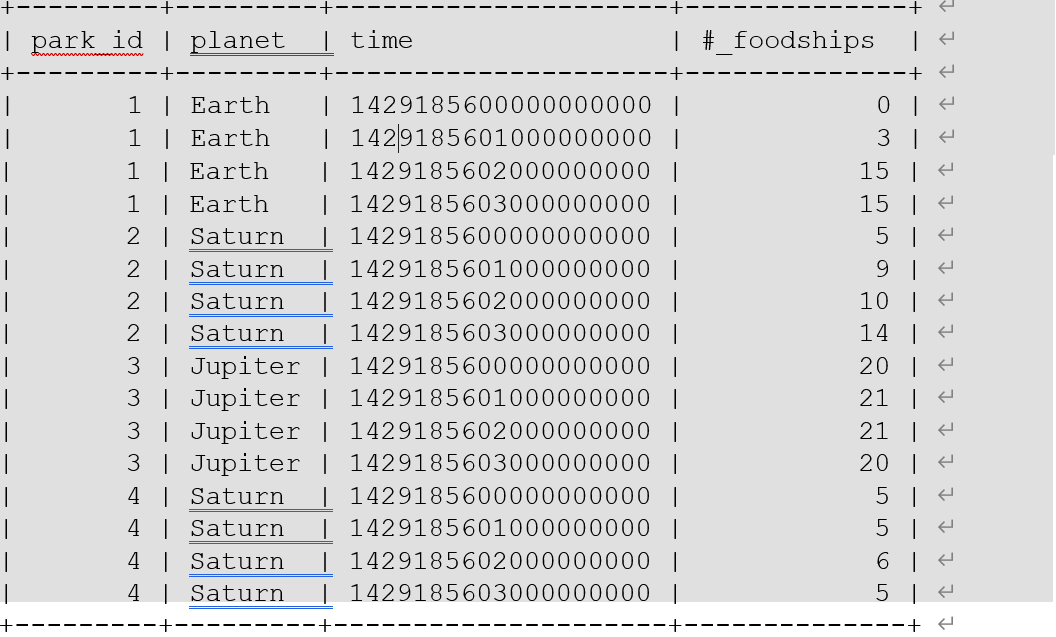
4.2 InfluxDB中的数据表示
上面的数据,如果换到 InfluxDB 中,会换一种形式进行表示。

你可以这样理解。
- InfluxDB 中的 measurement(foodships)相当于 SQL(关系型)数据库中的表
- InfluxDB 中的 tags(park_id 和 planet)相当于 SQL(关系型)数据库中的索引列
- InfluxDB 中的 fileds(在这里是#_foodships)相当于 SQL(关系型)数据库中的未建索引的列。
- InfluxDB 中的数据点相当于SQL(关系型)数据库中的一行。
4.3 时序型数据库中序列的概念
InfluxDB 这类数据库是用序列的方式来管理数据的。在 InfluxDB 中,唯一的 measurement,tag_set 和 fileld(一个字段)组合是一个 series(序列)。
比如下图中有 6条连续的线,这里面每个条线就是一个序列。每一个序列的数据在内存和磁盘上紧密存放,
这样当你要查询这一序列的数据时,InfluxDB 可以很快定位到这一序列中的好多条数据。你也可以将 measurement,tag,field 视为索引,而且它们本身就是索引。
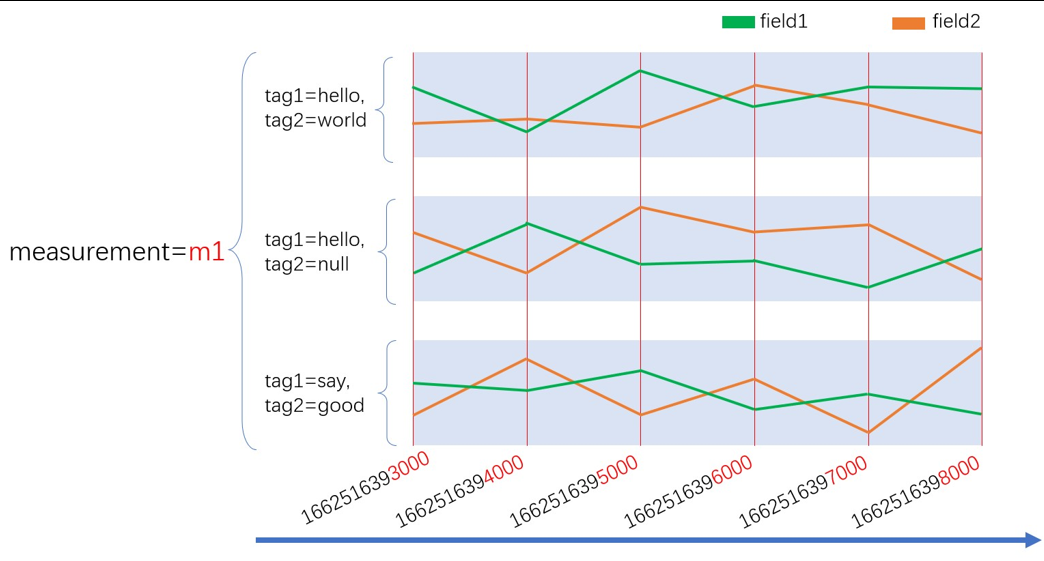
以序列的方式管理数据是时序数据库和传统关系型数据库最不同的地方。
传统的关系型数据库
**关系型数据库:**通常是以 record(记录或者行)的方式管理数据,这个时候,可以让你快速地通过索引定位到一条数据。
时序型数据库
**时序型数据库:**是把索引打到一批次的数据上,所以在这种场景的下的读写,时序库性能是远强于 B+树数据库的。
4.4 时序型数据库的双索引设计与高效查询思路
之前说到你可以将 measurement、tag_set 和 field 视为索引,还没有提到最重要的`timestamp`。其实,在 InfluxDB 中时间也是索引,数据在入库时,会按时间戳进行排序。这样,我们在进行查询时,一般遵循下面的思路
- 先指定要从哪个存储桶查询数据
- 指定数据的时间范围
- 指定 measurement、tag_set、和 field 说明我要查询哪个序列。
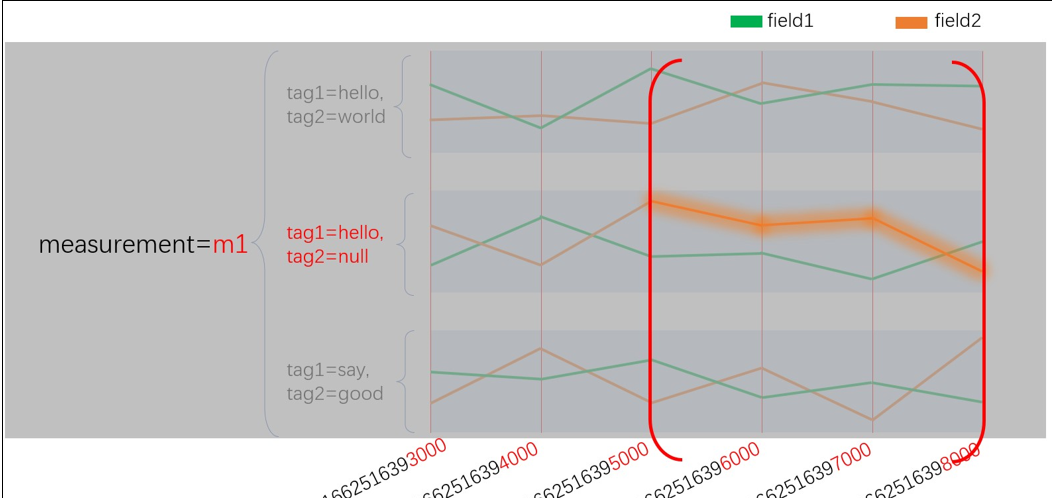
4.5 一次只能查询一个序列吗
一次只能查询一个序列,这显然是不合理的。
假如,我现在只指定要查询 measurent 为 m1 和 tag1 为 hello 的数据,那么就会命中图中 4 条序列。所以实际上,measurement,tag,field 都是倒排索引。
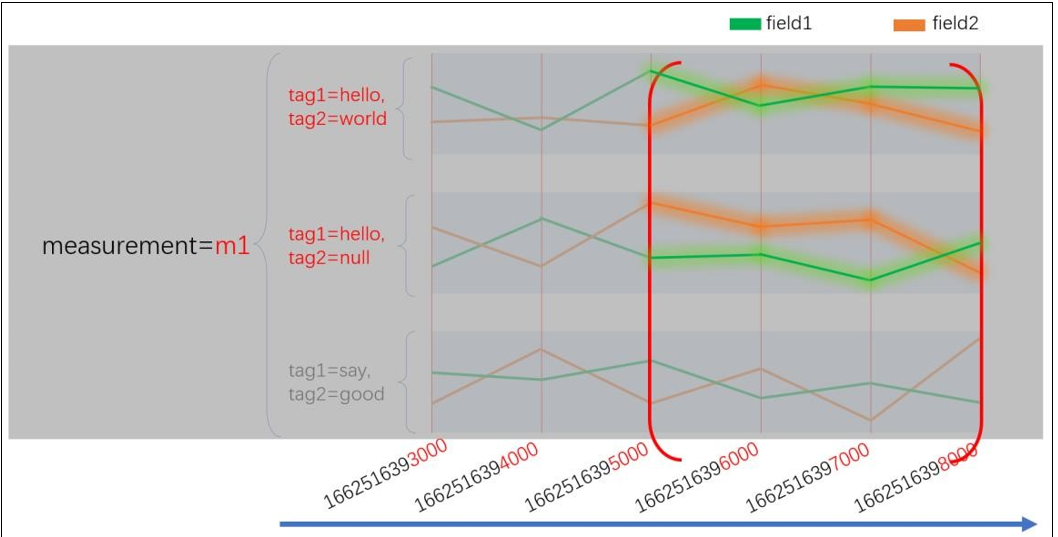
4.6 时间线膨胀(高基数问题)
时间线膨胀是所有时序数据库都绕不过的问题。简单地来解释时间线膨胀,就是我们的时序数据库中序列太多了。
当序列过多时,时序数据库的写入和读取性能通常都会有明显的下降。所以,当你去网上看一些时序数据库的压测文章时,需要注意文章有没有将序列数考虑进去
5. Flux语言数据类型
5.1 基本介绍
Flux 是一种函数式的数据脚本语言,它旨在将查询、处理、分析和操作数据统一为一种语法。
想要从概念上理解 FLUX,你可以想想水处理的过程。我们从源头把水抽取出来,然后按照我们的用水需求,在管道上进行一系列的处理修改(去除沉积物,净化)等,最终以消耗品的方式输送到我们的目的地(饮水机、灌溉等)。
注意:InfluxData 公司对 FLUX 语言构想并不是仅仅让它作为 InfluxDB 的特定查询语言,而是希望它像 SQL 一样,成为一种标准。按照这个计划,FLUX 语言应该具备处理来自不同数据源的数据的能力。
简单示例
与处理水一样,使用 FLUX 语言进行查询时会执行以下操作。
- 从数据源中查询指定数量的数据
- 根据时间或字段筛选数据
- 将数据进行处理或者聚合以得到预期结果
- 返回最终的结果
下面 3 个示例的处理逻辑都是一样的,只不过数据源有所不同,
示例 1:从 InfluxDB 查询数据并聚合
from(bucket: "example-bucket")
|> range(start: -1d)
|> filter(fn: (r) => r._measurement == "example-measurement")
|> mean()
|> yield(name: "_results")
示例 2:从 CSV 文件查询数据并聚合
import "csv"
csv.from(file: "path/to/example/data.csv")
|> range(start: -1d)
|> filter(fn: (r) => r._measurement == "example-measurement")
|> mean()
|> yield(name: "_results")
示例 3:从 PostgreSQL 数据库查询数据并聚合
import "sql"
sql.from(
driverName: "postgres",
dataSourceName: "postgresql://user:password@localhost", query: "SELECT * FROM TestTable",
)
|> filter(fn: (r) => r.UserID == "123ABC456DEF")
|> mean(column: "purchase_total")
|> yield(name: "_results")
上面 3 个示例用的函数都是一模一样的,下面来讲解示例中出现的代码:
- from( )函数可以指定数据源。
- | > 管道转发符,将一个函数的输出转发给下一个函数。
- range( ),fliter( ) 两个函数在根据列的值对数据进行过滤
- mean( )函数在计算所剩数据的平均值。
- yield( ) 将最终的计算结果返回给用户。
铭记 FLUX 是一门查询语言
虽然,FLUX 语言的自我定位一个脚本语言,但是我们必须注意它也是一个查询语言的事实。因此,一个 FLUX 脚本想要成功执行,它就必须返回一个表流。就像是 SQL 语言想要正确执行,它就必须返回一张表。
表流是 FLUX 里提出一种数据结构,在后面的课程里我们会表流的概念进行深度的讲解。另外需要注意,我们后面的代码,如果只返回一个单值,比如单个整数或者字符串这种,那就必须把这个值转换成表流才能运行。这个时候必须使用 array.from 函数。
示例如下:
from "array x = 1 array.from(rows: [{"value":x}])
array.from 函数的作用就是把 x 这个单值,包装在了一个表流里面返回了
5.2 基本语法
在 FLUX 脚本中,没有多行注释一说,用户只能写单行注释。如果一行以两个斜杠开头,那么这一行中的所有内容会被视为注释。
// 这是一行注释。
5.4.1 变量与赋值
使用赋值运算符(=)将表达式的结果赋值变量,最终你可以使用变量名来返回变量的值。示例:
s = "foo" // string
i = 1 // integer
f = 2.0 // float(floating point number)
5.4.2 算数运算符
FLUX 支持基本的表达式,比如:
+数字相加或字符串拼接-数字减法*数字相乘/数字除法%取模
示例:
1 + 1
// Returns 2
10 * 3
// Returns 30
(12.0 + 18.0) / (2.0 ^ 2.0) + (240.0 % 55.0)
// Returns 27.5
"John " + "Doe " + "is here!" // Returns John Doe is here!
5.4.3 谓词表达式
1. 比较运算符
谓词表达式使用比较运算符和逻辑运算符来实现,谓词表达式的最后的返回结果只能为 true 或 false
"John" == "John"
// Returns true
41 < 30
// Returns false
"John" == "John" and 41 < 30
// Returns false
"John" == "John" or 41 < 30
// Returns true
~可以判断一个字符串时候能被正则表达式匹配上。 !~是=~的反操作,
"abcdefg" =~ "abc|bcd" // Returns true
"abcdefg" !~ "abc|bcd" // Returns false
**2. 逻辑运算符 **
在 FLUX 语言中,表示与逻辑需要使用关键字 and,表示或逻辑需要使用关键字 or。
a = true
b = false
x = a and b // Returns false
y = a or b // Returns true
not 可以用来进行逻辑取反
a = true
b = not a // Returns false
5.4.4 控制语句
所谓控制语句是指一个编程语言中用来空值代码执行顺序的语法。
比如: if else for while 循环 try catch 异常捕获,不过,在 InfluxDB 中,这些语法统统没有。唯一一个和 if else 比较像的是 FLUX 语言中的条件子句,它和 python 中的条件子句功能一样且语法相似,和 java 语言相比的话它有些像三元表达式。示例如下:
x = 0
y = if x == 0 then "hello" else "world"
z = if x == 0 then "hello" else if x == 1 then "world" else "!"
此处,if then else 被我们成为条件子句,你需要先指定一个条件,然后当条件为 true 的时候,条件子句会返回 then 后面的内容,也就是"hello"。如果是 flase,那么就会返回else 后面的内容,也就是"world"。
5.3 数据类型
官方文档
https://docs.influxdata.com/flux/v0.x/
查看函数如何使用
常来说我们使用 FLUX 的文档主要是用它来查看一些函数怎么用
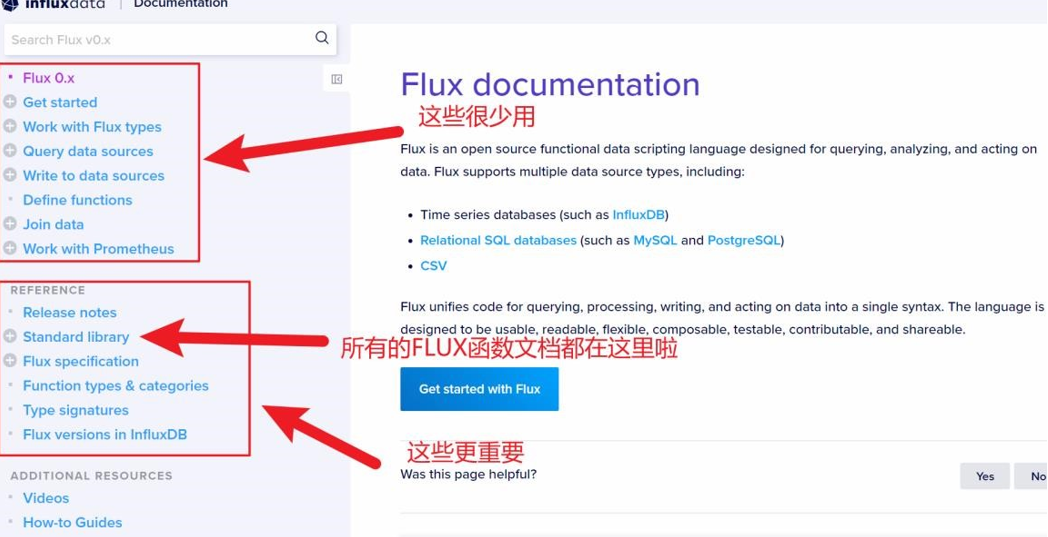
**点击 Standard libaray,就可以看到 FLUX 的所有函数包了。效果如下图所示: **

