
自动化运维建设正在成为很多企业当前或者下一阶段的建设目标。这其中,很关键的一个组成部分就是配置管理数据库(CMDB)。CMDB能否建设好是自动化运维建设能否真正落地的一个非常关键的因素。
大家都在谈:CMDB建设要面向消费,面向应用,要实现可回写,要保证数据一致性、完整性和准确性,要实现配置的生命周期管理……
这些都没错,是CMDB建设中的关键点和重要目标。但是,究竟该如何做才能实现上述目标呢?该如何控制,才能确保真实效果没有与目标偏离呢?我们在这篇文章中一起探讨下。以下文章仅代表个人观点,难免偏颇和愚见,欢迎各位留言,一起讨论。
本文的大纲:
- 好的CMDB建设:定义消费场景在先
- 好的CMDB建设:以应用为中心,控制好范围和颗粒度
- 好的CMDB建设:打通运维流程,实现数据读写闭环
- 好的CMDB建设:应该集成统一监控
- 好的CMDB建设:自动采集,足够灵活
本篇文章中用到的几个术语统一解释如下:


一、定义消费场景在先
脱离CMDB数据使用场景,上来就要把企业全部的IT对象、属性和关系全部囊括进CMDB的CMDB建设,都是耍流氓。
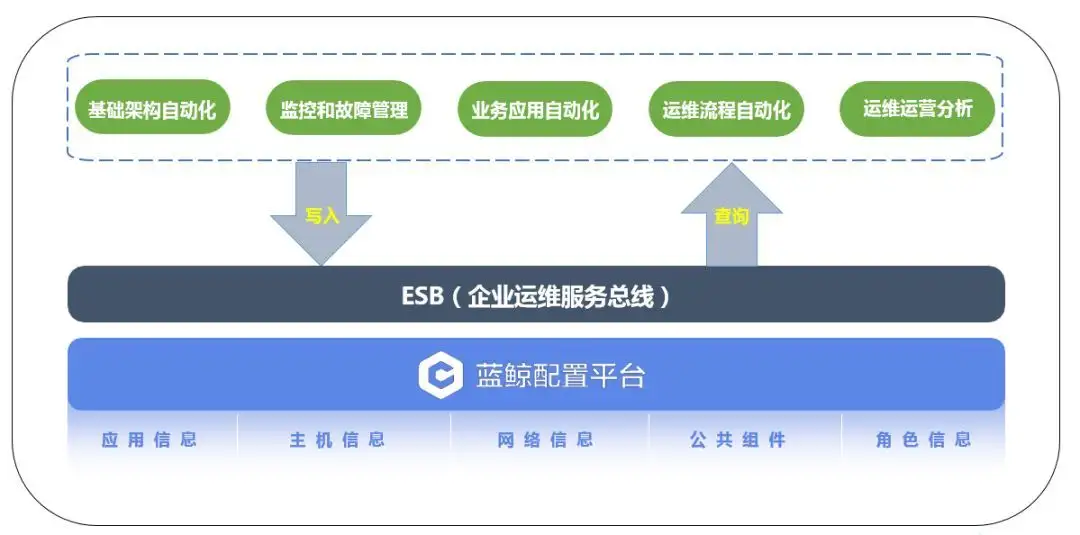
各种自动化运维操作是场景:
- 比如新服务和应用的自动化发布,需要知道当前可用的基础资源有哪些;
IT环境监控和告警也是场景:
- 比如针对某台数据库服务器性能告警,需要判断此服务器所属业务和集群;
ITSM流程对接也是场景:
- 比如ITSM的变更流程需要从CMDB中读取配置对象和数据,以便执行变更;
资产管理和展示也是场景:
- 比如将企业的IT资产分类展示和查询;
……
配置管理的消费场景很多,每个企业都需要梳理出自己真正需要的场景;并且这种梳理应该是基于企业的日常运维工作以及下一步运维提升的目标来制定,而不应离地三尺,肆意空想。

切忌好高骛远,一味求全;否则CMDB建设范围和颗粒度极易失去控制;就像一匹脱缰的野马在茫茫大草原毫无目标的肆意驰骋。
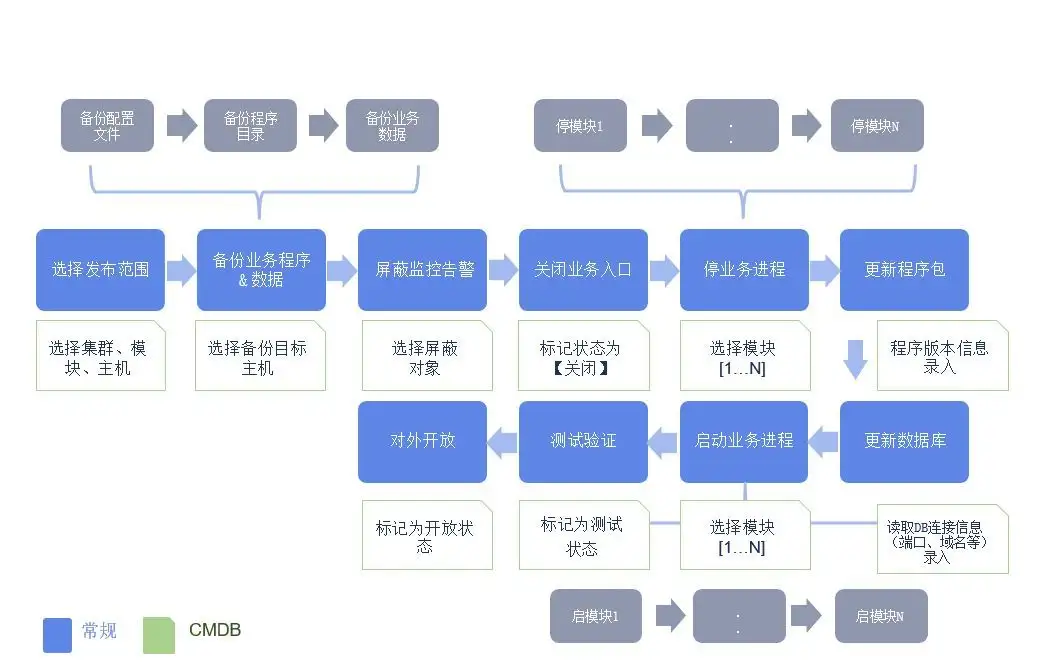
例如,以下是一个企业的一个业务发布场景,该场景通过自动化运维平台实现流程的自动化操作。过程中,自动化操作步骤与CMDB的交互过程如下图所示:
在确定了消费场景的基础上:
- 才能确定我们需要在CMDB中涵盖哪些应用、业务、CI、CI项、关联关系等;
- 才能确保我们录入的数据最终是能在场景中得到使用和消费的,而不是静止的死数据;
- 一旦数据被使用起来,并且通过工具和流程将实现配置数据的读写闭环之后,数据的一致性、完整性和准确性是必然的结果。
朱熹诗云:“问渠那得清如许,为有源头活水来”;一旦数据是能够消费和使用起来,确保数据的一致性、完整性和准确性相对来说就是比较简单的了。
二、以应用为中心,控制好范围和颗粒度
在确定好CMDB的数据消费场景基础之上,接下来可以考虑着手进行“设计模型蓝图”的规划了。
在蓝图规划中,我们主要考虑三件事情:模型(CI)、属性(CI项)、关联关系。
这三者的出发点和落脚点都应该是应用系统或者业务系统。还记得上面那匹脱缰的野马吗?我们用应用或者业务系统这个套马杆,把这匹马拉回我们的轨道上来。
