
- 以omm用户身份登录集群未故障的节点。执行source ${BIGDATA_HOME}/mppdb/.mppdbgs_profile命令启动环境变量。
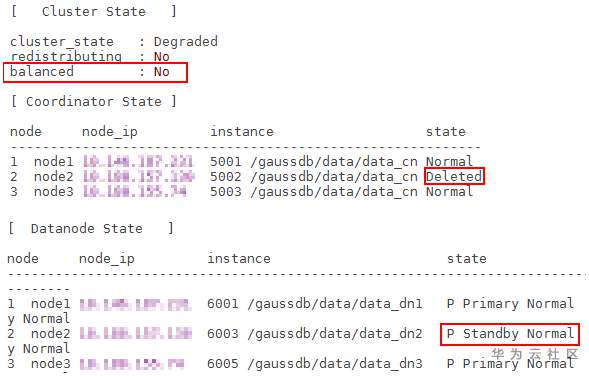
- 执行gs_om -t status --detail重新查看集群状态。此时故障服务器上整个集群的balanced状态为“No”;CN状态应该为Deleted;原始为主的DN,其状态应该为“Standby Normal”。

服务器修复到修复完成期间,DN实例的状态演进正常为:Down->Starting->Standby Normal。CN的状态演进为:Down->Deleted。
如果服务器修复后DN长时间(例如,3分钟)未切换成“Standby Normal”,请尝试使用gs_om -t start -h HOSTNAME启动故障节点上的GaussDB A进程,然后重新查询集群状态。
- 停止应用层的作业下发,准备重置DN实例状态和恢复CN。
- 停止数据库中的残留SQL。
在各CN服务器上连接数据库,执行如下命令停止残留SQL。
SELECT PG_TERMINATE_BACKEND(PID) FROM PG_STAT_ACTIVITY WHERE STATE='active' AND QUERY NOT LIKE '%TERMINATE%' AND APPLICATION_NAME NOT IN('JobScheduler','workload','WorkloadMonitor','cm_agent');返回t表示有残留SQL被停止。
pg_terminate_backend ---------------------- t (1 row)
- 执行命令gs_om -t switch --reset重置DN实例状态。
switch为维护操作:确保集群状态正常,所有业务结束,并使用pgxc_get_senders_catchup_time()函数查询无主备追赶后,再进行switch操作。
执行gs_om -t status --detail重新查看集群状态。集群balanced状态应该已恢复为“Yes”。如果未恢复,请尝试再次重置,并查看状态。依然无法恢复balanced状态时,可以尝试通过查看OM日志进行问题定位,并联系华为技术工程师协助处理。
- 执行gs_replace命令尝试修复故障服务器上的CN实例。其中node2为故障服务器的hostname,请根据实际替换。关于故障实例修复的更多信息请参考修复MPPDBServer实例。
执行如下命令进行实例配置。
gs_replace -t config -h node2
您会看到异常CN先被删除然后被重新配置。这个过程中CN状态会由“Deleted”变为“Down”。
Fixing ETCD instances. Node is not installed etcd. Fixing all the CMAgents instances. There are [0] CMAgents need to be repaired in cluster. Configuring replacement instances. Successfully configured replacement instances. Successfully fixed all the CMAgents instances. Configuring Waiting for promote peer instances. . Successfully upgraded standby instances.Deleting failed CN from pgxc_node.Successfully deleted failed CN from pgxc_node.Dumping CN files from the Normal CN.Successfully dumped CN files from the Normal CN.Configuring replacement instances.Successfully configured replacement instances.Setting the SCTP. Successfully set the SCTP. Configuration succeeded.
执行如下命令重启实例。这个过程中CN状态会由“Down”变为“Normal”。
gs_replace -t start -h node2
Starting. ====================================================================== Successfully started instance process. Waiting to become Normal. ====================================================================== . ====================================================================== Start succeeded on all nodes. Start succeeded.
- 重新启动应用层的作业下发。
原创文章,作者:奋斗,如若转载,请注明出处:https://blog.ytso.com/tech/bigdata/316499.html