点击一个包的左侧的+按钮,就可以看到这个包里的所有函数,任意点击其中一个,就可以看到这个函数的详细说明,包括会返回什么,调用的时候需要传递什么参数等等。
再往下拉,你还可以看到每个函数都有很详细的使用示例。代码基本上是可以拿来改改就用的

**避免使用实验中的函数,另外,需要额外注意有一个函数库的名字叫 experimental,这个单词是实验的意思,也就是在未来的 FLUX 版本中,这个函数有可能会变,参数名可能也不是很确定,甚至这个函数可能会在未来的某个版本被放弃。 **

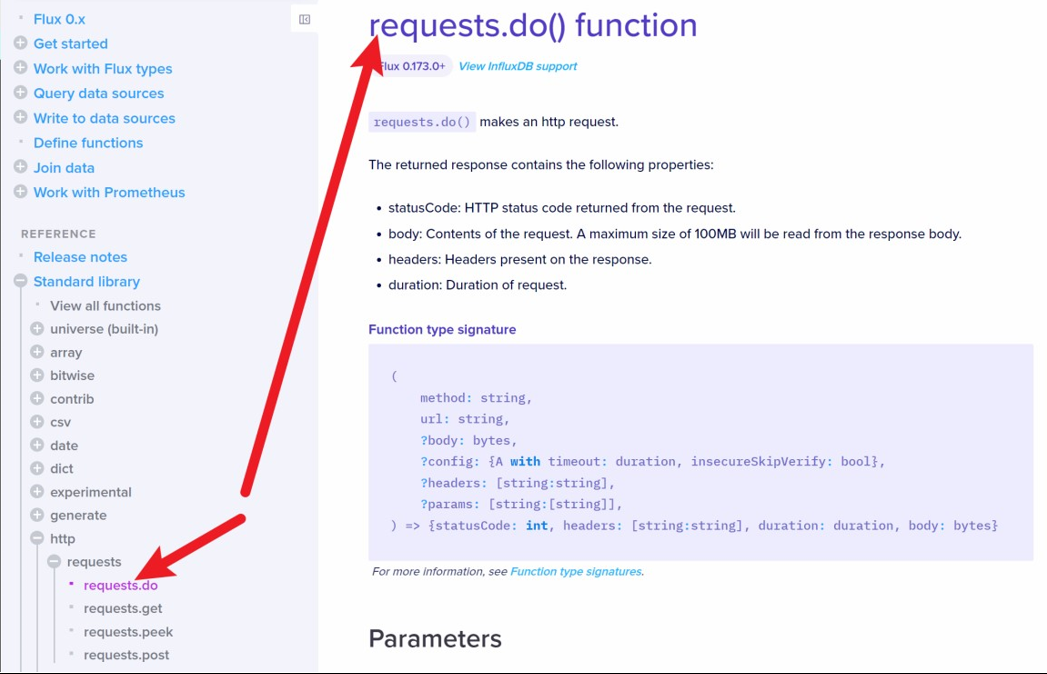
查看函数可以在哪些版本中使用
另外需要注意,每个函数的文档标题正下方都会标记这个函数是从哪个 FLUX 版本开始加入的。比如从下图我们就可以知道 request.do()函数是从 0.173 之后才能用的。