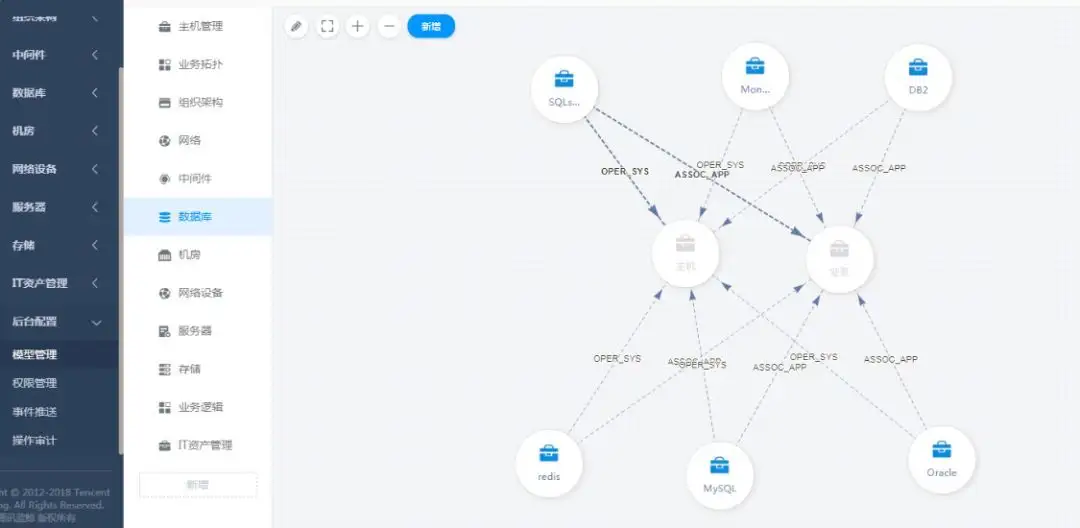
如下图所示:手机银行是某个银行的应用系统之一,那么与这个应用相关的全部对象都会被组织在这应用的下方。
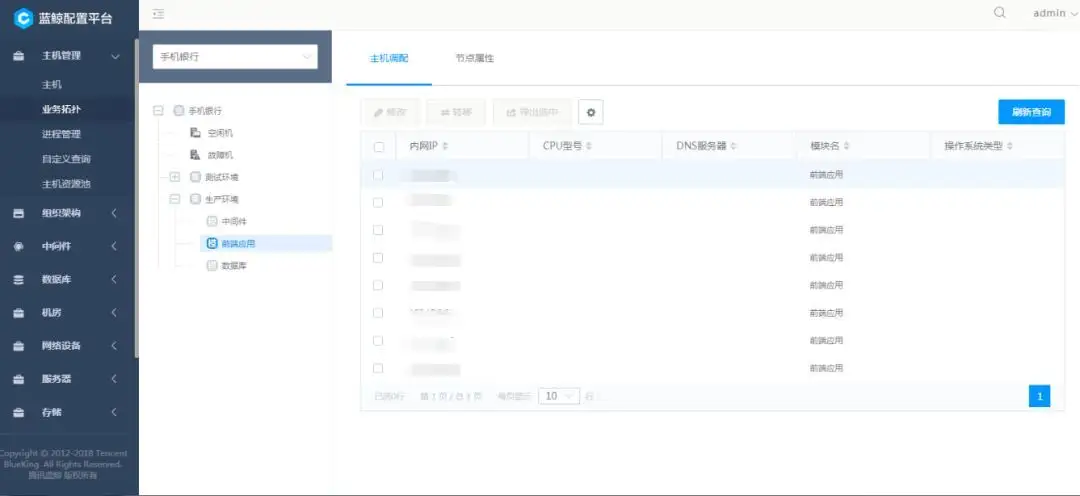
在“手机银行”这个应用下方以层级的方式逐级展开各层资源:
- 比如应用本身可能是不同群集环境的:生产群集、测试群集、预发布群集等;也可能是分不同区域群集的:华东区域、华南区域、西北区域等;
- 每个群集内部又分为不同的模块:前端web服务模块、中间件模块、数据库模块、其他组件模块等;
- 每个模块内部可能是就具体的虚拟机、物理服务器、容器、公有云、私有云、混合云等基础资源,以及中间件应用、数据库应用、web应用、手机银行应用本身的进程和服务等上层业务逻辑资源;
- 每个资源对象本身都有自己的配置信息,对象与对象之间有着各种各样的关联关系;
到这里,我们就把“手机银行”这个应用下方需要的模型(CI)、属性(CI项)、关联关系等全部梳理清楚了。
其他的应用大体过程类似。出应用或者业务系统出发,最终回归到应用和业务系统。
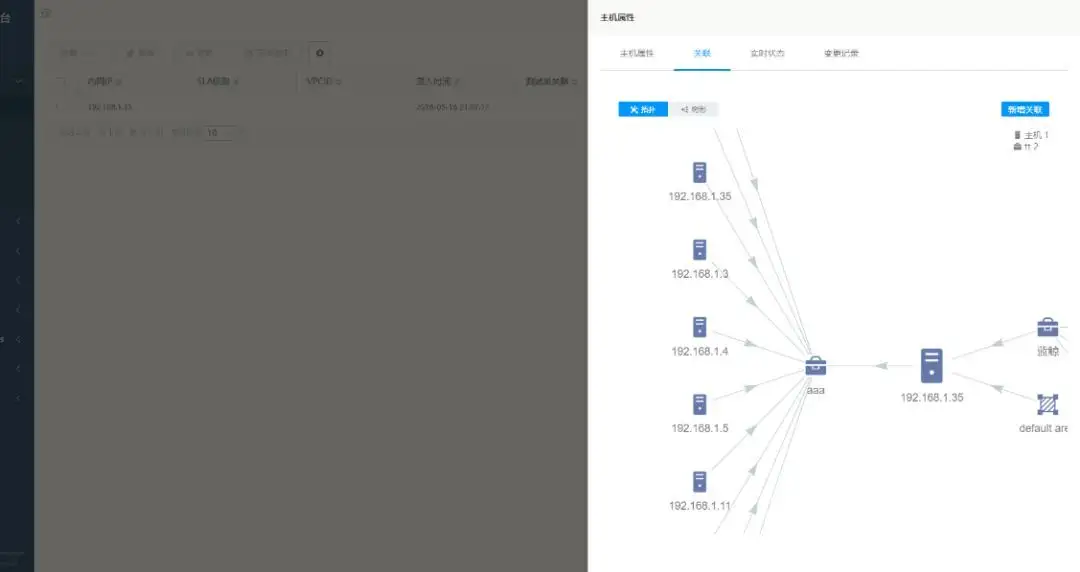
三、打通运维流程,实现数据读写闭环
很多企业里已经有了自己的运维工单流,可能是ITIL范式的,也可能是非ITIL范式的;无论哪种,在可能的情况下,最好能将CMDB与运维流程本身集成和打通,这样CMDB的数据一致性、准确性和完整性才有了保障。