下面这张图告诉我们 array.concat()函数从 0.173 版本之后就不能再用了

5.3.1 基础数据类型
1. Boolean (布尔型)
布尔类型只包括:true false
将以下的4 个基本数据类型转换为 boolean:
- string(字符串):字符串必须是 "true" 或 "false"
- float(浮点数):值必须是 0.0(false)或 1.0(true)
- int(整数):值必须是 0(false)或 1(true)
- uint(无符号整数):值必须是 0(false)或 1(true)示例:
bool(v: "true") // Returns true
bool(v: 0.0) // Returns false
bool(v: 0) // Returns false
bool(v: uint(v: 1)) // Returns true
2. bytes (字节序列)
注意是 bytes(复数)不是 byte,bytes 类型表示一个由字节组成的序列。
1. 定义 bytes
FLUX 没有提供关于 bytes 的语法。可以使用 bytes 函数将字符串转为 bytes,InfluxDB底层不支持字节类型
bytes(v:"hello") // Returns [104 101 108 108 111]
注意:只有字符串类型可以转换为 bytes。
2. 将表示十六进制的字符串转为 bytes
- 引入"contrib/bonitoo-io/hex"包
- 使用 hex.bytes() 将表示十六进制的字符串转为 bytes
import "contrib/bonitoo-io/hex"
hex.bytes(v: "FF5733") // Returns [255 87 51] (bytes)
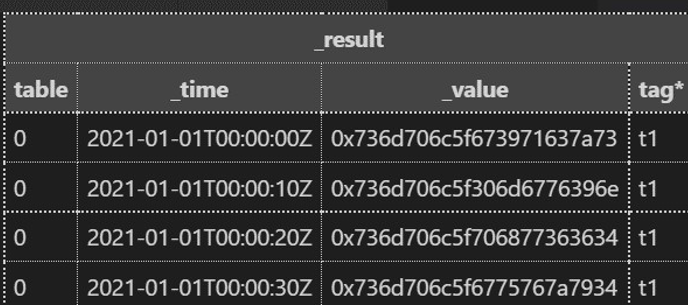
3.使用 display( )函数获取 bytes 的字符串形式
使用 display( )返回字节的字符串表示形式。bytes 的字符串表示是 0x 开头的十六进制表示。
// 基本使用
a = "abc"
b = bytes(v:a)
c = dispaly(v:b)
// 高级使用
import "sampledata"
sampledata.string()
|> map(fn: (r) => ({r with _value: display(v: bytes(v: r._value))}))
3. Duration 持续时间
持续时间提供了纳秒级精度的时间长度。
1. 语法
1ns // 1 纳秒
1us // 1 微妙
1ms // 1 毫秒
1s // 1 秒
1m // 1 分钟
1h // 1 小时
1d // 1 天
1w // 1 星期
1mo // 1 日历月
1y // 1 日历年
3d12h4m25s // 3天12小时4分钟又25秒
注意: 持续时间的声明不要包含先导 0
01m // 解析为整数0和1分钟的持续时间
02h05m //解析为整数0、2小时的持续时间,整数0和5分钟的持续时间。而不是2 小时又5分钟
2. 将其他数据类型解释为持续时间
使用 duration( )函数可以将以下基本数据类型转换为持续时间字符串:将表示持续时间字符串的函数转换为持续时间。
- int:将整数先解释为纳秒再转换为持续时间
- unit:将整数先解释为纳秒再转换为持续时间。
duration(v: "1h30m") // Returns 1h30m
duration(v: 1000000) // Returns 1ms
duration(v: uint(v: 3000000000)) // Returns 3s
注意!你可以在 FLUX 语言中使用 duration 类型的变量与时间做运算,但是你不能在 table 中创建 duration 类型的列。
3. duration的算术运算
要对 duration 进行加法、减法、乘法或除法操作,需要按下面的步骤来。
- 使用 int( )或 unit()将持续时间转换为 int 数值
- 使用算术运算符进行运算
- 把运算的结果再转换回 Duration 类型示例:
duration(v: int(v: 6h4m) + int(v: 22h32s)) // 返回 1d4h4m32s
duration(v: int(v: 22h32s) - int(v: 6h4m)) // 返回 15h56m32s
duration(v: int(v: 32m10s) * 10) // 返回 5h21m40s
duration(v: int(v: 24h) / 2) // 返回 12h
注意!声明持续时间的时候不要包含前导 0,前面的零会被 FLUX 识别为整数
4. 时间和持续时间相加运算
- 导入 date 包
- 使用 date.add( )函数将持续时间和时间相加示例:
import "date"
date.add(d: 1w, to: 2021-01-01T00:00:00Z) // 2021-01-01加上一周
// Returns 2021-01-08T00:00:00.000000000Z
5. 时间和持续时间相减运算
- 导入 date 包
- 使用 date.add( )函数从时间中减去持续时间示例:
mport "date"
date.sub(d: 1w, from: 2021-01-01T00:00:00Z) // 2021-01-01 减去一周
// Returns 2020-12-25T00:00:00.000000000Z
4. Regular expression 正则表达式
1. 定义一个正则表达式
FLUX 语言是 GO 语言实现的,因此使用 GO 的正则表达式语法。正则表达式需要声明在正斜杠之间 / /
2. 使用正则表达式进行逻辑判断使用正则表达式进行逻辑判断
需要使用 =~ 和 != 操作符。=~ 的意思是左值(字符串)能够被右值匹配,!~表示左值(字符串)不能被右值匹配。
"abc" =~ /\w/ // Returns true
"z09se89" =~ /^[a-z0-9]{7}$/ // Returns true
"foo" !~ /^f/ // Returns false
"FOO" =~ /(?i)foo/ // Returns true
3. 将字符串转为正则表达式
- 引入 regexp 包
- 使用 regexp.compile( ) 函数可以将字符串转为正则表达式
import "regexp"
regexp.compile(v: "^- [a-z0-9]{7}") // Returns ^- [a-z0-9]{7} (regexp type)
4. 将匹配的子字符串全部替换
- 引入 regexp 包
- 使用 regexp.replaceAllString( )函数,并提供下列参数:
- r:正则表达式
- v:要搜索的字符串
- t: 一旦匹配,就替换为该字符串示例:
import "regexp"
regexp.replaceAllString(r: /a(x*)b/, v: "-ab-axxb-", t: "T") // Returns "-T-T-"
5. 得到字符串中第一个匹配成功的结果
- 导入 regexp 包
- 使用 regexp.findString( )来返回正则表达式匹配中的第一个字符串,需要传递以下参数:
- r:正则表达式
- v:要进行匹配的字符串示例:
import "regexp"
regexp.findString(r:"abc|bcd",v:"xxabcwwed") // Returns "abc"
5. String 字符串
1. 定义一个字符串
字符串类型表示一个字符序列。字符串是不可改变的,一旦创建就无法修改。
字符串是一个由双引号括起来的字符序列,在 FLUX 中,还支持你用\x 作为前缀的十六进制编码来声明字符串。
"abc"
"string with double \" quote"
"string with backslash \\"
"日本語"
"\xe6\x97\xa5\xe6\x9c\xac\xe8\xaa\x9e"
2. 将其他基本数据类型转换为字符串使用 srting( )函数可以将下述基本类型转换为字符串:
| boolean | 布尔值 |
|---|---|
| bytes | 字节序列 |
| duration | 持续时间 |
| float | 浮点数 |
| uint | 无符号整数 |
| time | 时间 |
string(v: 42) // 返回 "42"
3. 将正则表达式转换为字符串
因为正则表达式也是一个基本数据类型,所以正则表达式也可以转换为字符串,但是需要借助额外的包。
- 引入 regexp 包
- 使用 regexp.compile( )
6. Time 时间点
1. 定义一个时间点
一个 time 类型的变量其实是一个纳秒精度的时间.
示例:时间点必须使用 RFC3339 的时间格式进行声明
YYYY-MM-DD
YYYY-MM-DDT00:00:00Z
YYYY-MM-DDT00:00:00.000Z // 毫秒级
2. 时间戳转成UTC格式
a = time(v:1664401985000*1000*1000) // v接收纳秒级的时间戳
3. UTC时间转成时间戳
a = uint(v:2023-09-19T00:00:00.000Z) // 得到的同样是纳秒级的时间戳
7. Float 浮点数
1. 定义一个浮点数
FLUX 中的浮点数是 64 位的浮点数。一个浮点数包含整数位,小数点,和小数位。
0.0
123.4
-123.456
2. 科学计数法
FLUX 没有直接提供科学计数法语法,但是你可以使用字符换写出一个科学计数法表示的浮点数,再使用 float( )函数将该字符串转换为浮点数。
1.23456e+78 // Error: error @1:8-1:9: undefined identifier e
float(v: "1.23456e+78") // Returns 1.23456e+78 (float) e+78表示 1.23456的78次方
3. 无限大的整数
FLUX 也没有提供关于无限的语法,定义无限要使用字符串与 float( )函数结合的方式。
+Inf // Error: error @1:2-1:5: undefined identifier Inf
float(v: "+Inf") // Returns +Inf (float)
4. Not a Number 非数字
FLUX 语言不支持直接从语法上声明 NAN,但是你可以使用字符串与 float( )函数的方法声明一个 NaN 的 float 类型变量。
NaN // Error: error @1:2-1:5: undefined identifier NaN
float(v: "NaN") // Returns NaN (float)
5. 将其他基本类型转换为 float
使用 float 函数可以将基本数据类型转换为 float 类型的值。 string:必须得是一个符合数字格式的字符串或者科学计数法。
bool:true 转换为 1.0,false 转换为 0.0 int(整数) uint(无符号整数:
float(v: "1.23") // 1.23
float(v: true) // Returns 1.0
float(v: 123) // Returns 123.0
6. 对浮点数进行逻辑判断
使用 FLUX 表达式来比较浮点数。逻辑表达式两侧必须是同一种类型。
12345600.0 == float(v: "1.23456e+07") // Returns true
1.2 > -2.1 // Returns true
8. Integer 整数
1. 定义一个整数
一个 integer 的变量是一个 64 位有符号的整数。
类型名称:int
最小值:-9223372036854775808 最大值:9223372036854775807
一个整数的声明就是普通的整数写法,前面可以加 - 表示负数。-0 和 0 是等效的。
0
2
1254
-1254
2. 将数据类型转换为整数
使用 int( )函数可以将下述的基本类型转换为整数:
- string:字符串必须符合整数格式,由数字[0-9]组成
- bool:true 返回 1,0 返回 false
- duration:返回持续时间的纳秒数
- time:返回时间点对应的 Unix 时间戳纳秒数 float:返回小数点前的整数部分,也就是截断
- unit:返回等效于无符号整数的整数,如果超出范围,就会发生整数环绕
int(v: "123") // 123
int(v: true) // Returns 1
int(v: 1d3h24m) // Returns 98640000000000
int(v: 2021-01-01T00:00:00Z) // Returns 1609459200000000000
int(v: 12.54) // Returns 12
你可以在将浮点数转换为整数之前进行舍入操作。 当你将浮点数转换为整数时,会进行截断操作。如果你想进行四舍五入,可以使用 math 包中的 round( )函数。
3. 将表示十六进制数字的字符串转换为整数
将表示十六进制数字的字符串转换为整数,需要。
- 引入 contrib/bonito-io/hex 包
- 使用 hex.int( )函数将表示十六进制数字的字符串转换为整数
import "contrib/bonitoo-io/hex"
hex.int(v: "e240") // Returns 123456
9. UIntegers 无符号整数
FLUX 语言里不能直接声明无符号整数,但这却是一个 InfluxDB 中具备的类型。在 FLUX 语言中,我们需要使用 uint 函数来讲字符串、整数或者其他数据类型转换成无符号整数。
uint(v: "123") // 123
uint(v: true) // Returns 1
uint(v: 1d3h24m) // Returns 98640000000000
uint(v: 2021-01-01T00:00:00Z) // Returns 1609459200000000000
uint(v: 12.54) // Returns 12
uint(v: -54321) // Returns 18446744073709497295
unit(v:"9223372036854775808") // int的最大值为9223372036854775807,如果这里v传的是整数型的9223372036854775808,会因为超过了int的最大值而报错,所以用字符串传参
10. Null 空值
1. 定义一个 Null 值
FLUX 语言并不能在语法上直接支持声明一个 Null,注意!空字符串不是 null 值 ,但是我们可以通过 debug.null 这个函数来声明一个指定类型的空值。
import "internal/debug"
debug.null(type: "string") // Return a null string
debug.null(type: "int") // Return a null integer
debug.null(type: "bool") // Return a null boolean
2. 判断值是否为 null
你可以使用 exists(存在)这个关键字来判断目标值是不是非空,如果是空值我们会得到一个 false,如果不是空值我们会得到一个 true。
import "array" import "internal/debug"
x = debug.null(type: "string")
y = exists x // Returns false
11. 正则表达式类型
正则表达式在 FLUX 中作为一种数据类型,而且在语法上提供直接的支持,可以在谓词表达式中使用正则表达式。
regex = /^foo/
"foo" =~ regex // Returns true
"bar" =~ regex // Returns false
12. display 函数
使用 display( )函数可以将任何类型的值输出为相应的字符串类型。
x = bytes(v: "foo")
display(v: x) // Returns "0x666f6f"
5.3.2 复合类型
1. Record(记录)
1.1 Record 定义
一个记录是一堆键值对的集合,其中键必须是字符串,值可以是任意类型,在键上没有空白字符的前提下,键上的双引号可以省略。在语法上,record 需要使用{}声明,键值对之间使用英文逗号(,)分开。另外,一个Record 的内容可以为空,也就是里面没有键值对
{foo: "bar", baz: 123.4, quz: -2}
{"Company Name": "ACME", "Street Address": "123 Main St.", id: 1123445}
1.2 Record 取值
- 点表示法 取值
如果 key 中没有空白字符,那么你可以使用 .key 的方式从 record 中取值.c = {name: "John Doe", address: "123 Main St.", id: 1123445} c.name // Returns John Doe c.id // Returns 1123445 - 中括号方式取值
可以使用[" "]的方式取值,当 key 中有空白字符的时候,也只能用这种方式来取值。c = {"Company Name": "ACME", "Street Address": "123 Main St.", id: 1123445} c["Company Name"] // Returns ACME c["id"] // Returns 1123445 - 嵌套与链式取值
Record 类型可以进行嵌套引用。从嵌套的 Record 中引用值的时候可以采用链式调用的方式。链式调用时,点表示法和中括号还可以混用。但是不能当做第二层record不能当做记录存储在InfluxDB中 ,可以将整体转成json再存储customer = { name: "John Doe", address: { street: "123 Main St.", city: "Pleasantville", state: "New York" } } customer.address.street // Returns 123 Main St. customer["address"]["city"] // Returns Pleasantville customer["address"].state // Returns New York
1.3 Record 的 key 是静态的
record 类型变量中的 key 是静态的,一旦声明,其中的 key 就被定死了。一旦你访问这个 record 中一个没有的 key,就会直接抛出异常。正常的话应该返回 null。
o = {foo: "bar", baz: 123.4}
o.key // Error: type error: record is missing label haha
b = "foo"
o[b] // 错误,禁止使用变量来访问Record的值
1.4 Records常用操作方法
- 拓展一个 Record
使用 with 操作符可以拓展一个 record,当原始的 record 中有这个 key 时,原先 record 的值会被覆盖;如果原先的 record 中没有制定的 key,那么会将旧 record 中的所有元素和 with 中指定的元素复制到一个新的 record 中。// 覆盖原先的值,并添加一个 key 为 pet,value 为"Spot"的元素 c = {name: "John Doe", id: 1123445} {c with name: "Xiao Ming", pet: "Spot"} // Returns {id: 1123445, name: Xiao Ming, pet: Spot}
- 列出 Record 的所有keys
- 导入 experimental(实验的)包。
- 使用 expertimental.objectyKeys(o:c)方法来拿到一个 record 的所有 key。
import "experimental" c = {name: "John Doe", id: 1123445} experimental.objectKeys(o: c) // Returns [name, id]
- 比较两个 Record 是否相等
可以使用双等号= =来判断两个 record 是否相等。如果两个 record 的每个 key,每个key 对应的 value 和类型都相同,那么两个 record 就相等.{id: 1, msg: "hello"} == {id: 1, msg: "goodbye"} // Returns false {foo: 12300.0, bar: 34500.0} == {bar: float(v: "3.45e+04"), foo: float(v: "1.23e+04")} // Returns true - 将 Record 转为字符串
使用 display( )函数可以将 record 转为字符串。x = {a: 1, b: 2, c: 3} display(v: x) // Returns "{a: 1, b: 2, c: 3}"
1.5 嵌套 Record 的意义
注意,嵌套的 Record 无法放到 FLUX 语言返回的表流中,这个时候会发生类型错误,它会说 Record 类型不能充当某一列的类型。那 FLUX 为什么还支持对 Record 进行嵌套使用呢?其实这是为了一些网络通讯的功能来服务,在 FLUX 语言中我们有一个 http 库。借助这个函数库,我们可以向外发送 http post 请求,而这种时候我们就有可能要发送嵌套的 json。细心的同学可能发现,我们的 record 在语法层面上和 json 语法是统一的,而且 FLUX 语言提供了一个 json 函数库,借助这个库中的 encode 函数,我们可以轻易地将一个record 转为 json 字符串然后发送出去。
2. Array(数组)
2.1 Array定义
Array 是一个由相同类型的值构成的有序序列。 在语法上,数组是用方括号[ ]起来的一堆同类型元素,元素之间用英文逗号( , )分隔,并且类型必须相同。
["1st", "2nd", "3rd"]
[1.23, 4.56, 7.89]
[10, 25, -15]
2.2 Array 取值
可以使用中括号 [ ] 加索引的方式从数组中取值,数组索引从 0 开始
arr = ["one", "two", "three"]
arr[0] // Returns one
arr[2] // Returns two
2.3 判断数组相等
a = [1,2,3]
b = [2,3,1]
a == b // false
a = [1,2,3]
b = [1,2,3]
a == b // true
2.4 检查一个数组中是否包含某元素
使用 contains( )函数可以检查一个数组中是否包含某个元素。
names = ["John", "Jane", "Joe", "Sam"]
contains(value: "Joe", set: names) // Returns true
3. Dictionary(字典)
3.1 字典定义
字典和记录很像,但是 key-value 上的要求有所不同。 一个字典是一堆键值对的集合,其中所有键的类型必须相同,且所有值的的类型必须相同。 在语法上,dictionary 需要使用方括号[ ]声明,键的后面跟冒号(:)键值对之间需要使用英文逗号( , )分隔。
[0: "Sun", 1: "Mon", 2: "Tue"]
["red": "#FF0000", "green": "#00FF00", "blue": "#0000FF"]
[1.0: {stable: 12, latest: 12}, 1.1: {stable: 3, latest: 15}]
3.2 字典取值
- 导入 dict 包
- 使用 dict.get( )并提供下述参数:
- dict:要取值的字典
- key:要用到的 key
- default:默认值,如果对应的 key 不存在就返回该值
import "dict"
positions = [
"Manager": "Jane Doe",
"Asst. Manager": "Jack Smith",
"Clerk": "John Doe",
]
a = "Manager"
dict.get(dict: positions, key: a, default: "Unknown position") // 可以使用变量取值
dict.get(dict: positions, key: "Manager", default: "Unknown position") // Returns Jane Doe
dict.get(dict: positions, key: "Teller", default: "Unknown position") // Returns Unknown position
3.3 从列表创建字典
- 导入 dict 包
- 使用 dict.fromList( )函数从一个由 records 组成的数组中创建字典。其中,数组中的每个 record 必须是{key:xxx,value:xxx}形式
import "dict"
list = [{key: "k1", value: "v1"}, {key: "k2", value: "v2"}]
dict.fromList(pairs: list) // Returns [k1: v1, k2: v2]
3.4 向字典中插入键值对
- 导入 dict 包
- 使用 dict.insert( )函数添加一个新的键值对,如果 key 早就存在,那么就会覆盖这个 key 对应的 value。
import "dict"
exampleDict = ["k1": "v1", "k2": "v2"]
dict.insert(dict: exampleDict, key: "k3 ", value: "v3") // Returns [k1: v1, k2: v2, k3: v3]
3.5 从字典中移除键值对
- 引入 dict 包
- 使用 dict.remove 方法从字典中删除一个键值对示例:
import "dict"
exampleDict = ["k1": "v1", "k2": "v2"]
dict.remove(dict: exampleDict, key: "k2") // Returns [k1: v1]
4. function(函数)
4.1 函数声明
一个函数是使用一组参数来执行操作的代码块。函数可以是命名的,也可以是匿名的。在小括号( )中声明参数,并使用箭头=>将参数传递到代码块中。
square = (n) => n * n
square(n:3) // Returns 9
// FLUX 不支持位置参数。调用函数时,必须显示指定参数名称。
chengfa =(x,y)=>{
return x*y // 如果是{}这种代码块,就必须有返回值
}
b = chengfa(x:10,y:48)
// 闭包
getChengfa = ()=>{
chengfa =(x,y)=> x*y
return chengfa
}
b = getChengfa()(x:10,y:48)
4.2 为函数提供默认值
我们可以为某些函数指定默认值,如果为函数指定了默认值,也就意味着在调用这个函数时,有默认值的函数时非必须的。
chengfa = (a,b=100) => a * b
chengfa(a:3) // Returns 300
4.3 函数包导入
Flux 的标准库使用包组织起来的。包将 Flux 的众多函数分门别类,默认情况下加载 universe 包,这个包中的函数可以不用 import 直接使用。其他包的函数需要在你的 Flux 脚本中先用 import 语法导入一下。
import "array"
import "math"
import "influxdata/influxdb/sample"
// 但是,截至目前,虽然你可以自定义函数,但是你无法自定义包。如果希望将自己的自定义函数封装在一个包里以供复用,那就必须从源码上进行修改。
5.3.3 常用包
1. date (操作时间的包)
提取年月日秒等信息的。
import "date"
a = 2020-01-01T19:22:31Z
date.year(t:a) // 年
m = date.yearDay(t: a) // 一年的第多少天
date.month(t:a) // 月
date.monthDay(t:a) // 日
date.weekDay(t: a) // 这个月的第几周
date.hour(t:a) // 时
date.minute(t:a) // 分
date.second(t:a) // 秒
date.quarter(t: a) // 季度
时间相加
import "array"
import "date"
a = 2023-09-19T17:00:00Z
b = 2h
b1 = -2h
c = date.add(d: b, to: a)
c1 = date.add(d: b1, to: a)
array.from(rows: [{"a":c}])
2.now()
获取当前时间
t = now()
3.strings(操作字符串的包)
5.4 Flux类型不代表InfluxDB类型
`需要注意,FLUX 语言里有些基本数据类型比如持续时间(Duration)和正则表达式是不能放在表流里面充当字段类型的。简单来说,Duration 类型和正则表达式类型都是 FLUX 语言特有的。有些类型是为了让 FLUX 在编写代码时更加方便,让它能够拥有更多的特性,但这并不代表这些类型能够存储到 InfluxDB 中。 `
6.Flux语言查询InfluxDB
6.1 基本概念
6.1.1 Web页中各字段的意义

InfluxDBweb页面对同一行中的两个字段的显示
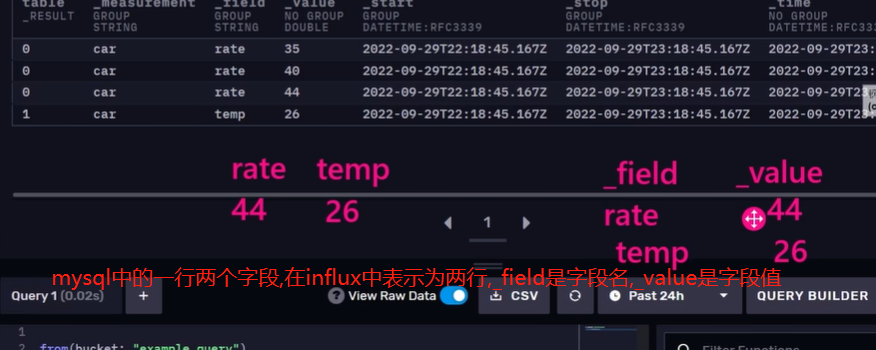
对于序列的含义,先看下面6.3的内容

6.1.2 数据底层存储图示
InfluxDB是以系列的方式来管理数据的,序列是指由 一个measurement + 多个tag + 一个field 定义的
同一个measurement+ 相同的一个或多个tag + 一个field` 等于同一个序列
第一次写入数据 car,code=01 rate=35 时,就是相当于给 measurement=car tag为code=01 field为rate 的序列加了一个35的数据点

第二次写入数据 car,code=01 rate=40 时,就是相当于给 measurement=car tag为code=01 field为rate 的序列加了一个40的数据点

第三次写入数据 car,code=01 rate=44,temp=60 时,就是相当于给 measurement=car tag为code=01 field为rate 的序列加了一个44的数据点,同时给 measurement=car tag为code=01 field为temp 的序列加了一个60的数据点

第四次写入数据 car,code=01 rate=45 时,就是相当于给 measurement=car tag为code=01 field为rate 的序列加了一个45的数据点,并未操作temp的那个序列
6.1.3 表、表流以及序列
我们知道 InfluxDB 是使用序列的方式去管理数据的。而 FLUX 语言又企图兼容一些关系型数据库的查询,而关系型数据库里的数据结构就是一个有行有列的 table。因此对于FLUX 语言来说,就需要将序列和表统一成一个东西。所以 FLUX 引入了表流的概念。
简单来说,FLUX 可以一次性查出多个序列,这个时候一个序列对应一张表,而表流其实就是多张表的集合。同时表流和表的关系其实是全表和子表的关系,子表是全表按照 _field,tag_set 和_measurement 进行 group by 之后的结果。在这种情况下,如果调用聚合函数,其实只会在子表中进行聚合
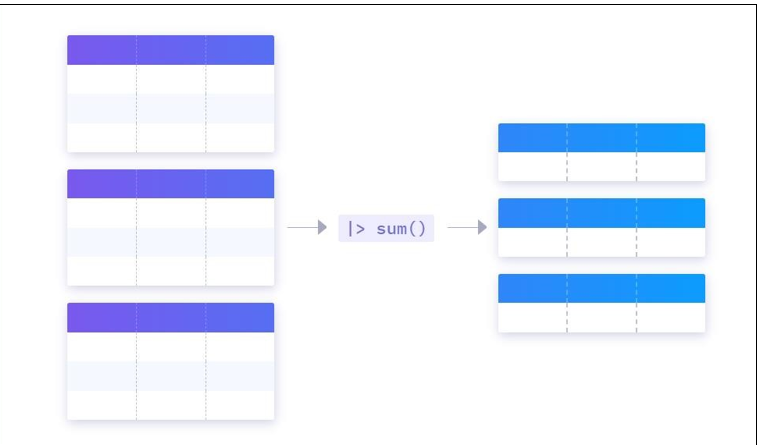
最后,如果一张表对应的是一个序列了,那么一张表里的一行其实就对应着序列中的一个数据点了
6.1.4 对于不同类型的value,如何展示
test field1="你好啊",field2=10.0,field3=11i 同一个序列同时插入了字符串 浮点型 整数型,前端web页面展示如下:
可以看到表被分开表示了,并且整数型转成了浮点型进行存储,查询时需要指定 _field 过滤

3. 类型转换函数与下划线字段
Flux 语言中有很多不用指定字段名称的管道函数,比如 toInt()。其实 toInt()这个函数默认要求你的字段中必须要有_value 字段,没有_value 字段的话也会直接报错。
其实在我们查询出来的数据中,以下划线开头的字段其实代表了一种约定,就是
FLUX 中有很多函数想要正常运行时要依赖于这些下划线打头的字段的。
所以原则上来说,程序员应该遵守这些约定,不要擅自更改下划线开头的字段。
6.2 查询语法
6.2.1. from+range
使用 FLUX 语言查询 InfluxDB,必须以 from -> range 打头,range 必须紧跟在 from 后面,不这么写的话会直接报错。
from(bucket: "simple01")
|> range(start: -1h, stop: now()) // |> 表示将上一条的结果交给下面一个函数继续执行,stop参数的默认值就是当前时间
6.2.2. filter 维度过滤
使用 filert 函数可以对数据按照_measurement、标签集和字段级进行过滤,后面的课程会给大家讲解 filter 的性能问题。
// 单条件过滤
from(
bucket: "test_init")
|> range(start: -1h)
|> filter(fn: (r) => r["_measurement"] == "go_goroutines", onEmpty: "keep") // 筛选 _measurement="go_goroutines" 的序列 onEmpty: "keep" 表示序列编号不从0开始计数
)
// 多条件过滤
from(
bucket: "test_init")
|> range(start: -1h)
|> filter(fn: (r) => r["_measurement"] == "go_goroutines") and r["code"] == "01"
)
// 多过滤
from(
bucket: "test_init")
|> range(start: -1h)
|> filter(fn: (r) => r["_measurement"] == "go_goroutines")
|> filter(fn:(r)=> r["code"] == "01")
)
6.2.3. map 函数
map 函数的作用是遍历表流中的每一条数据。
示例:
import "array"
array.from(rows: [{"name":"tony"},{"name":"jack"}])
|> map(fn: (r)=> { return if r["name"] == "tony" then {"_name": "tony不是 jack"} else {"_name":"jack不是tony"}
})
注意事项:
- map 函数需要传递一个参数 fn,它要求传递一个单个参数输入,且输出必须是 record 的函数,其中输入数据的类型会是 record。
6.2.4. 自定义管道函数
1. 自定义函数
chengfa = (x) => x * 10
from(
bucket: "test_init")
|> range(start: -1h)
|> filter(fn: (r) => r["_measurement"] == "go_goroutines")
|> chengfa() // 由于chengfa只是一个自定义函数,这里用 |> 去流入函数时,就会报错,需要自定义为管道函数,如下:
)
2. 自定义管道函数
此处,我们定义一个管道函数,它可以将表流中的_value 字段的值乘上 x 倍。请同学们在接下来的示例中注意声明管道函数时所用的语法。
big100 = (table=<-,x) => {
return table
|> map(fn: (r) => ({r with "_value":r["_value"]*x}))
}
接下来我们调用刚才声明的函数,最终整个脚本如下:
big100 = (table=<-,x) => {
return table
|> map(fn: (r) => ({r with "_value":r["_value"]*x}))
}
from(
bucket: "test_init")
|> range(start: -1h)
|> filter(fn: (r) => r["_measurement"] == "go_goroutines")
|> big100(x:100)
)
注意事项:
- 管道函数的第一个参数必须写成 table=<-,它表示通过管道符输入进来的必须得是
表流数据, - table 并不一定写成 table 但是=<-的格式绝对不能变。
3. 在文档中区分管道函数和普通函数
再次来到函数文档。
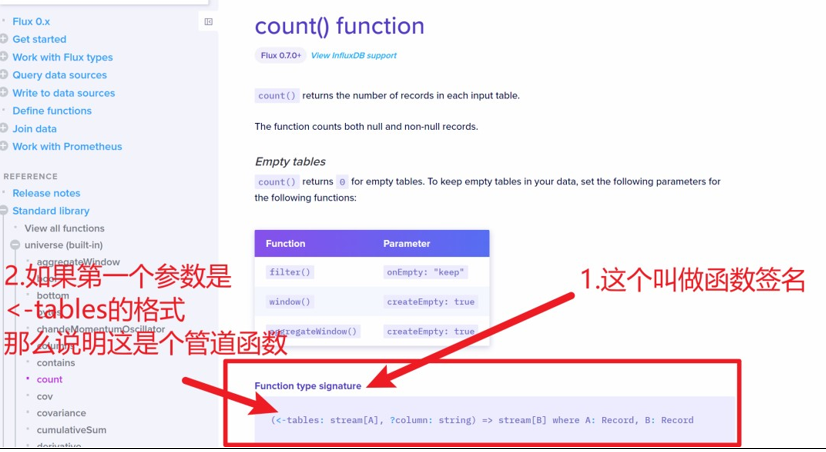
当我们看到一个函数文档,它会有一个区域叫做 Function type Signature(函数签名),它表示着函数接收哪些参数以及会返回什么。最前面的小括号里的内容就是参数列表,如果参数列表的第一个参数是<-tables: stream[A],那就表示它是一个可以接收表流输入的管道函数。
反之,如果没有<-tables: stream[A],那么它就是一个普通函数。
6.2.5. group函数
InfluxDB 的查询结果默认是根据_measurement,_field,tag 进行group by 后的多个表组成的表流,所以也支持自定义分组操作
from(bucket: "simple01") // 指定存储桶
|> range(start: -1h) // 指定查询时间, stop为空,默认为当前时间
|> group(columns:["_value"]) // 指定根据 _value 来分组|> group(columns:["_value"]) // 指定根据 _value 来分组
6.2.6. window 和 aggregateWindow 函数
window 函数和 aggregateWindow 函数其实代表着 InfluxDB 中的两种开窗方式,
不同点:
- window 函数会将整个表流重新分组。window 开窗后,是将原始序列按照窗口的方式对整个表流进行重新分组的新序列
- aggregateWindow 函数会保留原来的分组方式,这样一来,使用 aggregateWindow 函数进行开窗后的表流,仍然是按照序列的方式来分组的。
window
每隔 every 秒 会产生一个序列
from(bucket:"test_init")
|> range(-1h)
|> window(period:10s,every:10s) // 表示为每10秒会开一个持续时间为10s的窗口,every的默认值和period相等
// 查询每30s的最大值
from(bucket:"test_init")
|> range(-1h)
|> window(period:30s)
|> max()
**aggregateWindow **
之前是几个序列,开窗后还是几个序列
// 查询每30s的最大值
from(bucket:"test_init")
|> range(-1h)
|> aggregateWindow(period:30s,every:30s,fn:max) // 必须指定every 参数
|> max()
6.2.7. yield 和 join
**当 flux 脚本中出现 `未被赋值` 给某个变量的表流时,InfluxDB 执行 FLUX 脚本时会自动帮他们在管道的最后面加上`|> yield(name: "_result")`函数,**
yield 函数其实是指定了我们当前这个表流是整个 FLUX 脚本最后返回的结果,而且这个结果的名字叫 _result。
当 FLUX 脚本中出现多个为赋值给变量的表流时,给多个表流自动补上 |>yield(name:"_result")就会出问题了,这是因为当有多个表流后面都有 |>yield时,其实相当于一个 FLUX 脚本会返回多个结果。但是此处要求名称是不能重复的,所以当有多个未赋值的表流时,就必须显示指定 yield(name:"xxx"),而且名称千万不可重复。
// 表流1
from(bucket:"test_init")
|> range(-1h)
|> aggregateWindow(period:30s,every:30s,fn:max)
|> max()
|> yield(name:"result1") // 给这个表流行取名为result1
// 表流2
from(bucket:"test_init")
|> range(-1h)
|> aggregateWindow(period:30s,every:30s,fn:max)
|> max()
|> yield(name:"result2") // 给这个表流行取名为result2
但是,在一个 FLUX 脚本里同时返回多个结果集并不是推荐的操作,这通常会让程序的逻辑变的很奇怪,我们之所以能在一个 FLUX 脚本里面写多次 from 函数,其实是为了方便我们进行 join的。
但是并不建议在 FLUX 脚本中使用 join 操作,
这必须要谈到 FLUX 脚本的常见使用场景,就是每隔一段时间进行一次查询。如果这个时候,我用一个 from 从 InfluxDB 中查询数据,其中有 code=01 等机器编号信息。然后我再用一个 from 去查询 mysql,得到一张机器的属性表。接下来对两张表进行 join,这在逻辑上很合理,但最大的问题就是 FLUX 脚本无法实现数据的缓存。如果我这个 FLUX 脚本是每 15 秒执行一次,那就会导致我们需要每 15 秒要去 mysql 上全表扫描一遍机器信息表,效率十分低下。
个人建议仅使用 FLUX 进行简单的查询,然后在应用层的程序代码里进行 join操作。
如果确实想用join,就在官方文档找到 join 的函数
6.2.2 常用聚合函数
max() // 各个序列中的最大值
sum() // 各个序列中所有数据点的总和
// 语法
from(bucket:"test_init")
|> range(start:-1h)
|>max()
6.2.3 类型转换函数
笔记6.1.4 中,存入不同的数据类型,会根据不同的数据类型进行分表显示,int被转成了float,所有需要类型转换
from(
bucket: "test_init")
|> range(start: -1h)
|> filter(fn: (r) => r["_measurement"] == "go_goroutines")
|> filter(fn:(r)=> r["_field"] == "int")
|> toint()
)
7. 交互工具
底层都是以http请求发送到InfluxDB,然后得到响应的过程
7.1 Http
国内开发的 postman 的平替版
InfluxDB API 文档
// 官方网站的文档
https://docs.influxdata.com/influxdb/v2/api/
// 本地服务部署的文档
http://127.0.0.1:8086/docs
7.1.1 检查InfluxDB
1.直接请求
请求路径
http://192.168.0.11:8086/health
请求方法
GET
响应结果
{
"name": "influxdb",
"message": "ready for queries and writes",
"status": "pass",
"checks": [],
"version": "v2.7.1",
"commit": "407fa622e9"
}
7.1.2. token 认证
请求路径
http://192.168.0.11:8086/api/v2/authorizations
请求方法
GET
在请求头添加 token
// 在请求头添加 键为 Authorization,值为 Token 开头 的键值对,如:
键 值
Authorization Token hzIU_PV0vB8XdXmjQWUR_pYuOco6QHVCvy-qFWqlqm1AF-coPppboXTwRgXblgrqX3FcjQJOGLfuhdC0np39OQ==