与流程平台对接的过程,事实上也是将CMDB配置生命周期管理纳入企业统一的运维流程管理的过程。所谓实现“配置的全生命周期管理”并不是要为配置管理专门生造一个流程,IT对象的生命周期管理过程中本身就涵盖了配置管理;配置管理的生命周期是随着IT对象生命周期而运行的,不存在单独的配置管理生命周期。(ITIL中的配置管理流程事实上是与对象的生命周期管理紧密关联的,是变更管理和事件管理等其他流程的结果,还不是主动发起方。)
所以,IT对象和资源生命周期管理的好的企业,往往配置信息也能管理的比较好。而IT对象和资源生命周期管理的比较混乱的公司,配置信息管不好简直是一定的,并且在这种情况下关键是要把各个IT对象和资源生命周期管理梳理清楚,而不是脚痛医脚,只考虑配置的生命周期管理如何建立。
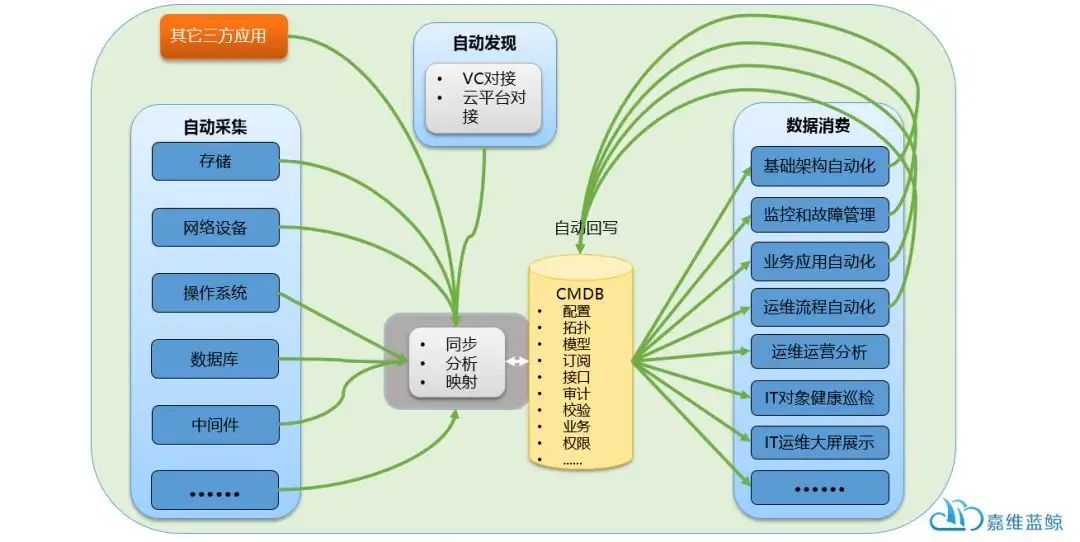
这里面对接的情况就稍微复杂一些:
- 可能是企业已有ITSM系统或者即将上ITSM系统,ITSM有自己的CMDB,自动化运维的CMDB需要与已有的CMDB做对接和集成;
- 可能是企业已有ITSM系统或者即将上ITSM系统,系统自带CMDB,企业准备后续停用ITSM的CMDB或者不用ITSM的CMDB,统一用自动化运维的CMDB作为数据源。
每种情况,我们都需要考虑清楚如果将新建的自动化运维的CMDB与传统的流程系统对接和集成,实现统一的数据消费、回写和闭环流程。
在对接流程这个层面,出发点和落脚点依然是实用主义;并不是一股脑要实现全部流程和CMDB的对接和集成;
可以考虑先把日常使用最多、同时会更改IT环境的配置信息的部分流程对接到CMDB,先解决最大的麻烦点和成本点;