响应结果
{
"links": {
"self": "/api/v2/authorizations"
},
"authorizations": [
{
"id": "0bbee70707d67000",
"token": "uydcyd2Qhm2ICRwf7xgScfVla2hdk4xXgA0Rbvn-rUVXNHa81Cs5ZQWIG2jcbNjwz3OrZ03GsazXt3YNLEqNXA==",
"status": "active",
"description": "admin's Token",
"orgID": "f37463dbb03a486d",
"org": "vansing",
"userID": "0bbee706bc967000",
"user": "admin",
"permissions": [
{
"action": "read",
"resource": {
"type": "authorizations"
}
},
......
}
7.1.3 登录认证
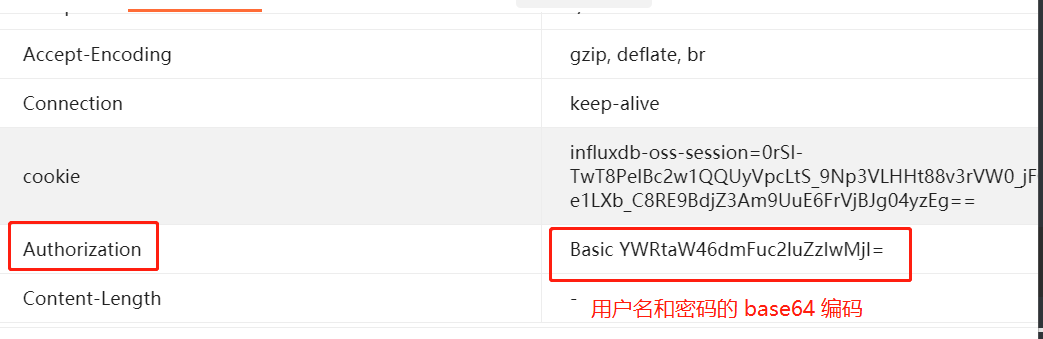
请求头中添加一个 键为Authorization 值为 Basic 账号: 密码 的base64编码格式
import base64
b64_str = base64.b64encode(("admin" + ":" + "admin123").encode("utf-8"))
key ="Authorization"
value = "Basic "+ b64_str
请求路径
http://192.168.0.11:8086/api/v2/signin
请求方法
POST
请求头
响应结果
请求成功后会设置一个cookie

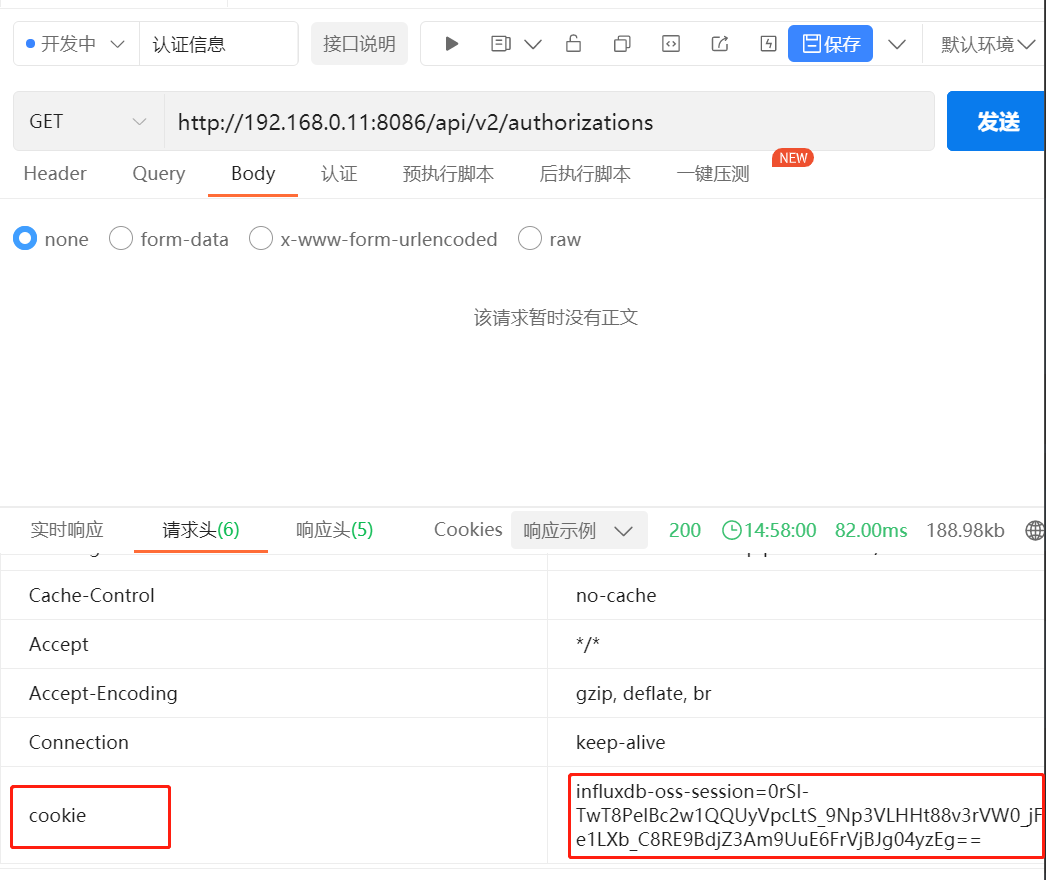
7.1.4 基于cookie访问接口(半小时过期)
基于上面的登录认证,会在本地设置一个cookie,每次请求接口的时候都需要携带 此cookie 去访问,同时这个 cookie 会有过期时间,默认是30分钟过期一次
7.1.5 登录认证安全--配置HTTPS
由于登录认证时,账号密码就是一个base64的编码串,这样很不安全,所以需要用https 加密,使用 openssl 执行如下命令
sudo openssl req -x509 -nodes -newkey rsa:2048 \
-keyout /etc/ssl/influxdb-selfsigned.key \
-out /etc/ssl/influxdb-selfsigned.crt \
-days <NUMBER_OF_DAYS>
参数解析:
- req -x509,指定生成自签名证书的格式。
- -newkey rsa:2048,生成证书请求或者自签名整数时自动生成密钥,然后生成的密钥名称由 keyout 指定。rsa:2048 意思是产生 rsa 密钥,位数是 2048。
- -keyout,指定生成的密钥名称。
- -out,证书的保存路径
- -days,证书的有效期限,单位是 day(天),默认是 365 天。
执行命令示例:
openssl req -x509 -nodes -newkey rsa:2048 \
-keyout /opt/module/influxdb2_linux_amd64/selfsigned.key \
-out /opt/module/influxdb2_linux_amd64/selfsigned.crt \
-days 60
执行这个命令后,会让你输入更多信息。你可以直接全部敲回车,将这些字段留空。不影响生成我们有效的证书文件。
执行完这个命令后,/opt/module/influxdb2_linux_amd/ 目录下会产生两个文件,一个是 selfsigned.crt(证书文件)另一个是 selfsigned.key(密钥文件)。而且他们的有效期是 60 天
7.1.6 快速导入InfluxDB所有接口
1.下载InfluxDB API 接口文件
http://127.0.0.1:8086/docs
2.API Post 导入
3. 点击swagger
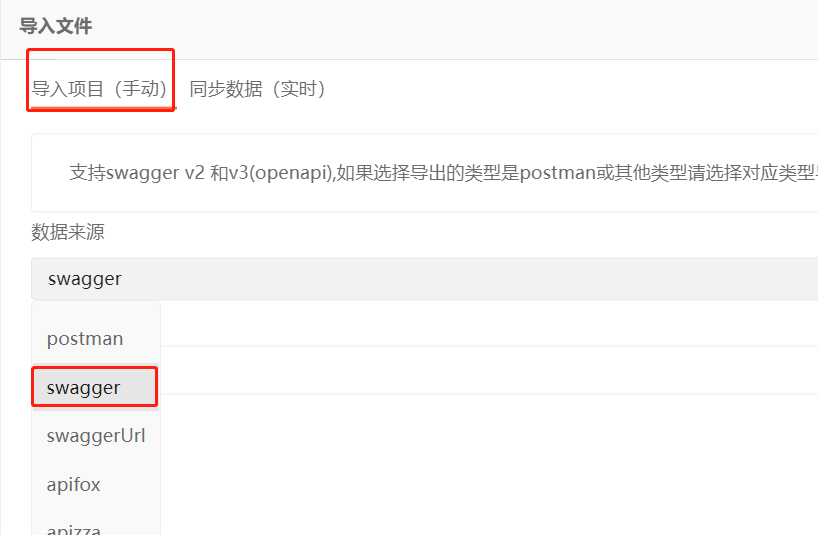
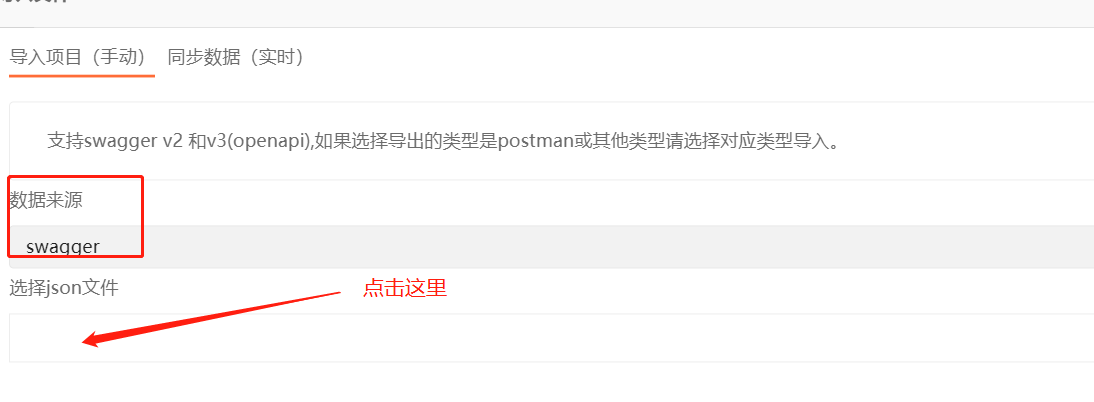
4. 选择文件,并点击立即导入
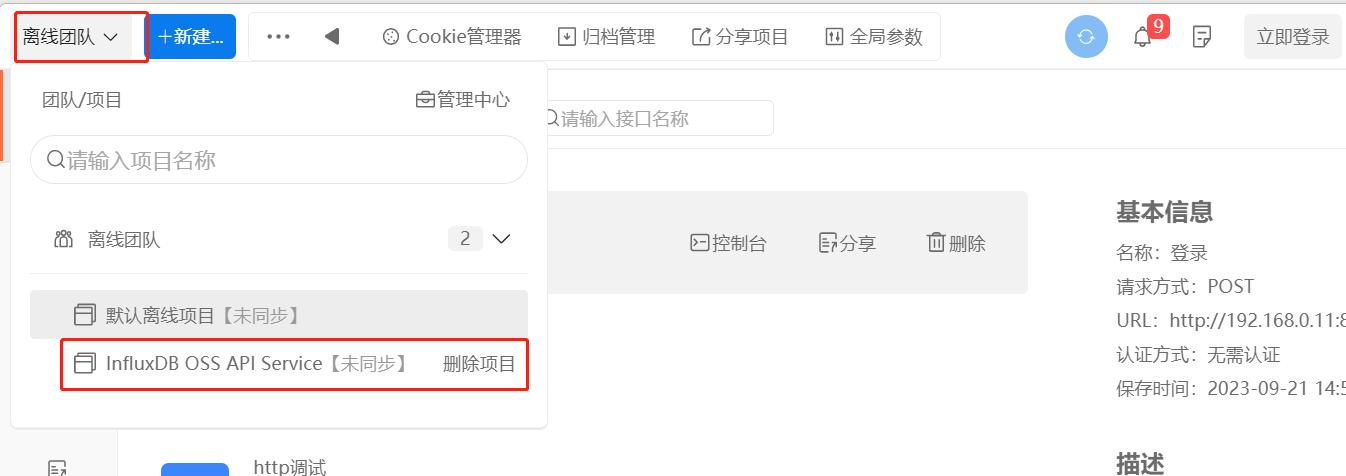
5.点击团队,可以看到新的项目
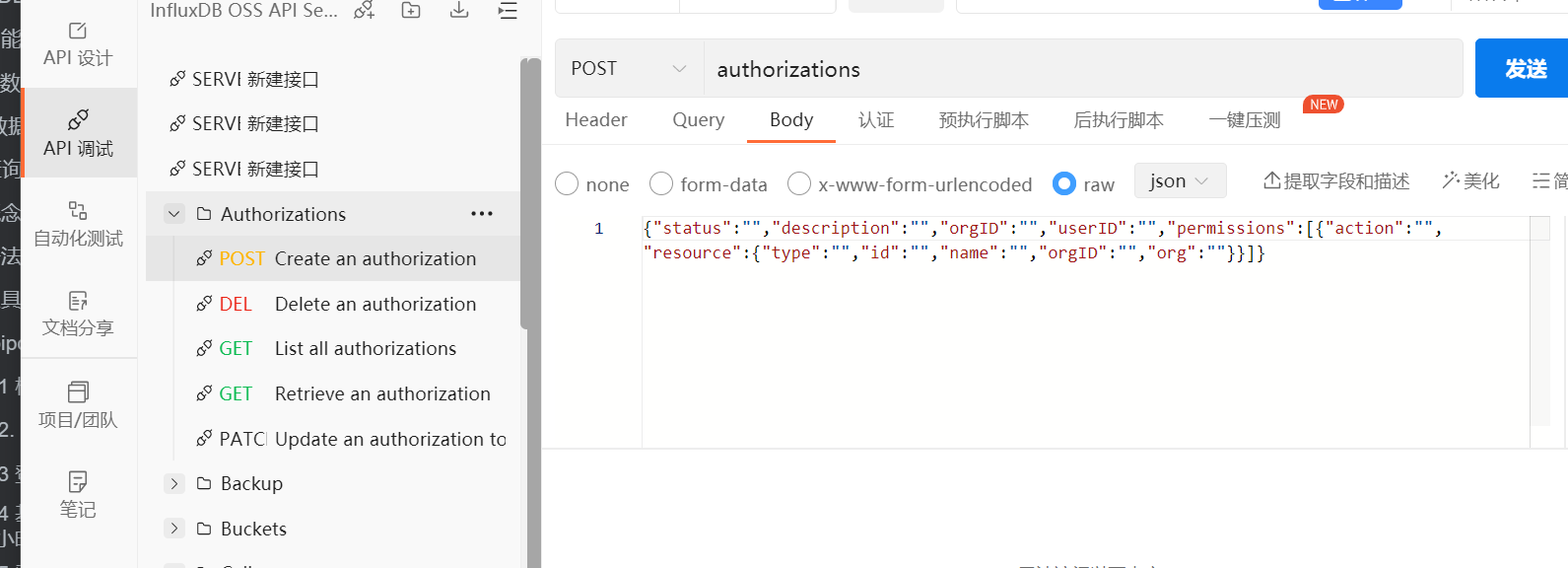
6.可以看到很多 API 接口
7.配置环境
可以发现各个接口只有路径没有ip和端口,所以需要配置环境

点击开始配置环境
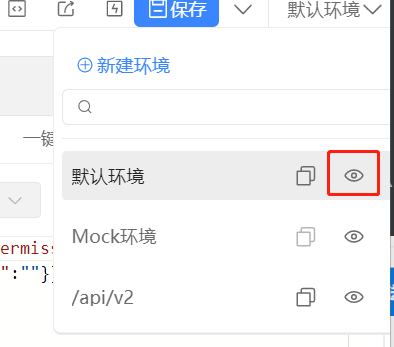
输入 URL 并保存
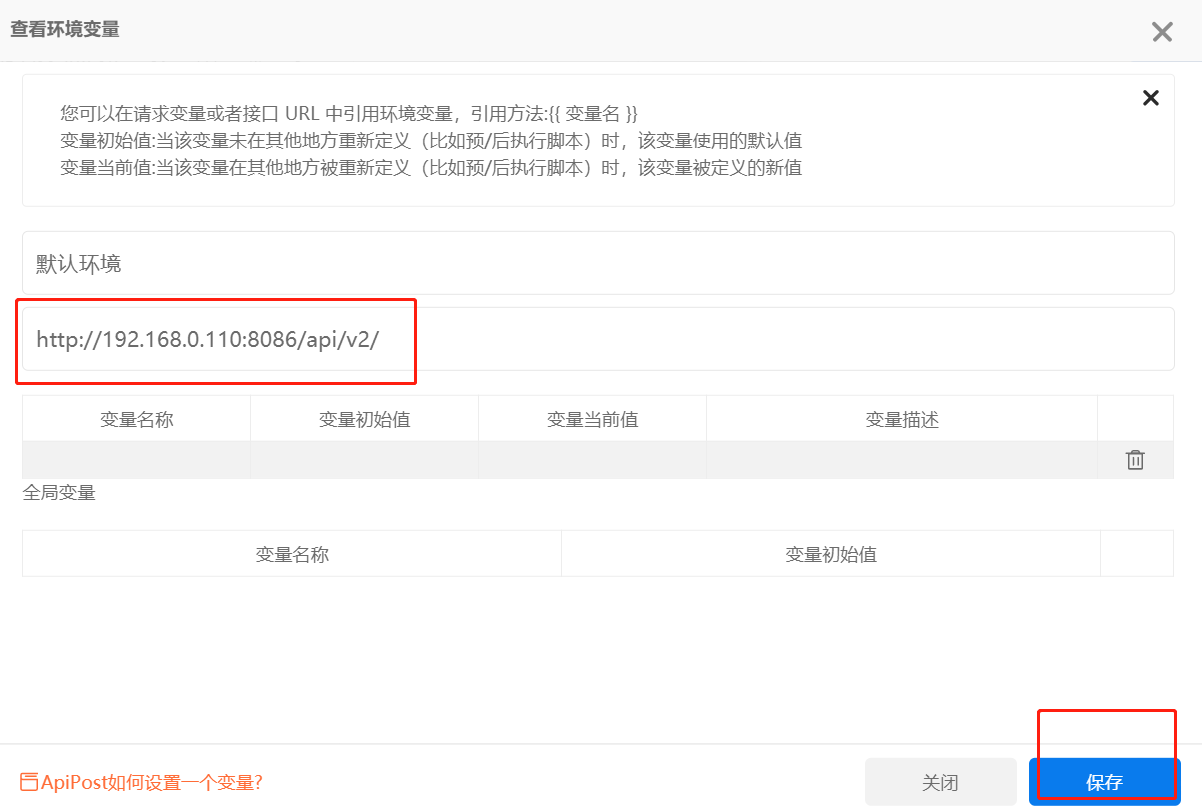
8.检查是否可以发送请求
找到 Ping文件夹下的get请求,点击发送

7.1.7 分页
请求路径
// 根据limit和offset来进行偏移的
http://192.168.0.11:8086/api/v2/buckets?limit=1&offset=5
请求方法
GET
7.1.8 存储桶查询
1. 查询所有的存储桶
请求路径
http://192.168.0.11:8086/api/v2/buckets
请求方法
GET
响应结果
{
"links": {
"self": "/api/v2/buckets?descending=false&limit=20&offset=0"
},
"buckets": [
{
"id": "06350ef7bad662e2",
"orgID": "10632d7f3538516f",
"type": "user",
"name": "111",
}
{
"id": "1f837f75e78d29c9",
"orgID": "f37463dbb03a486d",
"type": "user",
"name": "com",
},
.....
]
}
2. 分页查询存储桶
请求路径
http://192.168.0.11:8086/api/v2/buckets?limit=1&offset=1
请求方法
GET
响应结果
{
"links": {
"prev": "/api/v2/buckets?descending=false&limit=1&offset=0",
"self": "/api/v2/buckets?descending=false&limit=1&offset=1",
"next": "/api/v2/buckets?descending=false&limit=1&offset=2"
},
"buckets": [
{
"id": "1f837f75e78d29c9",
"orgID": "f37463dbb03a486d",
"type": "user",
"name": "com",
......
}
]
}
7.1.9 查询数据
请求路径
// orgID 为组织ID
http://192.168.0.11:8086/api/v2/query?orgID=f37463dbb03a486d
// 或者组织名称
http://192.168.0.11:8086/api/v2/query?org=vansing
请求方法
POST
请求头设置
Authorization token串
Accept application/csv
Content-Type application/vnd.flux 或者 application/json
Accept-Encoding gzip // 压缩模式,建议仅对大于 1.4 KB 的响应使用 gzip 压缩。 如果响应小于 1.4 KB,gzip 编码将始终返回 1.4 KB 响应,尽管响应大小未压缩。 1500 字节 (~1.4 KB) 是公众的最大传输单元 (MTU) 大小 网络,是网络层允许的最大数据包大小。
请求体
{
"query":"import \"regexp\"\n\n from(bucket: \"baler\")\n |> range(start: -6h, stop: now())\n |> filter(fn: (r) => (r[\"_measurement\"] == \"coll_vfd_fault\"))\n |> keep(columns: [\"_field\"])\n |> group()\n |> distinct(column: \"_field\")\n |> limit(n: 1000)\n |> sort()", // 每行查询代码后加\n
"dialect":{
"annotations":["group","datatype","default"]
}
}
响应结果
7.2 命令行工具
官方文档
// 操作文档
https://docs.influxdata.com/influxdb/v2/tools/influx-cli/
// 命令行文档
https://docs.influxdata.com/influxdb/v2/reference/cli/
7.2.1 下载及启动
注意: 一定要和服务端的版本一致
github下载
https://github.com/influxdata/influx-cli
找到Releases, 发行版
国内用的CPU一般是 x86的架构,需要下载amd64的安装包
2. 启动
# 帮助命令
./influx --help
# 启动命令
./influx v2
7.2.2 命令行工具配置
1. 查看当前配置
./influx config
2. 创建配置文件
influx 命令行工具是你每执行一次操作时,调用一次命令。并不是开启一个持续性的会话。而 influx 其实底层还是封装的对 InfluxDB 的服务进程的 http 请求。也就是它还是需要配置 Token 什么的来获取授权。所以,为了避免以后每次请求的时候都在命令行里面写一遍 token。我们应该先去搞个配置文件。 使用下面的命令可以创 influx 命令行的配置。
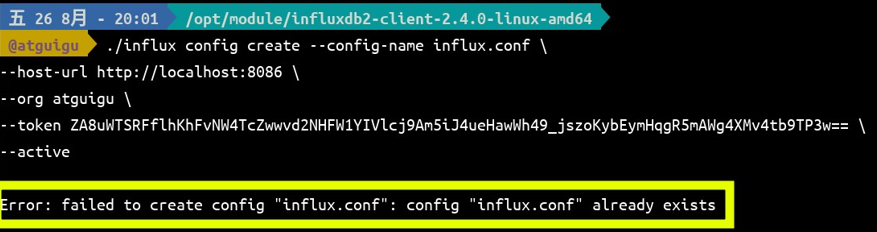
./influx config create --config-name influx.conf --host-url http://localhost:8086 --org atguigu --token ZA8uWTSRFflhKhFvNW4TcZwwvd2NHFW1YIVlcj9Am5iJ4ueHawWh49_jszoKybEymHqgR5mAWg4XMv4tb9TP3w== --active
这个命令其实会在~/.influxdbv2/目录下创建一个 configs 文件,这个文件中,就是我们命令行中写的各项配置。

3. 更改配置
如果你中途配置错误了,再使用上文的命令,它会说这个配置已经存在。也就是说,在 /home/dengziqi/.influxdbv2/configs 文件中,["name"]配置快不能重复必须全局唯一。这个时候如果你想调整配置,应该把 create 换成 update。
./influx config update --config-name influx.conf xxxxxxxx
4. 在多份配置之间切换
我们现在用下面的命令再创建一个配置,直接复制 influx.conf 中的内容,把名字修改成 influx2.conf
./influx config create --config-name influx2.conf \
--host-url http://localhost:8086 \
--org atguigu \
--token
ZA8uWTSRFflhKhFvNW4TcZwwvd2NHFW1YIVlcj9Am5iJ4ueHawWh49_jszoKybEym
HqgR5mAWg4XMv4tb9TP3w== \
--active
命令成功执行后,再次打开 ~/.influxdbv2/configs 文件。

可以看到 configs 中的文件内容变了,多了一个名为["influx2.conf"]的配置块,而且,旧的["influx.conf"]从 active="true"变成了 previous="true",同时["influx2.conf"]中有一个active="true"的键值对。说明,如果现在使用 influx-cli 执行操作,那会直接使用influx2.conf 配置块中的内容。
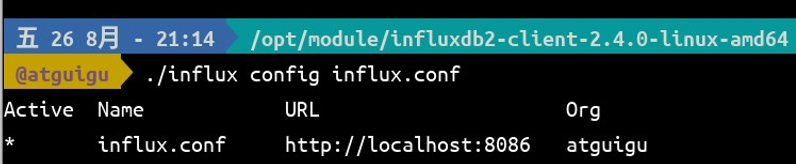
切换当前正在使用的配置。
influx config influx.conf
再次查看 ~/.influxdbv2/configs 文件
vim ~/.influxdbv2/configs