后续再逐步将涉及到CMDB配置变更的流程对接到CMDB;至于某些流程本身压根不需要CMDB参与的,可以暂时不用考虑对接。

除了流程对于CMDB信息的读写之外,还有另外一个方向的数据传递:配置的变化需要及时通知管理员,并且最好能够自动启动一个处理工单。这就要求CMDB本身具备事件推送能力。
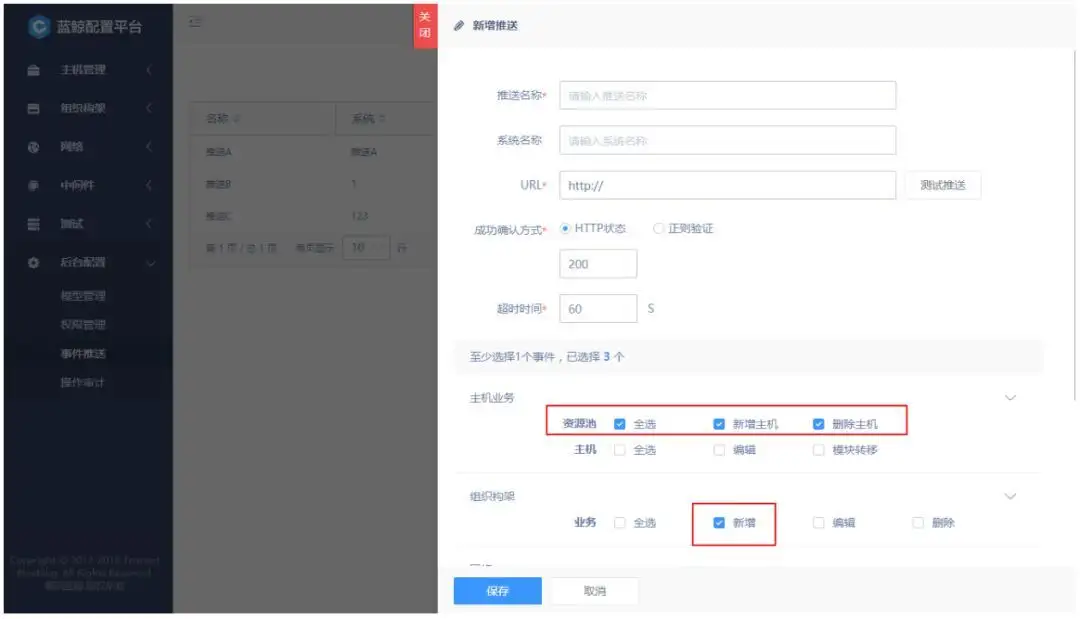
在这一个层次,技术难度是其次的;考虑清楚整个逻辑链条、数据闭环、双方对接方式、未来流程和配置的持续扩展才是难点和重点,是需要仔细而慎重的去考虑的。
四、应该集成统一监控
监控在以往和自动化运维包括CMDB等的关系好像不大。两者更多的是分离的两个系统:自动化运维以CMDB为基础,实现运维操作的自动化执行和配置数据的统一读写;而监控则依赖自身的采集器和接入的采集对象,实现对象的运行信息、性能信息和安全信息等的统一采集、分析和告警服务。
然后,在一个更高层面的企业IT运维自动化运维蓝图中,统一监控和自动化运维(包括CMDB)两者应该是辩证统一的。
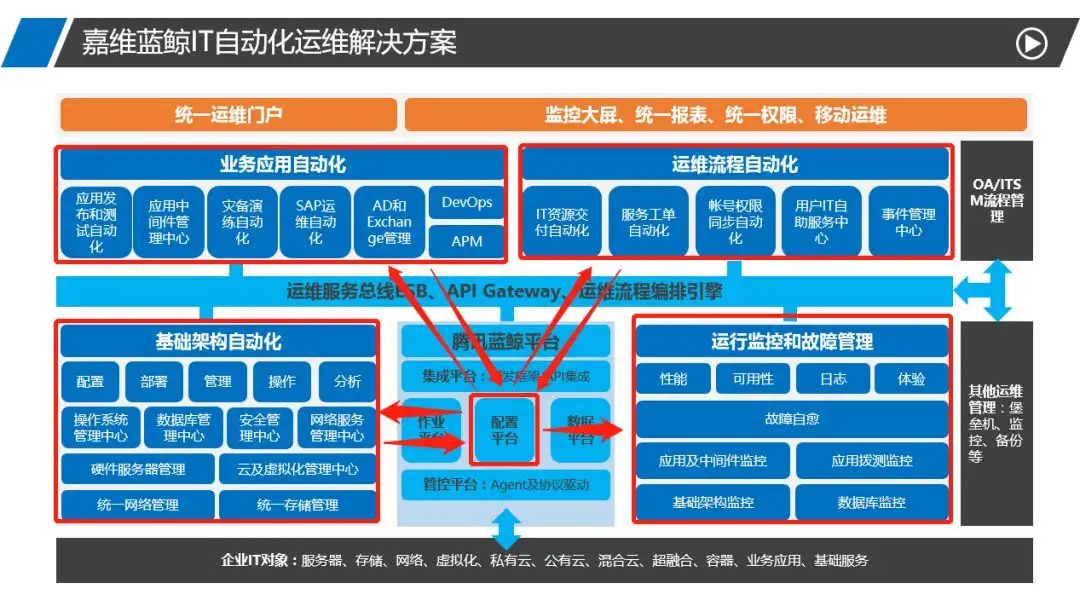
在与监控对接和集成中,我们分为这么几个层面来考虑:
1、数据采集
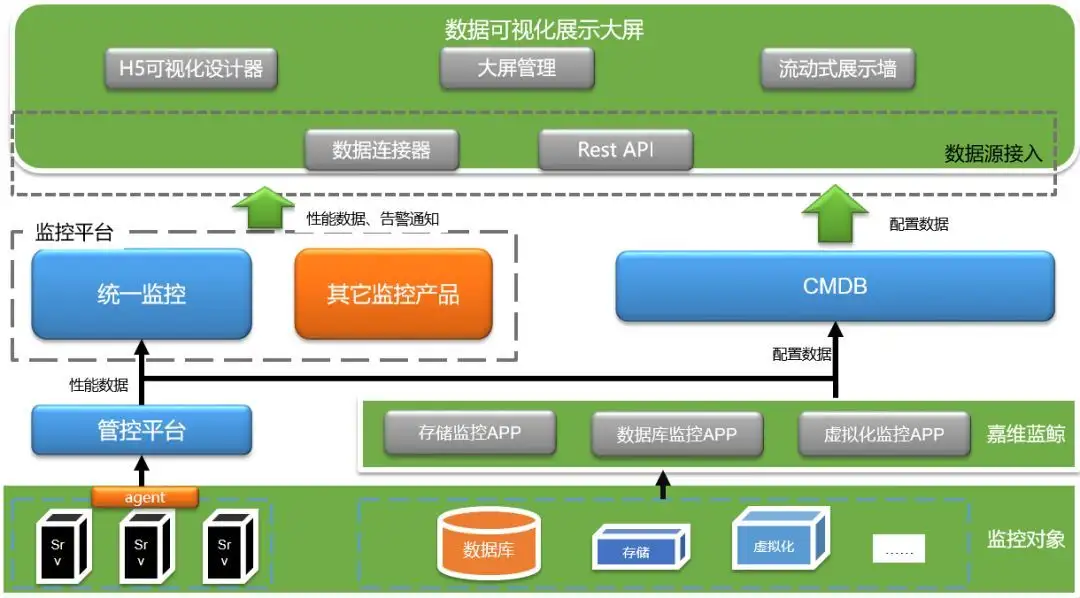
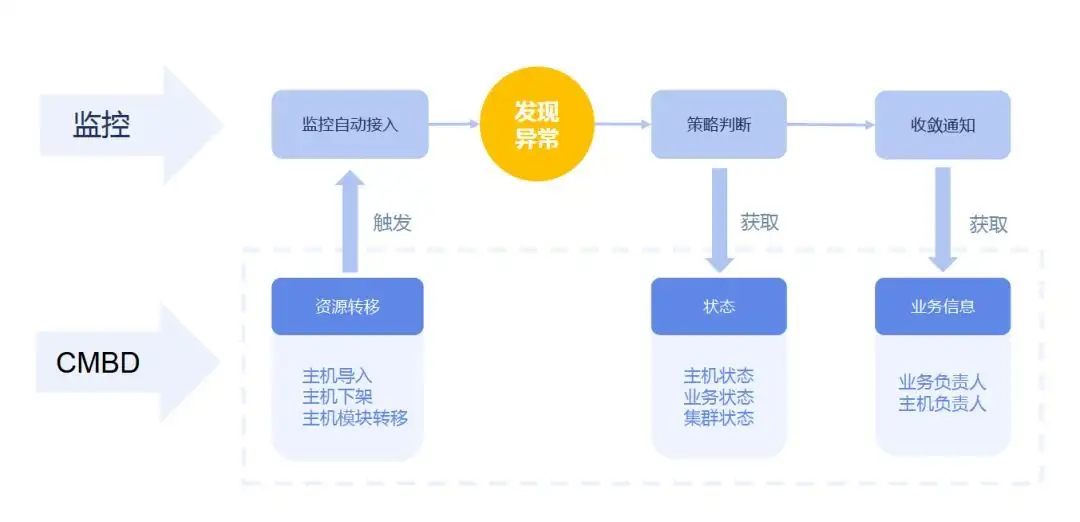
在数据采集阶段,仅仅采集对象的运行数据、性能数据和安全数据显然是不够的,还需要知道这些对象具体位于哪个应用或者业务、哪个群集、哪个模块下面:某个数据如果异常会影响到具体的哪个业务或者应用系统?这种影响的范围有多大?重不重要?需要采取何种的处置措施来应对。