4. 删除一个配置
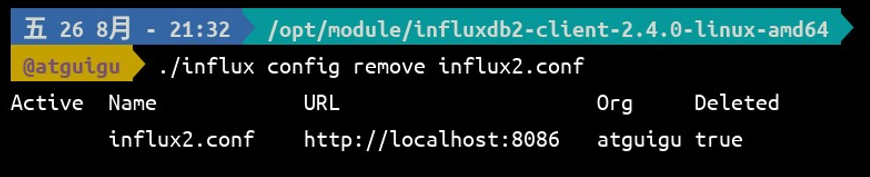
influx2.conf 现在对我们来说是多余的了,现在,我们将它删除掉。使用下面的命令删除 influx2.conf。
./influx config remove influx2.conf
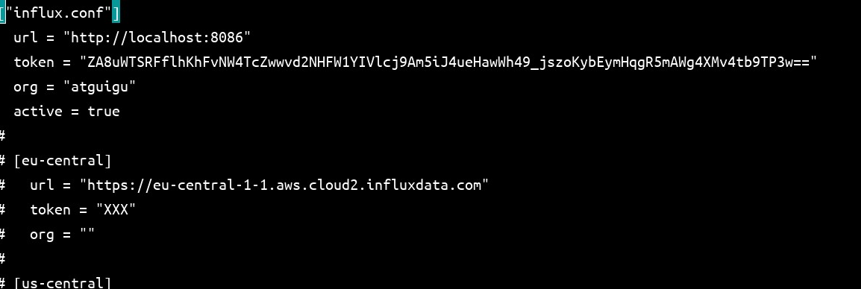
执行后,再次查看 ~/.influxdbv2/configs文件,可以看到,["influx2.conf"]消失了。而且,我们的 influx.conf 自动变成了 active=true。
vim ~/.influxdbv2/configs
7.3 python
7.3.1 请求代理到InfluxDB
1. GET 方法
- 请求的
url地址,放在请求体中 - 请求参数放其他参数,用
urlencode()解析前端发的请求,然后再经过python转发到InfluxDB
class SelectDataView(APIView):
def get(self, request):
"""
代理URL>> http://127.0.0.1:8777/select_data?limit=1&offset=0
InfluxDB>> http://192.168.0.11:8086/api/v2/buckets?limit=1
"""
url = request.POST.get("url") # 如:buckets
headers = {
"Authorization": "Token " + settings.INFLUXDB_DATABASES.get("default").get("TOKEN")
}
result = requests.get(
url=settings.INFLUXDB_DATABASES.get("default").get("URL") + url + "?" + urlencode(request.GET),
headers=headers)
if result.status_code == 200:
return PublicRes(data=result.json())
else:
return PublicRes(10000, error_msg="参数错误")
2. POST 方法
- 请求的
url地址,放在请求参数中 - 请求体是
json格式的请求体参数,打开InfluxDB的UI界面直接复制请求体参数{"query":"from(bucket: \"baler\")\n |> range(start: v.timeRangeStart, stop: v.timeRangeStop)\n |> filter(fn: (r) => r[\"_measurement\"] == \"coll_vfd_fault\")\n |> filter(fn: (r) => r[\"_field\"] == \"fault_previous_bus_voltage\")\n |> filter(fn: (r) => r[\"coll_device_id\"] == \"11\")\n |> filter(fn: (r) => r[\"collector_id\"] == \"1\")\n |> filter(fn: (r) => r[\"product_mgt_id\"] == \"2\")\n |> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)\n |> yield(name: \"mean\")","extern":{"type":"File","package":null,"imports":null,"body":[{"type":"OptionStatement","assignment":{"type":"VariableAssignment","id":{"type":"Identifier","name":"v"},"init":{"type":"ObjectExpression","properties":[{"type":"Property","key":{"type":"Identifier","name":"timeRangeStart"},"value":{"type":"UnaryExpression","operator":"-","argument":{"type":"DurationLiteral","values":[{"magnitude":30,"unit":"d"}]}}},{"type":"Property","key":{"type":"Identifier","name":"timeRangeStop"},"value":{"type":"CallExpression","callee":{"type":"Identifier","name":"now"}}},{"type":"Property","key":{"type":"Identifier","name":"windowPeriod"},"value":{"type":"DurationLiteral","values":[{"magnitude":3600000,"unit":"ms"}]}}]}}}]},"dialect":{"annotations":["group","datatype","default"]}}
Python实现方法:
class SelectDataView(APIView):
def post(self, request):
"""
代理URL>> http://127.0.0.1:8777/select_data?url=query
InfluxDB>> http://192.168.0.11:8086/api/v2/query?org=vansing
"""
headers = {
"Authorization": "Token " + settings.INFLUXDB_DATABASES.get("default").get("TOKEN"),
"Accept": "application/csv",
"Content-Type": "application/json",
}
url = request.GET.get("url", "")
json_str = request.data
glbparam = GlobalParameters.objects.filter(code_str="influxdb_org")
if not glbparam.exists():
return PublicRes(10000, error_msg="未配置全局参数")
result = requests.post(
url=settings.INFLUXDB_DATABASES.get("default").get("URL") + url + "?org=" + glbparam.first().value_str,
headers=headers, json=json_str)
if result.status_code == 200:
return PublicRes(data=result.text)
else:
print("error:>>", result.json())
return PublicRes(10000, error_msg=result.json())
7. InfluxDB常用配置
7.1 https配置
1. 生成公私钥
由于登录认证时,账号密码就是一个base64的编码串,这样很不安全,所以需要用https 加密,使用 openssl 执行如下命令
sudo openssl req -x509 -nodes -newkey rsa:<BYTE_NUM> \
-keyout <KEY_NAME> \
-out <KEY_PATH> \
-days <NUMBER_OF_DAYS>
参数解析:
- req -x509,指定生成自签名证书的格式。
- -newkey rsa:2048,生成证书请求或者自签名整数时自动生成密钥,然后生成的密钥名称由 keyout 指定。rsa:2048 意思是产生 rsa 密钥,位数是 2048。
- -keyout,指定生成的密钥名称。
- -out,证书的保存路径
- -days,证书的有效期限,单位是 day(天),默认是 365 天。
执行命令示例:
openssl req -x509 -nodes -newkey rsa:2048 \
-keyout /opt/module/influxdb2_linux_amd64/selfsigned.key \
-out /opt/module/influxdb2_linux_amd64/selfsigned.crt \
-days 60
执行这个命令后,会让你输入更多信息,如证书颁发公司,证书颁发日期等。你可以直接全部敲回车,将这些字段留空。不影响生成我们有效的证书文件。
执行完这个命令后,/opt/module/influxdb2_linux_amd/ 目录下会产生两个文件,一个是 selfsigned.crt(证书文件)另一个是 selfsigned.key(密钥文件)。而且他们的有效期是 60 天
2. 权限检查
确保启动 influxd 的用户对密钥整数文件有读取权限
**3.启动 influxd 服务时指定证书和密钥路径 **
使用 influxd 命令启动 InfluxDB 服务时,记得指定一下整数的密钥的路径。
./influxd --tls-cert="/opt/module/influxdb2_linux_amd64/selfsigned.crt" --tls-key="/opt/module/influxdb2_linux_amd64/selfsigned.key"
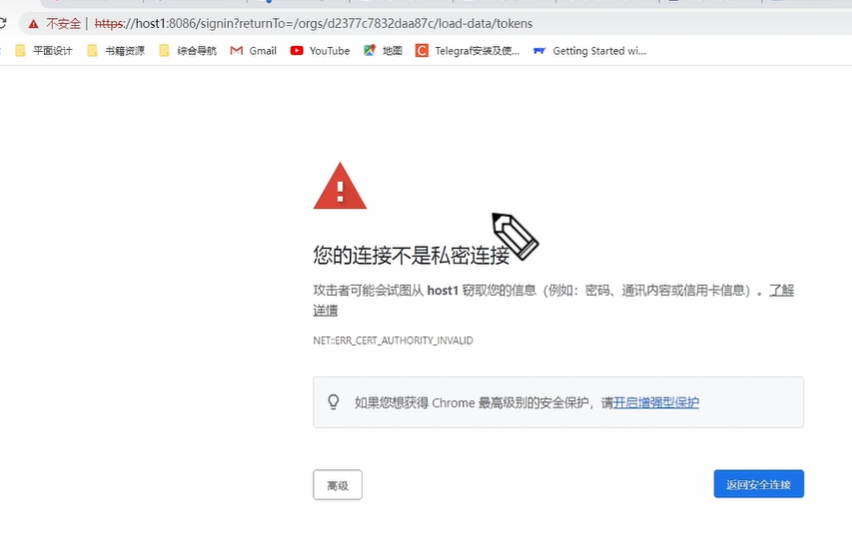
**4. 验证 HTTPS 协议是否生效 **
web页面访问,会出现如下界面,是因为证书是自己生成的,而不是专门的机构颁发的,机构会备案你的证书和网站的实名制信息和资格审核,以保证 https 不会被盗用,发送请求的时候浏览器会拿着当前的证书到机构那里去查询,如果没有查到,则会出现这个提示页面,所以浏览器不信任这个证书,当前网站有可能是假冒的
需要注意的是https 默认端口是443,如果是云服务器 需要开放443端口
回到我们的 ApiPost6,再次向 http:/localhost:8086/api/v2/authorizations 发送 GET 请求
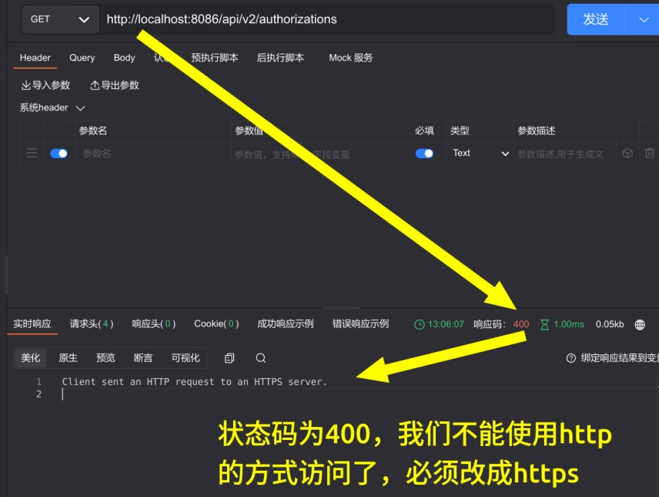
可以看到,我们使用 http 的协议头再进行访问,响应的状态码为 400,并提示我们向 HTTPS 服务器发送了一个 HTTP 请求。现在我们将 URL 前面的 http 改成 https 再试一下。
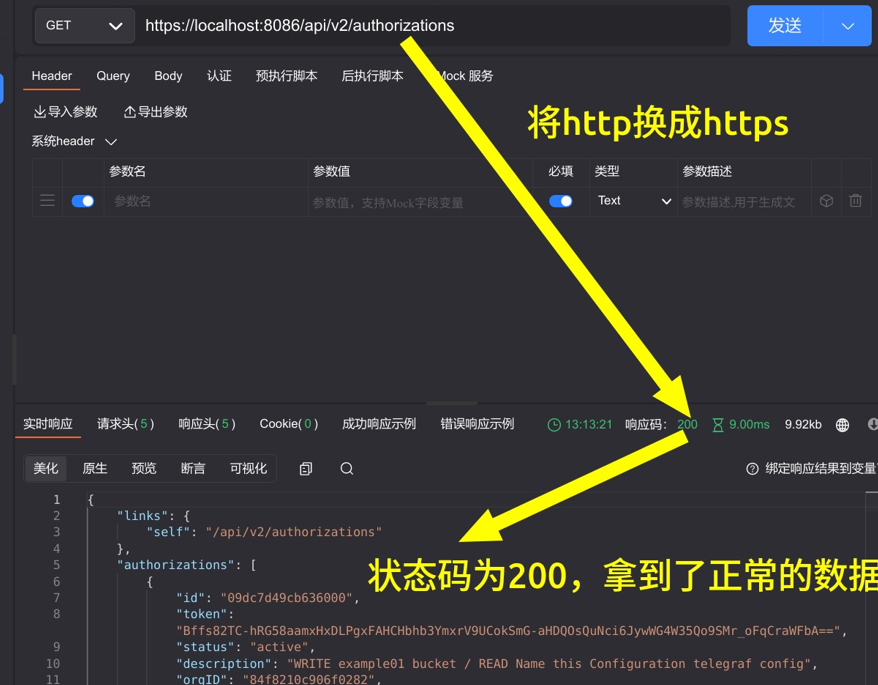
7.2 IP 白名单
官方文档
https://docs.influxdata.com/influxdb/v2.4/security/enable-hardening/
这个 IP 白名单并不是限制谁可以访问我的,而是用来限制 InfluxDB 的查询可以访问谁的。因为 FLUX 语言具有发送网络请求的能力,你可以使用 InfluxDB 的相关配置限定,FLUX 脚本可以向哪些地址发送请求
7.3 机密管理
官方文档
https://docs.influxdata.com/influxdb/v2.4/security/secrets/
假如,我们的自己的应用程序和 InfluxDB 集成,而用到的一段 FLUX 脚本刚好需要使用某个第三方服务的用户名和密码(比如查询 mysql)。
import "influxdata/influxdb/secrets"
import "sql"
sql.from(
driverName: "postgres",
dataSourceName: "postgresql://tony:11111111@localhost",
query:"SELECT * FROM example-table",
)
应用和 InfluxDB 服务之间走的也是 HTTP 通信,那么写在脚本中的用户名和密码是有可能泄漏的。这个时候,你可以把用户名和密码用键值的方式放到 InfluxDB 管理起来,然后,你就可以在脚本里用 key 的方式在 InfluxDB 里获取 tony 的用户名和密码了,这样,我们 Mysql 的用户名和密码,就没有在网络上泄漏的风险了。
import "influxdata/influxdb/secrets"
import "sql"
username = secrets.get(key: "POSTGRES_USERNAME")
password = secrets.get(key: "POSTGRES_PASSWORD")
sql.from(
driverName: "postgres",
dataSourceName: "mysql://${username}:${password}@localhost",
query:"SELECT * FROM example-table",
)
7.4 token 管理
官方文档
https://docs.influxdata.com/influxdb/v2.4/security/tokens/
Token 的类型
- 操作者 Token。
- 操作者令牌有跨越组织的管理权限,它对 InfluxDB OSS 2.x 上的所有组织和资源有完全的读写访问权限。某些操作必须需要操作员权限(比如 查看服务器配置)。操作者 Token 是在 InfluxDB 初始化设置的过程中创建的。要想再创建一个操作者Token,就必须使用先有的操作者 Token。 由于操作者 Token 对 InfluxDB 中所有的组织具有完全的读写访问权限。因此 InfluxDB 建议为每个组织创建一个全权限 Token,并用这些 Token 来管理 InfluxDB。这有助于防止组织间不小心误操作对方资源。
- 全权限 Token。对单个组织中所有资源的完全读取和写入访问权限
- 读/写 Token。对组织中特定的存储桶进行读取和写入。
7.5 禁用部分功能
官方文档
https://docs.influxdata.com/influxdb/v2.4/security/disable-devel/
InfluxDB 的 API 中,有一部分是为了方便外部系统去监控和观测 InfluxDB 的状态和性能的。如果你觉得这部分可能影响安全,那么你可以随时把它们禁了。
- /metrics,上文给大家演示过,这里面有各种监控 InfluxDB 运行的指标
- Web UI,用户的图形界面交互。
- /debug/pprof,这个接口里面是 Go 语言程序的运行时指标,比如堆内存用了多少,有多少线程数等等。
7. 时间的标准与格式
7.1 GMT(格林威治标准时间)
格林威治(又译格林尼治)它是一个位处英国伦敦的小镇。
17 世纪,英国航海事业发展迅速,当时海上航行亟需精确的精度指示,于是英国皇家在格林威治这个地方设立了一个天文台负责测量正确经度的工作。
后来 1884 年,在美国华盛顿召开的国际经度会以决定以经过格林尼治天文(旧址)的经线为本初子午线(0 度经线)。同时这次会以也将全球划分为了 24 个时区。0 度经线所在的时区为 0 时区。
现在,有时候你要买一个机械表,如果它说支持 GMT,意思就是支持显示格林威治标准时间。
7.2 UT(世界时)
1928 年,国际天文联合会提出了 UT 的概念,UT 主要用来衡量一天究竟有多长。一旦一天的长度可以确定,那么将这个长度除以 24 就能确定一小时的长度。以此类推、分钟、秒的长度我们就都能确定了。
UT 也是以格林威治时间作为标准的,它规定格林威的子夜为 0 点。
在当时,衡量一天长度的方法就是通过天文观测,看地球多久转一圈。但一来天文观测存在误差。二来,地球的自转越来越慢。计时方法亟需革新。
7.3 计时技术与国际原子时
人类历史上出现的计时手段大体上能分为三类
- 试图通过某种匀速的运动来表示时间、比如沙漏、水钟、香钟(烧香)。这种方式的缺陷很大,是一种很粗略的时间衡量方法
- 通过天文观测,通过日月或其他星辰的参考确定时间。现在我们已经知道,星系的运动也不是匀速的过程。
- 通过固定频率的震动,最早是伽利略通过教堂的吊灯发现了摆的等时性,也就是摆角较小时,吊灯摆动一次的时间是相同的。距今三四百年前的摆钟,基本上都是利用这一原理实现的。
现在,人类已知的最精确的计时技术是原子钟,它以原子共振频率标准来计算和保持时间的准确。它的精度可以达到持续运行上亿年而误差不超过 1 秒。
基于这种技术,后来国际计量协会结合了全球 400 多个原子钟,规定 1 秒为铯-133 原子基态两个超精细能级间跃迁辐射震荡 9,192,631,770 周所持续的时间。这个定义就叫国际原子时(International Atomic Time, TAI)。这样,我们钟表里指针应该转多快也有了一个统一的标准。
国际原子时的秒长以格林威治时间 1958 年 1 月 1 日 0 时的秒长为基准。也就是规定,在这一瞬间,国际原子时的秒长和世界时的秒长是一样的。
7.4 UTC(世界协调时)
UTC,universal Time Coordinated。世界协调时,世界统一时间、国际协调时。它以国际原子时的秒长为基准。但是我们知道,UT 基于天文观测,地球越来越慢那 UT 的秒长应该越来越长。如果不进行干预那么 UTC 和 UT 之间就会有越来也大的误差,
如下图所示:
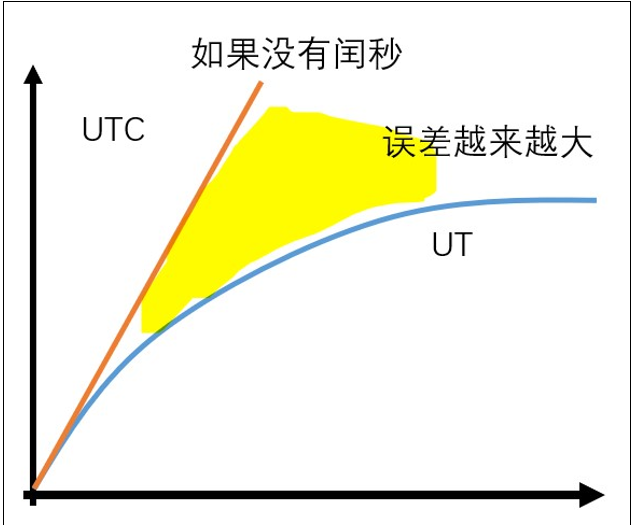
如果这种状况持续下去,在好多好多好多好多年后,人类可能就是 UTC 时间凌晨 3 点起床挤地铁上班了。因此,让 UTC 符合人类生活习惯,就必须控制 UTC 和 UT 的误差大小,于是 UTC 引入了闰秒。所谓闰秒,也就是让在某个时间点上,人为规定这一分钟比普通的分钟多一秒,它有 61 秒。这个时候 1 分 59 秒过了应该接着是 2 分 0 秒,但是在遇到闰秒时会遇到 1 分 60 秒
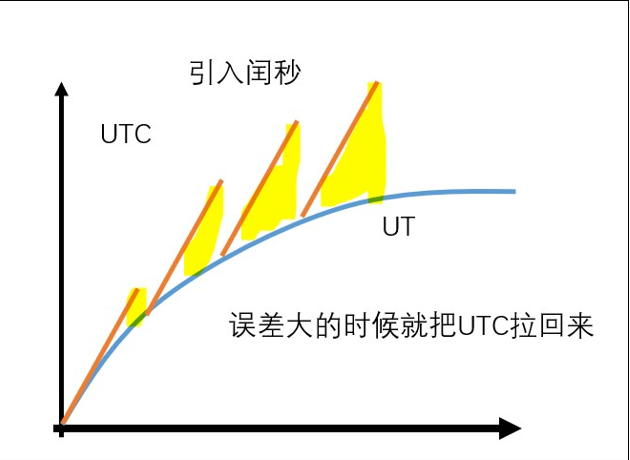
看似好像也能接受。但是何时加入闰秒是不可预测的。它是由国际地球自转服务(IERS)每隔一段时间依据实际情况决定的。对计算机的程序而言,闰秒机制具有明显的破坏性,相关国际标准机构一直在讨论是否继续这种做法。
7.5 总结
UTC/GMT
- GMT 是最早的国际时间标准,后来是 UTC。
- 因为 UTC 要逼近 UT,而 UT 又以 GMT 为标准。十分严格地说,UTC 和 GMT 不是一个东西。但宽松地说,你可以把 UTC 等同于 GMT,而且有些网站和应用程序就是这么干的。
- 因为 UTC 标准已经使用多年。所以现在如果再看到 GMT 这个词,它指的通常不是国际时间,而是格林威治所在的时区,也就是 0 时区。同时,通常行政区有很多适应自己所在地的时区缩写,遗憾的是,这种写法经常会撞车。
比如,CCT,它可以表示美国中部时间(Central Standard Time),澳大利亚中部时间(Central Standard Time),中国标准时间(China Standard Time)和古巴标准时间(Cuba Standard Time)
所以、如果我写 CCT 2022-08-03 11:56 就很容易误解了。这个时候我们非常需要一种没有歧义的日期时间写法。
7.6 时区与 UTC 偏移量
现行的时区表示更多是使用 UTC+偏移量的方式来表示的。比如北京是在东 8 区,时间比 UTC 要早 8 小时,那么在表示北京时区的方式就是 UTC+08:00。虽然地理界定上只有东西十二区,但是什么地方采用什么方式表达时间实际取决于当地的行政命令。因此UTC+12:00 并不是偏移量的上限。打开你电脑上的日期时间设置,你会发现有的的国家采用的是 UTC+14:00。还有的国家偏移量并不完全是小时的整数倍,比如 UTC+12:45。
同时,也有很多应用会使用 GMT+0800 的方式表示,效果是一样的。
7.7 日期时间的表示格式
2022 年 9 月 3 日该怎么表示?是 2022/09/03 还是 2022-09-03 还是 Sep 03 2022 ?这又是一个标准问题,当前的情况是,各个国家有符合本地习惯的日期时间格式标准,同时国际上也有诸多日期时间格式标准,比如 ISO 8601 和 RFC3339 等。
各种格式都有软件采用,所以编程语言中的日期标准库,一般都会准备dateformat 工具,自己编码日期时间的格式
7.8 ISO 8601
国际标准 ISO 8601,是国际标准化组织的日期和时间的表示方法和我们之前提过的 UTC 不同,UTC 是一种时间标准,而 ISO 8601 是一种标准的时间格式,大多数的编程语言都支持。
使用 ISO 8601 格式可以明确表示下面的时间。
- 公历日期
- 24 小时制的时间
- UTC 时区偏移量
- 时间间隔
- 以及上面几种元素的组合。
ISO 8601 的表示非常灵活,这里不会将其完全列出,我们直说最常见的日期时间格式。
比如,下面就是一个符合 ISO 8601 的日期时间表示。
2022-09-03T14:13:00Z,这个时间戳中间的 T 用来分隔 日期 和 时间,最后字母 Z 表示
0 时区,也就是 UTC 或 GMT 时间。
7.9 RFC 3339
RFC 是 request for comment 的简写。它其实是一系列加了编号的文件。这一系列文件收集了有关互联网的文章,包括 UNIX 和某些互联网社区上的软件文件。RFC 还收录了很多与互联网标准相关的文章,包含各种网络协议,以及我们今天要谈及的时间格式标准问题。 RFC3339 这篇文章的原文标题叫作,Date and Time on the Internet:Timestamps(互联网上的日期和时间:时间戳),发表的时间是 2002 年 7 月。感兴趣的同学可以参考原文: [https://www.rfc](https://www.rfc-editor.org/rfc/rfc3339)[-](https://www.rfc-editor.org/rfc/rfc3339)[editor.org/rfc/rfc3339](https://www.rfc-editor.org/rfc/rfc3339)[ ](https://www.rfc-editor.org/rfc/rfc3339) 简单来说 RFC3339 对日期时间的定义更加简洁,去掉了 ISO 8601 中一些小众的表达方式,也更具有可读性。 7.10 RFC3339 和 ISO8601 之间的关系
可以参考:https://ijmacd.github.io/rfc3339-iso8601/
这个网站可以实时展示当前时间的 RFC3339 表示和 ISO 8601 表示。下面这张图是它的截图。可以看到 RFC 3339 的表述有一部分和 ISO 8601 是相同的。