这些信息,需要联动CMDB,读取相应业务或者应用下的具体对象、配置信息和关联关系才能获取;
当然,这些信息可以另外单独在监控中实现,但事实上这个活CMDB就能干,并且能干的很好,又何苦再在监控系统中重复建设呢?
2、数据分析与告警服务
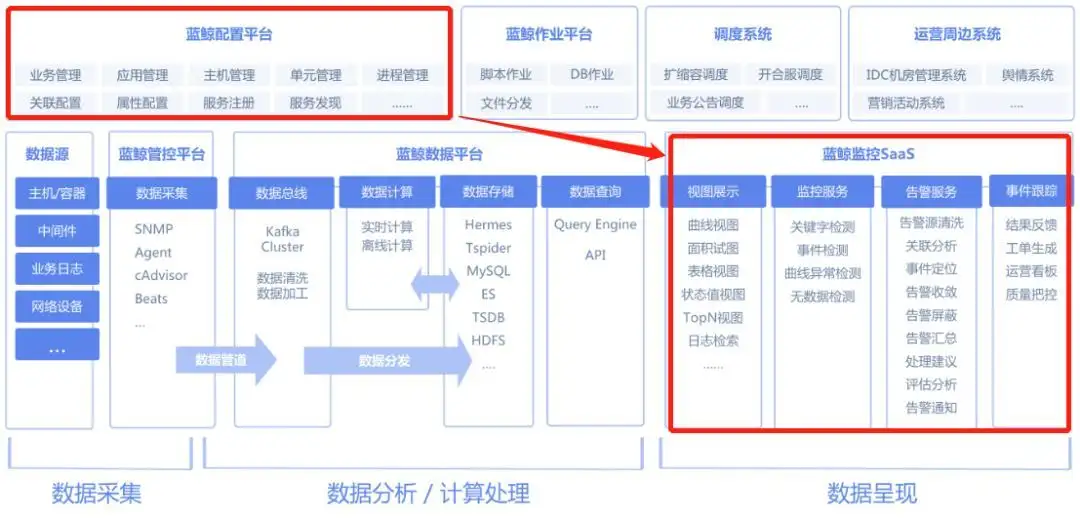
当监控系统触发某个告警之后,如果单独将某个对象的某个指标异常报告给管理员,此时管理员会怎么办呢?
一般情况是:凭记忆或者手动打开自己的某个Excel表格或者登录某个数据极可能不太准确的旧的配置管理数据软件,查询产生这个告警的具体IT对象实例是谁?哪个业务或者应用下面的?应用本身重不重要?测试环境还是生产环境?然后再决定怎么处理。
与CMDB集成之后,监控就能在把告警服务通告出来的同时,直接体现上述信息。
这仅仅是第一步,事实上,监控与CMDB集成之后,能够做的更多:
- 由于集成了CMDB,监控系统事实上能够获取某个应用下的全部对象、配置信息和关联关系,具备这个应用的全部逻辑和物理对象视图,因此具备了实现高级统一监控的坚实基础;
- 在告警服务层面能够实现诸如:告警源清洗、关联分析、事件定位、告警收敛、告警屏蔽、告警汇总、处理建议、评估分析、告警通知等高级监控服务;
- 在实现了我们前述的对接运维流程的基础上,还能够实现:某项告警直接驱动工单生成,并通过应用、邮件、短信和电话等通知到相关责任人处理。实现告警工单的自动化生成和处理。
3、故障自动处理
监控的目的是什么?
及时发现甚至提前预测可能出现的故障,以便及时处理,尽可能减少对业务的影响。简而言之就是预测故障(很难,大家整体处于探索阶段)、发现故障、处理故障、保证业务或者应用。
因此,高级的监控系统需要具备故障自动处理模块,以便监控报告故障之后能够及时、自动化处理故障,将故障的影响范围和程度降到最低。
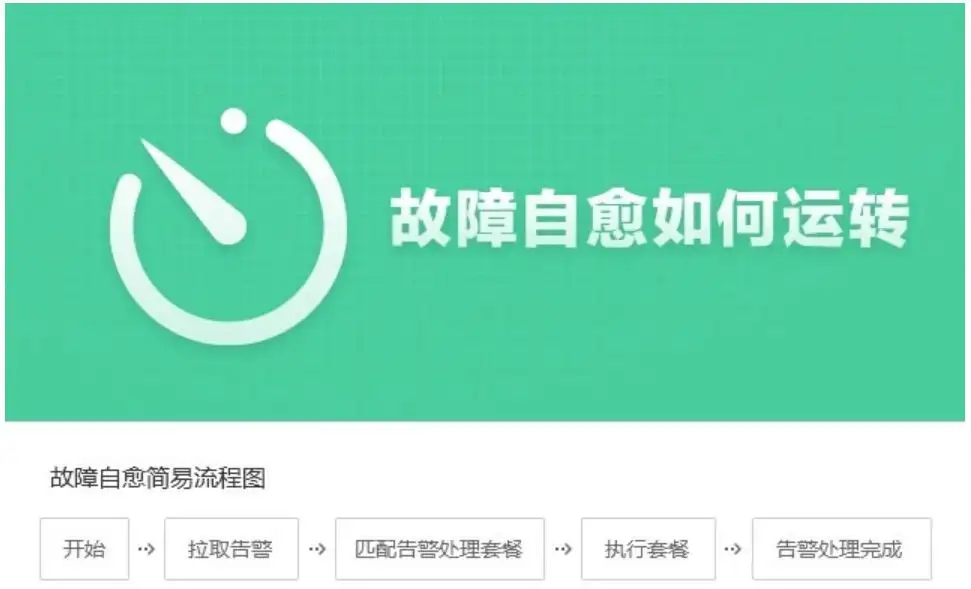
而故障的自动处理事实上依然需要依赖自动化运维平台的功能和组件,比如脚本执行和文件分发编排、标准运维流程编排等等;而自动化运维的基础是CMDB,对吧?所有这些操作都需要知晓对象、配置信息和关联关系。所以,在故障自动处理阶段,依然需要CMDB介入,提供应用下的完整配置信息和关联关系。
综上:监控处理过程,包括数据采集、数据分析和告警服务、故障自动处理等都需要与CMDB紧密结合,两者共同构建更为强大和务实的监控能力。
五、自动采集,足够灵活
1、配置数据的自动采集和维护、批量导入和导出是好的CMDB建设的基本要求。
想象一下,如果大部分配置数据都要手动输入和维护,这是一件多么痛苦的事情。
因此需要CMDB本身能够将绝大部分的配置信息实现自动化采集和维护,减轻维护工作量,提升效率和准确性。

2、能够支持CI、CI项、关联关系的灵活自定义
由于每个企业的IT环境和运维流程都不一样,CMDB在每个企业落地的时候在最佳实践的框架内,内容和形式注定是个性化的。这就要求CMDB本身具备足够的灵活性,使得企业能够根据自己的情况自定义CI、CI项和关联关系。
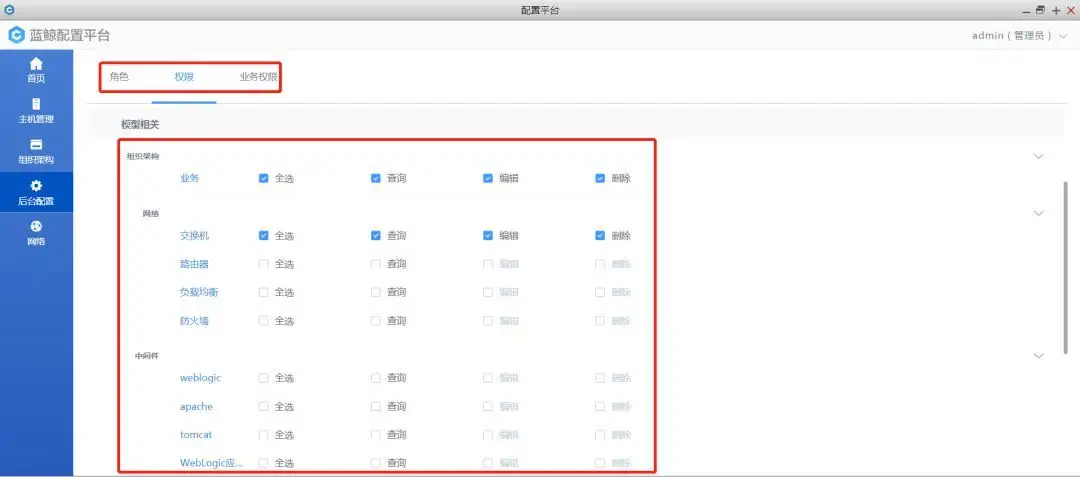