仔细去看你会发现,RFC3339 格式的日期时间表述,基本上都能第一时间反应出来它表述的是什么时间。而 ISO 8601 中就会有像 2022-242T16:55:17/PT3H 这种看上去奇奇怪怪的表述。
Unix 时间戳与闰秒
24.12.1 什么是 Unix 时间戳
Unix 时间戳是一种将时间跟踪为运行总秒数的方法,这个技术从 1970 年 1 月 1 日的 UTC 开始。因此,Unix 时间戳只表示从特定时间点到现在的秒数。而且,需要注意的是,无论你身处何,这个总秒数的值在技术上都不会发生改变。所以这对计算机系统,客户端和服务端的通信和日期跟踪十分有用。
7.11 Unix 时间戳是怎么处理闰秒的
关于闰秒问题,我们之前说过,什么时候出现闰秒是不确定的。那么在 Unix 时间戳里,是怎么处理闰秒的呢?答案是减慢时钟。
比如 1997 年 6 月 30 日 23:59:59 到 1997 年 7 月 1 日 00:00:00 应该发生一次闰秒。
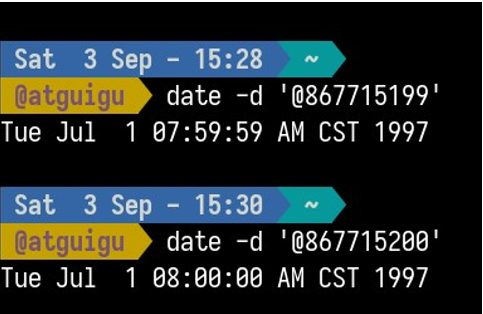
那么 867715200 这个时间戳应该对应 1997 年 6 月 30 日的 23:59:60。但是 Linux 好像压根不知道这件事。这是因为 Unix 时间戳标准里,把一天定死为 86400 秒了。所以类 Unix 的处理方案是,当闰秒发生时由 ntrp 服务把时钟慢下来,当时间戳为 867715199 的时候,让它在这个值上多停留 1 秒然后再进入 867715200。
8. 行协议数据格式
8.1 认识 InfluxDB 行协议
InfluxDB 行协议是 InfluxDB 数据库独创的一种数据格式,它由纯文本构成,只要数据符合这种格式,就能使用 InfluxDB 的 HTTP API 将数据写入数据库。与 CSV 相似,在 InfluxDB 行协议中,一条数据和另一条数据之间使用换行符分隔,所以一行就是一条数据。另外,在时序数据库领域,一行数据一行数据由下面 4 种元素构成。
- measurement(测量名称)
- Tag Set(标签集)
- Field Set(字段集)
- Timestamp(时间戳)

8.1.1 measurement(测量名称)
必选字段
测量的名称: 你可以将它当作普通关系型数据的 table,虽然实际上不是这么回事
写入规则:
- 测量名称不可省略。
- 大小写敏感
- 不可以用下划线_打头
8.1.2 Tag Set(标签集)
标签应该用在一些值的范围有限(可枚举)的,不太会变动的属性上。比如传感器的类型和 id 等等。在 InfluxDB 中一个 Tag 相当于一个索引。给数据点加上 Tag 有利于将来对数据进行检索。但是如果索引太多了,就会减慢数据的插入速度。
可选字段
写入规则:
- 键值关系使用=表示
- 多个键值对之间使用英文逗号 , 分隔
- 标签的键和值都区分大小写
- 标签的键不能以下划线 _ 开头键的数据类型:字符串值的数据类型:字符串
8.1.3 Field Set(字段集)
必选字段
一个数据点上所有的字段键值对,键是字段名,值是数据点的值。
写入规则:
- 一个数据点至少要有一个字段。
- 字段集的键是大小写敏感的。
- 键的数据类型:字符串
- 值的数据类型:浮点数 | 整数 | 无符号整数 | 字符串 | 布尔值
8.1.4 Timestamp(时间戳)
可选字段
数据点的 Unix 时间戳,每个数据点都可以制定自己的时间戳。如果时间戳没有指定。那么 InfluxDB 就使用当前系统的时间戳。
数据类型:Unix timestamp
写入规则:
- 如果你的数据里的时间戳不是以纳秒为单位的,那么需要在数据写入时指定时间戳的精度。
8.1.5 空格
行协议中的空格决定了 InfluxDB 如何解释数据点,第一个未转义的空格将测量值&Tag Set(标签集)与 Field Set(字段集)分开。第二个未转义空格将 Field Set(字段级)和时间戳分开。

8.2 数据类型
8.2.1 Float(浮点数)
IEEE-754 标准的 64 位浮点数。这是默认的数据类型。
字段级值类型为浮点数的行协议
myMeasurement fieldKey=1.0 myMeasurement fieldKey=1 myMeasurement fieldKey=-1.234456e+78
8.2.2 Integer(整数)
有符号 64 位整数。需要在数字的尾部加上一个小写数字 i 。
| 整数最小值 | 整数最大值 |
|---|---|
| -9223372036854775808i | 9223372036854775807i |
字段值类型为有整数的
8.2.3 UInteger(无符号整数)
无符号 64 位整数。需要在数字的尾部加上一个小写数字 u 。
| 无符号整数最小值 | 无符号整数最大值 |
|---|---|
| 0u | 18446744073709551615u |
字段值类型为无符号整数的行协议
myMeasurement fieldKey=1u myMeasurement fieldKey=12485903u
8.2.4 String(字符串)
普通文本字符串,长度不能超过 64KB
String measurement name, field key, and field value myMeasurement fieldKey="this is a string"
8.2.5 Boolean(布尔值)
true 或者 false。
示例:
| 布尔值 | 支持的语法 |
|---|---|
| True | t, T, true, True, TRUE |
| False | f, F, false, False, FALSE |
// 不要对布尔值使用引号,否则会被解释为字符串
myMeasurement fieldKey=true myMeasurement fieldKey=false myMeasurement fieldKey=t myMeasurement fieldKey=f myMeasurement fieldKey=TRUE myMeasurement fieldKey=FALSE
8.2.6 Unix Timestamp(Unix 时间戳)
myMeasurementName fieldKey="fieldValue" 1556813561098000000
8.2.7 注释
以井号 # 开头的一行会被当做注释。
# 这是一行数据
myMeasurement fieldKey="string value" 1556813561098000000
9. Prometheus 数据格式
9.1 认识Prometheus 数据格式
Prometheus 也是一种时序数据库,不过它通常被用在运维场景下。Prometheus 是开放原子基金会的第二个毕业项目,这个基金会的第一个毕业项目就是大名鼎鼎的 k8s。同 InfluxDB 一样,Prometheus 也有自己的数据格式,只要数据符合这种格式就能被 Prometheus 识别并写入数据库。而且 Prometheus 数据格式也是纯文本的。近期 Prometheus 技术热度高涨,有一个名为 OpenMetris 的数据协议越来越流行,它致力于让全球的指标监控有一样的数据格式,而这个数据协议就是根据 Prometheus 数据格式改的,两者 100%兼容,足以见其影响力。
9.2 Prometheus的工作模式
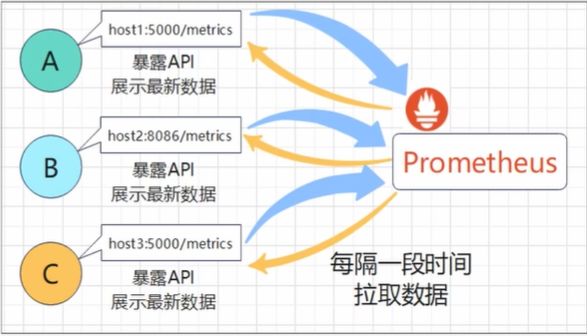
`Prometheus` 只能拉取数据,需要被监控的服务需要对外暴露一个http服务, `Prometheus`修改配置文件来定期的从这个http服务中拉数据
9.3 Prometheus 数据格式的构成
Prometheus 数据格式主要包含四个元素
- 指标名称(必需)
- 标签集(可选):标签集是一组键值对,键是标签的名称,值是具体的标签内容,而且值必须得是字符串。指标名称和标签共同组成索引。
- 值(必须):必须满足浮点数格式
- 时间戳(可选): Unix 毫秒级时间戳

格式说明:
- 第 1 个空格,将 指标名称&标签集 与 指标值 分隔开
- 第 2 个空格,将 指标值 与 Unix 时间戳 分隔开
9.4 Prometheus 的Exporter
如:监控mysql
在github上,直接搜索mysql exporter
10. 转成data_frame数据
https://blog.csdn.net/weixin_34890916/article/details/123251449
11. 查询优化
https://blog.csdn.net/weixin_38221481/article/details/128700219原创文章,作者:奋斗,如若转载,请注明出处:https://blog.ytso.com/tech/bigdata/314712.html