3、严格而灵活的权限控制
由于CMDB中存储着全部应用和对象资源的配置信息,因此权限控制就显得尤为重要。CMDB本身需要能够实现比较细的、比较灵活的CMDB权限管理。

4、 CMDB需要具备足够开放的API
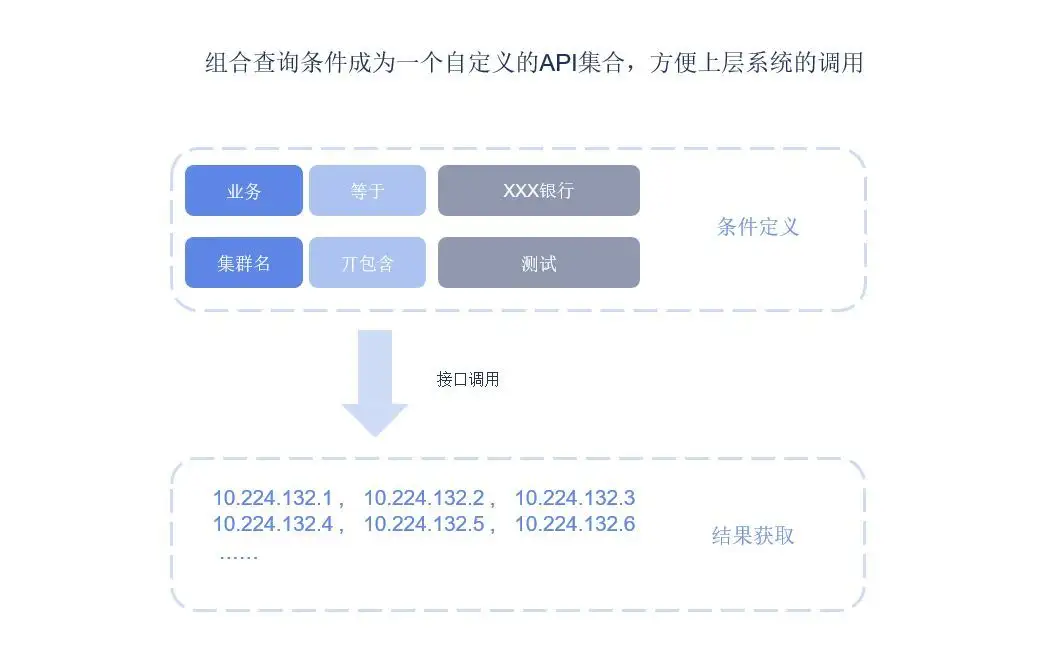
由于CMDB本身是一个基础功能组件,本身需要对外提供数据并接受数据的写入,因此需要CMDB本身提供足够丰富的API接口。这一点在复杂的环境,以及考虑到企业未来IT环境和管理的扩展的情况下,就显得尤为重要。
例如,很多企业有大屏系统,并需要把一些关键业务和应用在大屏系统中集中展示,这就需要CMDB能提供相应的接口和服务。
5、支持审计,并能支持海量跨云环境
支持审计这点,不必多说。稍微上规模,IT管理有一定规范的企业都会如此要求。
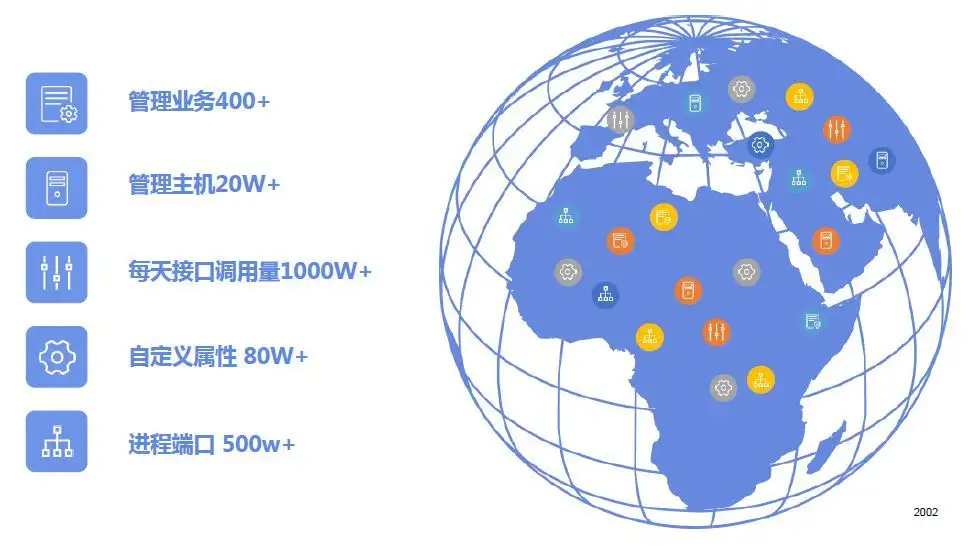
支持海量环境这点非常重要。完全可以预计,随着企业的发展和IT规模的持续扩展,CMDB中入库的对象和数据会越来越多。因此要求CMDB本身具备纳管海量配置的能力,并且经受过实体的业务环境的检测。
总结一下,好的CMDB建设需要:
- 定义消费场景在先
- 以应用为中心,控制好范围和颗粒度
- 打通运维流程,实现数据读写闭环
- 应该集成统一监控
- 自动采集,足够灵活
以上是个人对于好的CMDB建设在企业落地的时候应该重点考虑的一些要素。能力所限,偏颇和愚见难免。欢迎各位同学在评论区留言探讨。
原创文章,作者:奋斗,如若转载,请注明出处:https://blog.ytso.com/tech/aiops/303322.html